






1、YOLOv11介绍
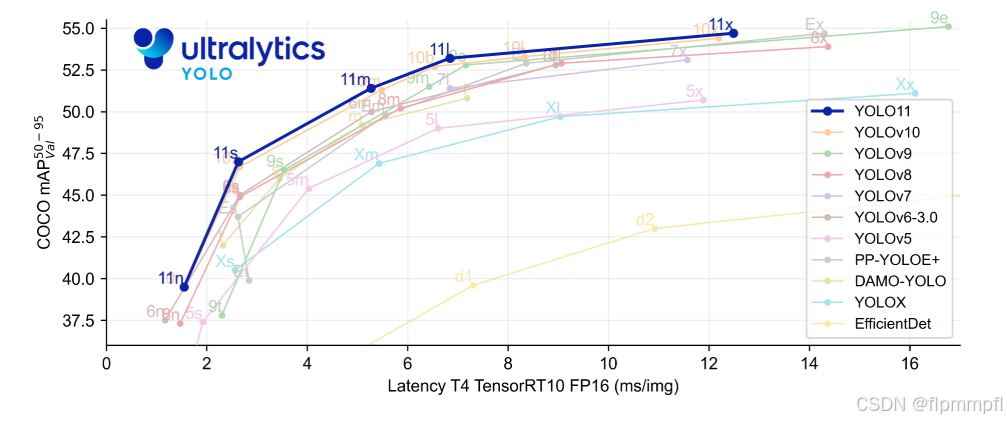
YOLOv11在以前 YOLO 版本的成功基础上,引入了C3k2和C2PSA两个全新模块,并延续了YOLOv10无NMS的训练策略,实现了端到端的目标检测能力,进一步提高了性能和灵活性。YOLOv11与YOLOv8一致提供了五个不同尺度大小的网络,仅在网络尺度上有所差异。
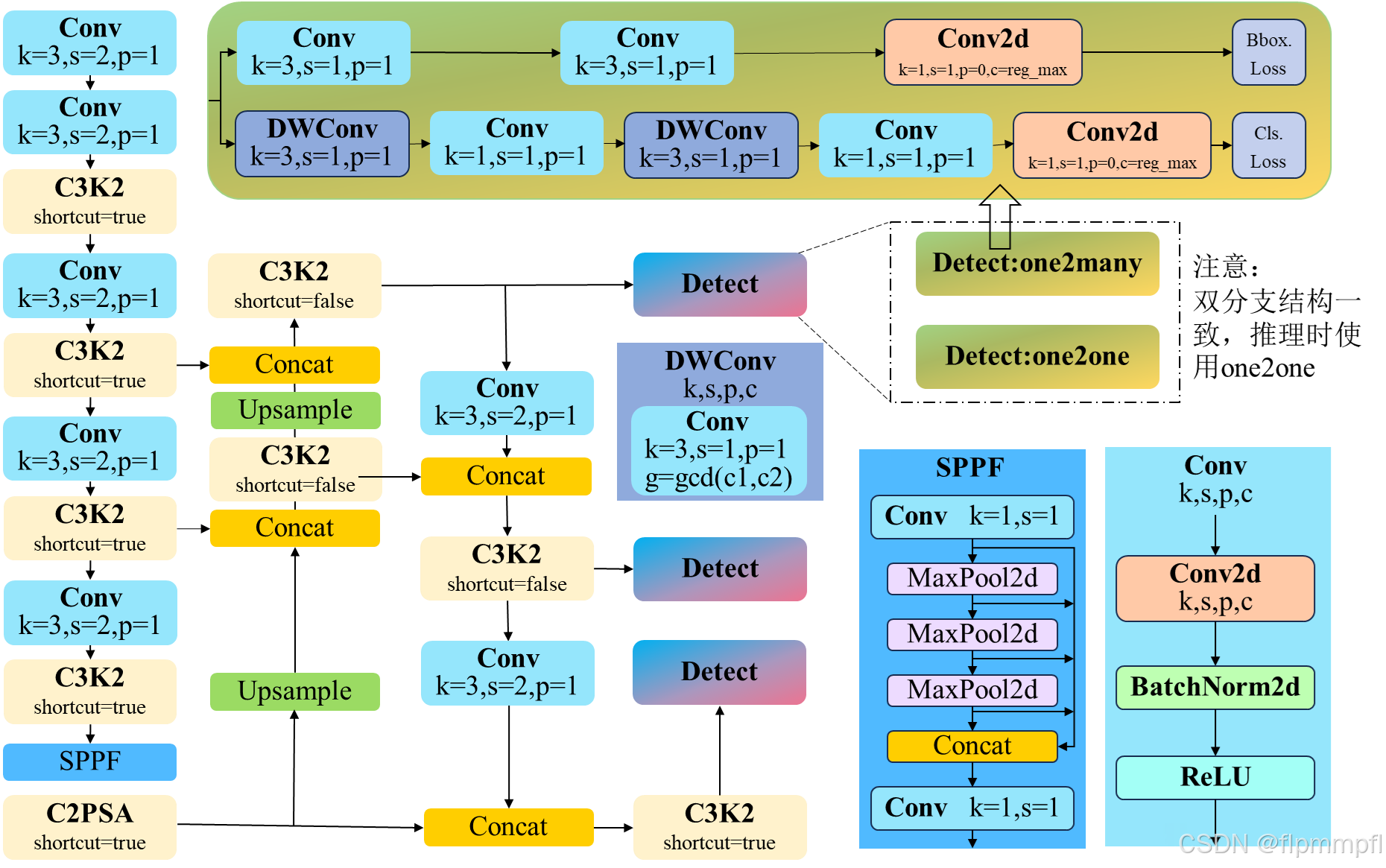
2、yolov11模型图
3、前提所需
anaconda3、pycharm下载完成(最好不要最新版本,也不要太旧,本人使用2021.3)
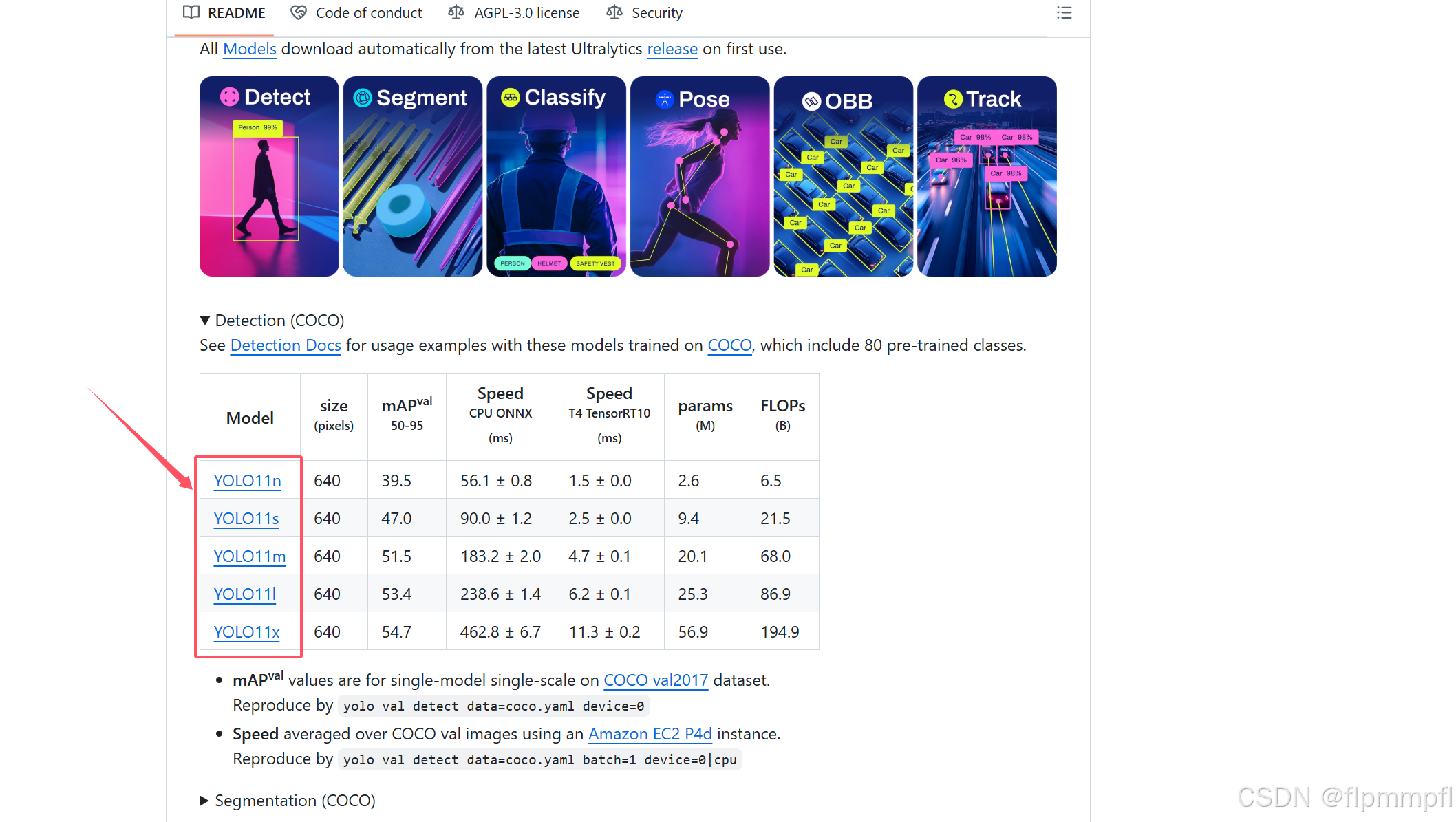
4、yolov11模型、权重下载
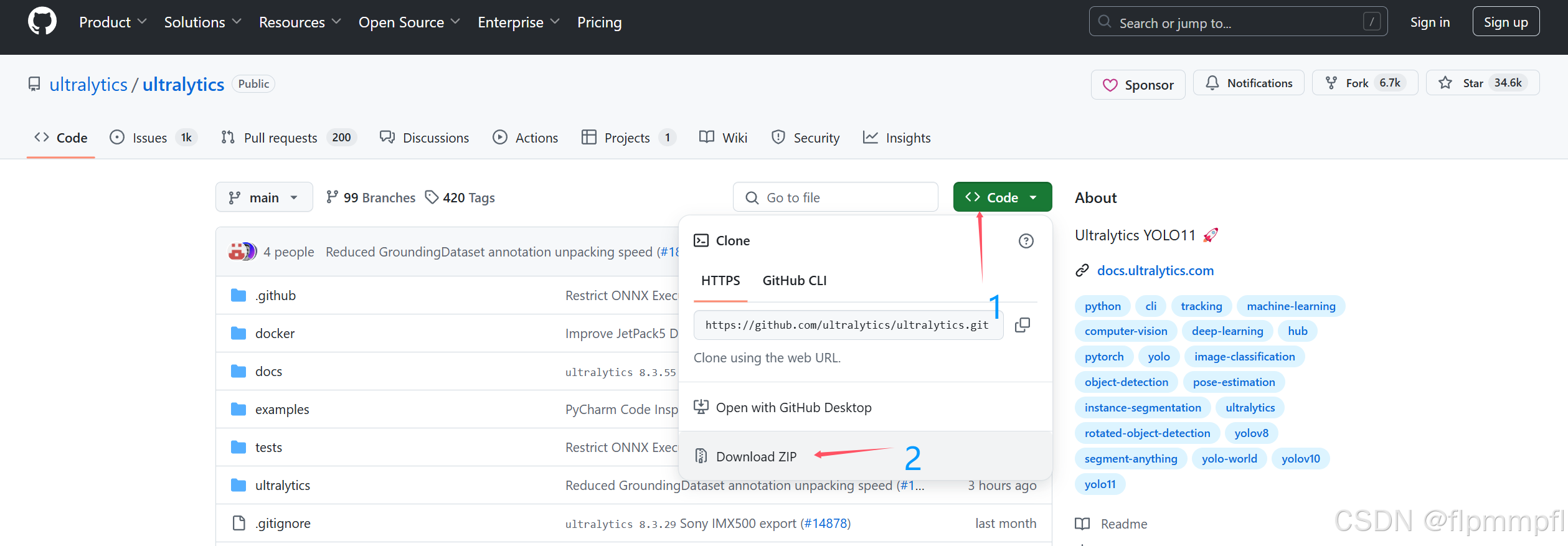
1.模型下载:github模型下载地址
2.模型权重下载(非必须):下载所需的
直接放yolov11文件夹根目录下
5、环境配置
5.1.下载yolov11所需虚拟环境
打开anaconda prompt
cd进入你下载的yolov11文件夹中

创建yolov11环境:输入 conda create -n yolov11(代表环境名称)python=3.9(使用Python的版本),按y+回车

无脑复制
conda create -n yolov11 python=3.9
进入你刚安装的yolov11环境:conda activate yolov11(你的环境名称)
无脑复制
conda activate yolov11
进入后()会变成你环境名称 (判断是否安装成功)

5.2.下载CUDA(GPU所需)
cuda是连接GPU和模型训练的桥梁,pytorch是进入桥梁那段上坡的路(CPU训练慢,GPU快还好)(最好选择在虚拟环境安装,以下介绍为虚拟机安装过程)
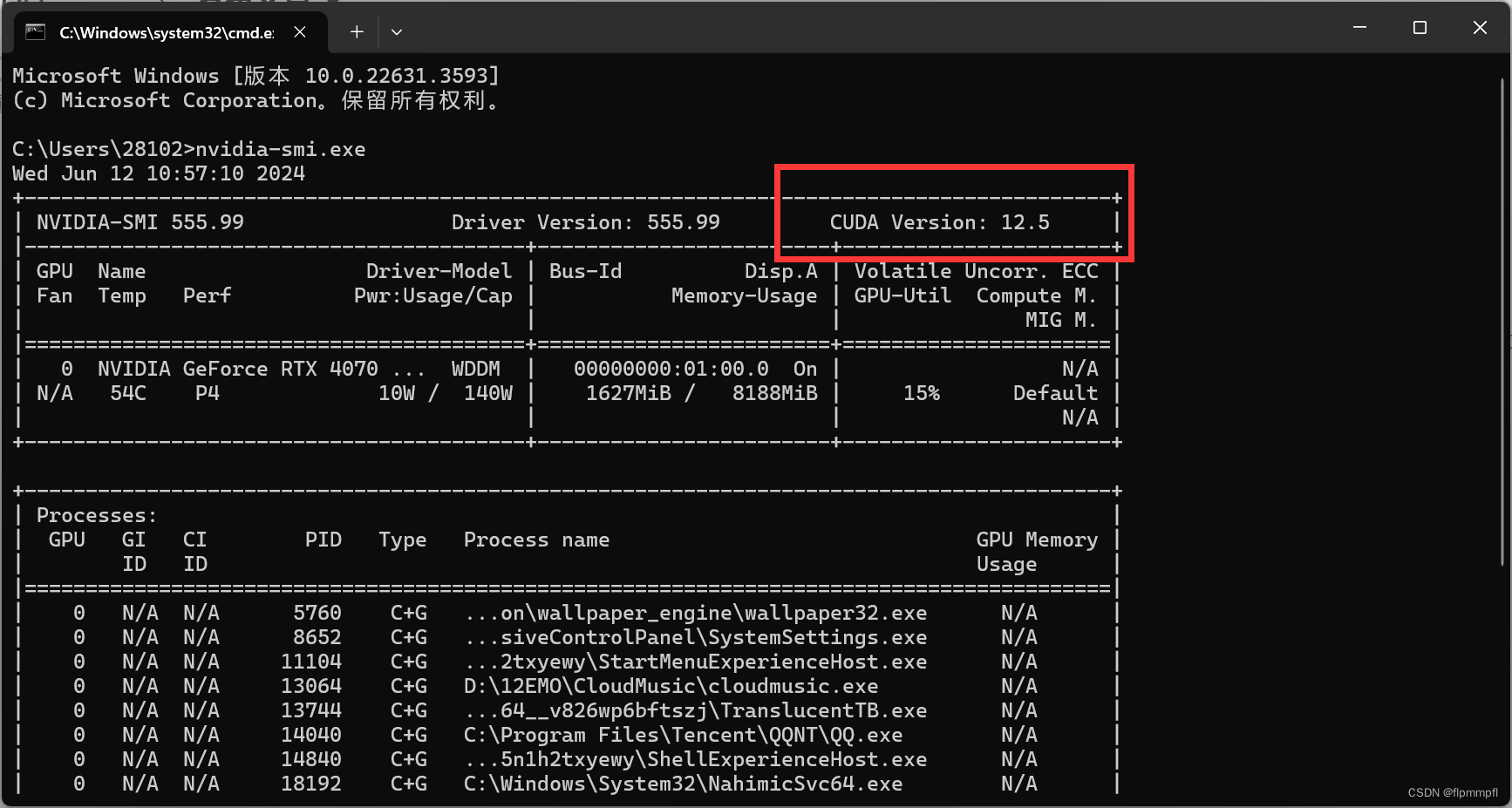
查看cuda最高支持版本,win+R,输入cmd,打开命令窗口,输入nvidia-smi.exe,红框位置为最大可支持安装版本

无脑复制
conda install cudatoolkit=11.7
安装后的结果
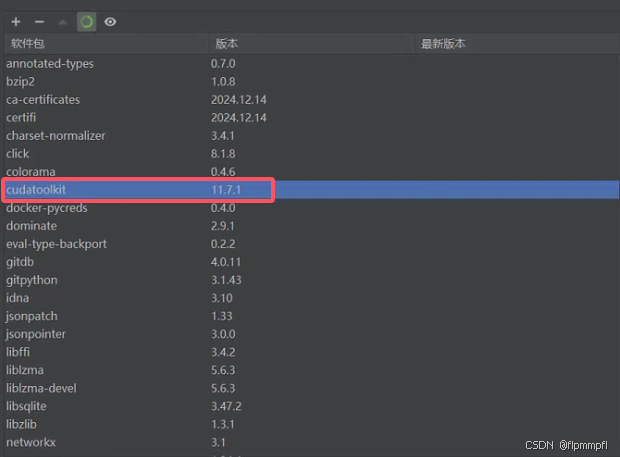
5.3.下载pytorch(GPU所需)
cuda是连接GPU和模型训练的桥梁,pytorch是进入桥梁那段上坡的路(pytorch库必须和cuda版本匹配)(其实这个在之前下载yolov10虚拟环境已经下载过了,但是为了确保你的pytorch版本和CUDA版本一致,所以这里在从下一遍以确保环境没有问题)

无脑复制(CUDA 11.7)
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia安装后的结果
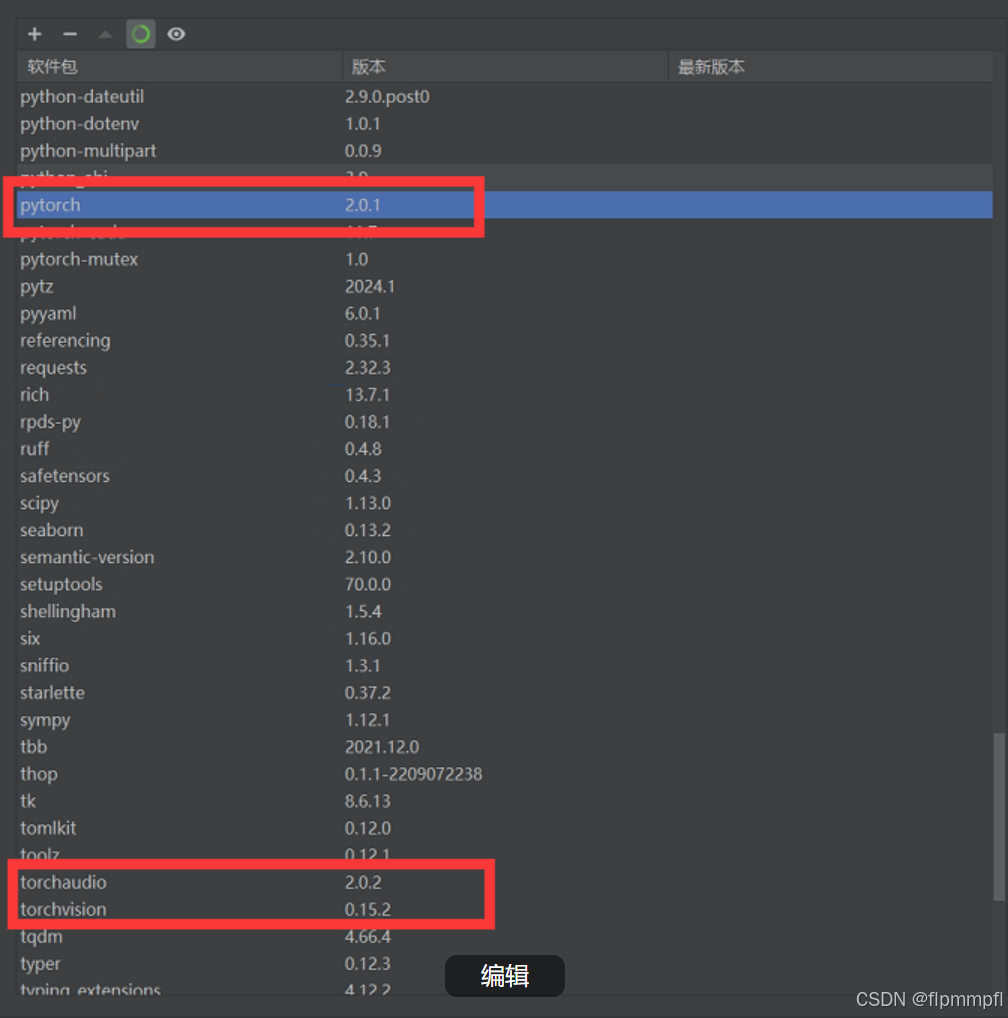
或者去pytorch官网查找(只是教你怎么去找你所下载CUDA对应的pytorch,以防下载的别的版本的CUDA)(例如CUDA=11.8),我之前写过yolov10,其中就有,这边就直接引用了(yolov10)
5.4.下载yolov10依赖库
ultralytics团队把所有的包都已经封装好了
无脑复制
pip install ultralytics只要中间不报错即为下载成功
6、pycharm添加解释器
点击文件、设置
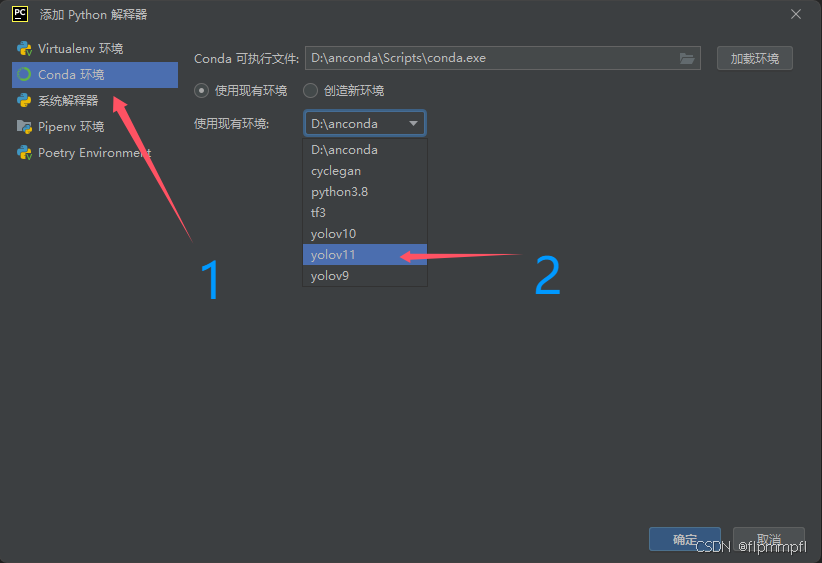
找到python解释器,添加新的解释器
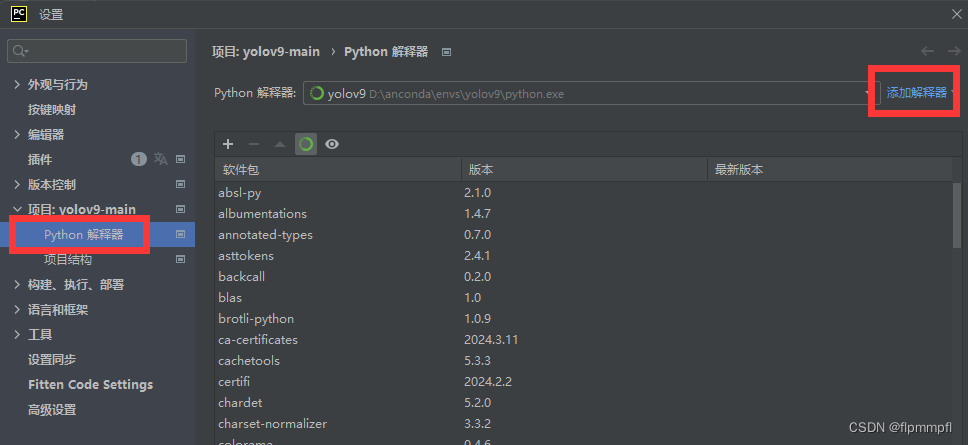
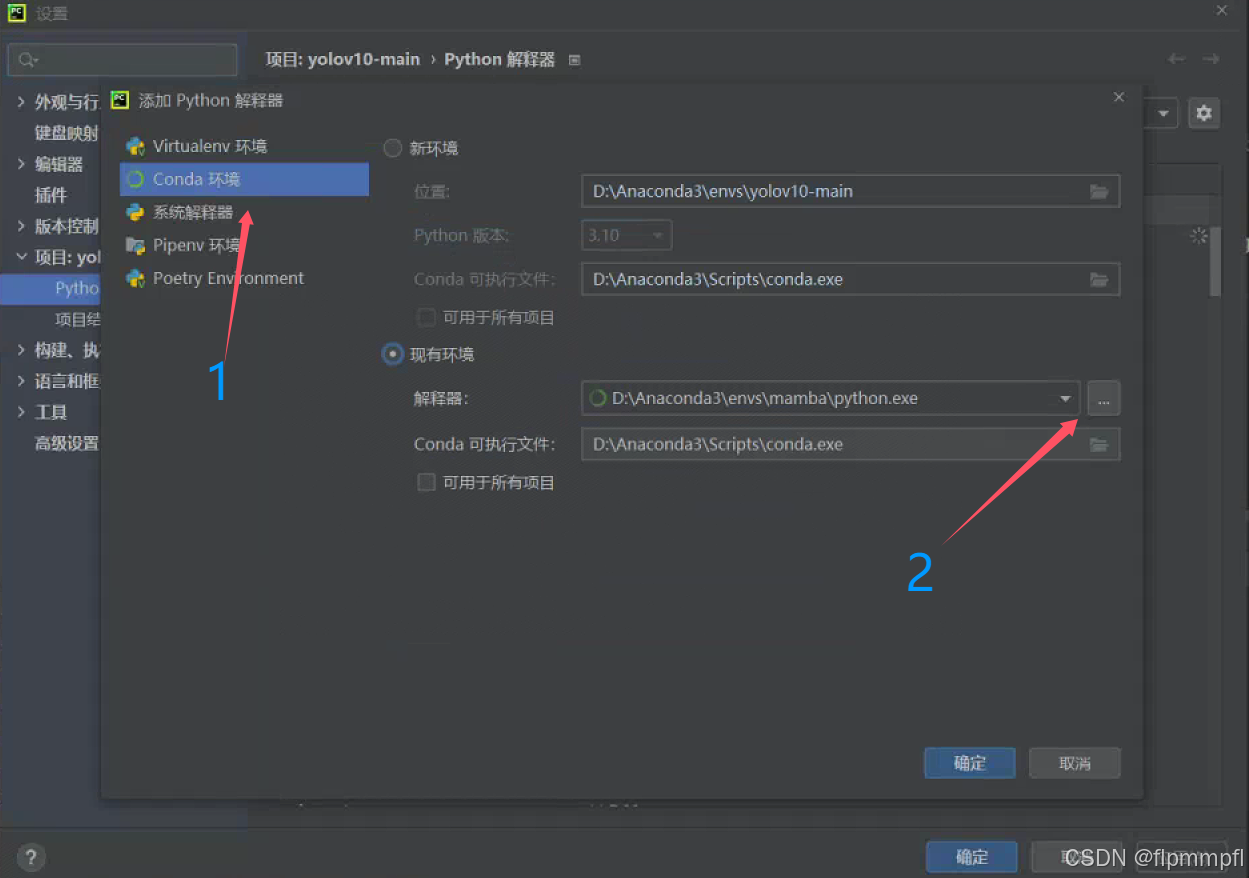
找到conda环境、使用现有环境,找到你前面配置的yolov11(环境名称)
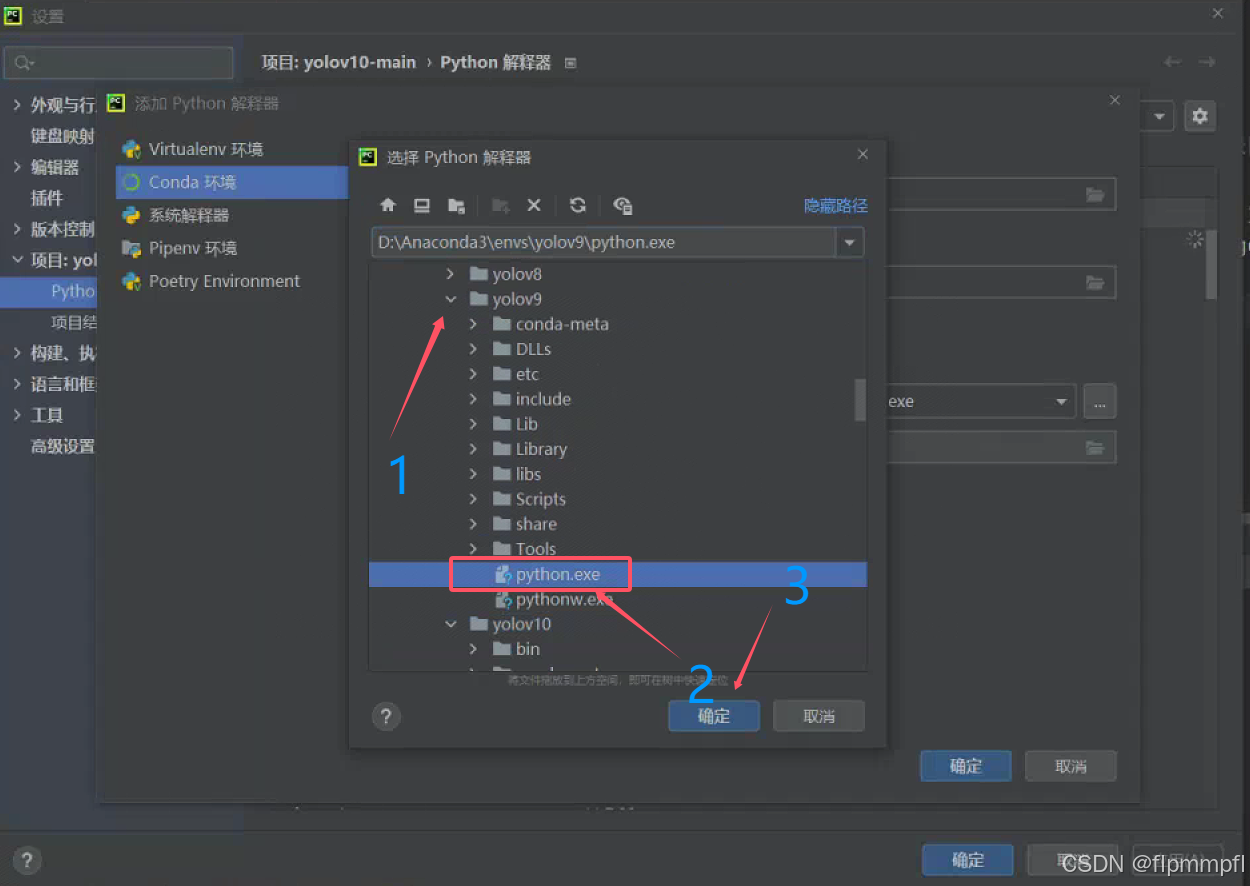
还有老版的pycharm,使用应该找Anaconda3\envs\yolov11(环境名称)\python.exe
(用yolov9举例)
点击应用
 7、数据集制作
7、数据集制作
这边去看yolov9的数据集制作就可以,方法相同
YOLOv9最详细教程(训练自己数据集、结构介绍、重点代码讲解)(草履虫都能看懂系列)-CSDN博客
8、训练
训练有很多种训练方式,我挑选的是我认为最为简单的一种,即修改default.yaml文件,然后在终端调用
default.yaml文件在yolov11/ultralytics/cfg文件中
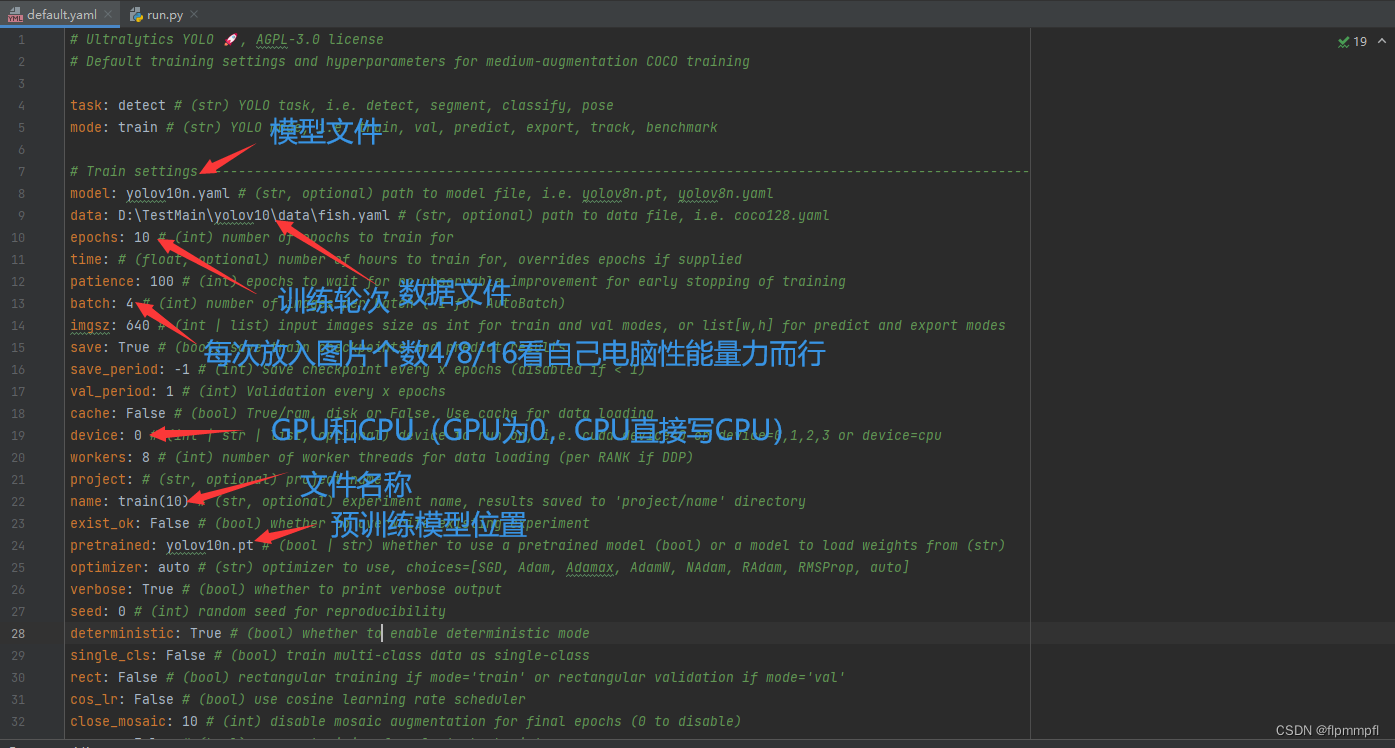
需修改(最好为绝对路径,多仔细看看,容易出错)
模型文件model(yolov10x.yaml(模型文件)位置)
数据文件(训练图片)data(data.yaml文件所在位置)
训练轮次epochs(基本为300)
训练所放图片个数batch(2/4/8/16,看自己电脑量力而行)
训练存储地址和名称name(可不改)
使用GPU训练device:0(重点)(如有两个GPU:[0,1])
预训练权重pretrained(yolov10n.pt(权重文件,要于上面对应,就比如你用yolo10n训练你就必须要yolov10n.pt来作为你的预训练权重)位置,无可以不填)
点击终端,输入神秘代码:
yolo cfg=ultralytics/cfg/default.yaml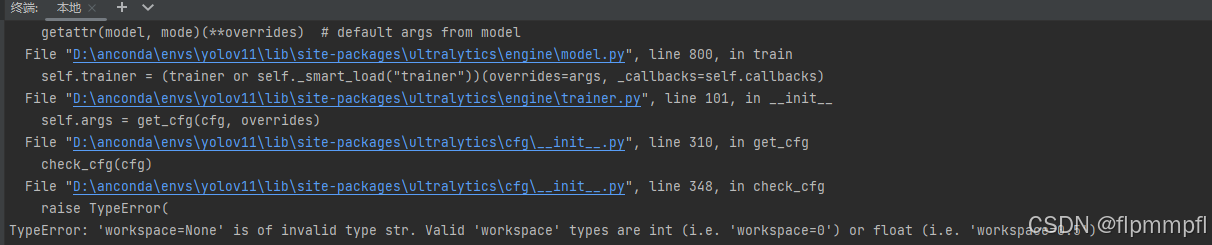
会报错:TypeError: 'workspace=None' is of invalid type str. Valid 'workspace' types are int (i.e. 'workspace=0') or float (i.e. 'workspace=0.5')这个原因是输入workspace的类型不对,不太懂,看workspace参数是用于 TensorRT 的配置项,它表示 TensorRT 在优化和执行网络时可以使用的最大临时工作内存大小(以 GiB 为单位)。我认为没有什么用,我就直接ctrl+/把这行注释了,有懂得可以留言。
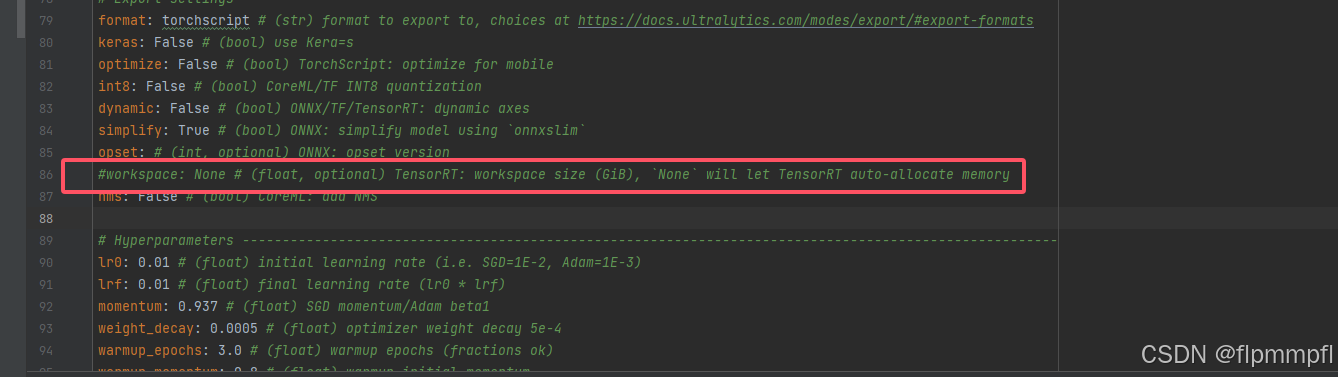
然后就没有什么问题了
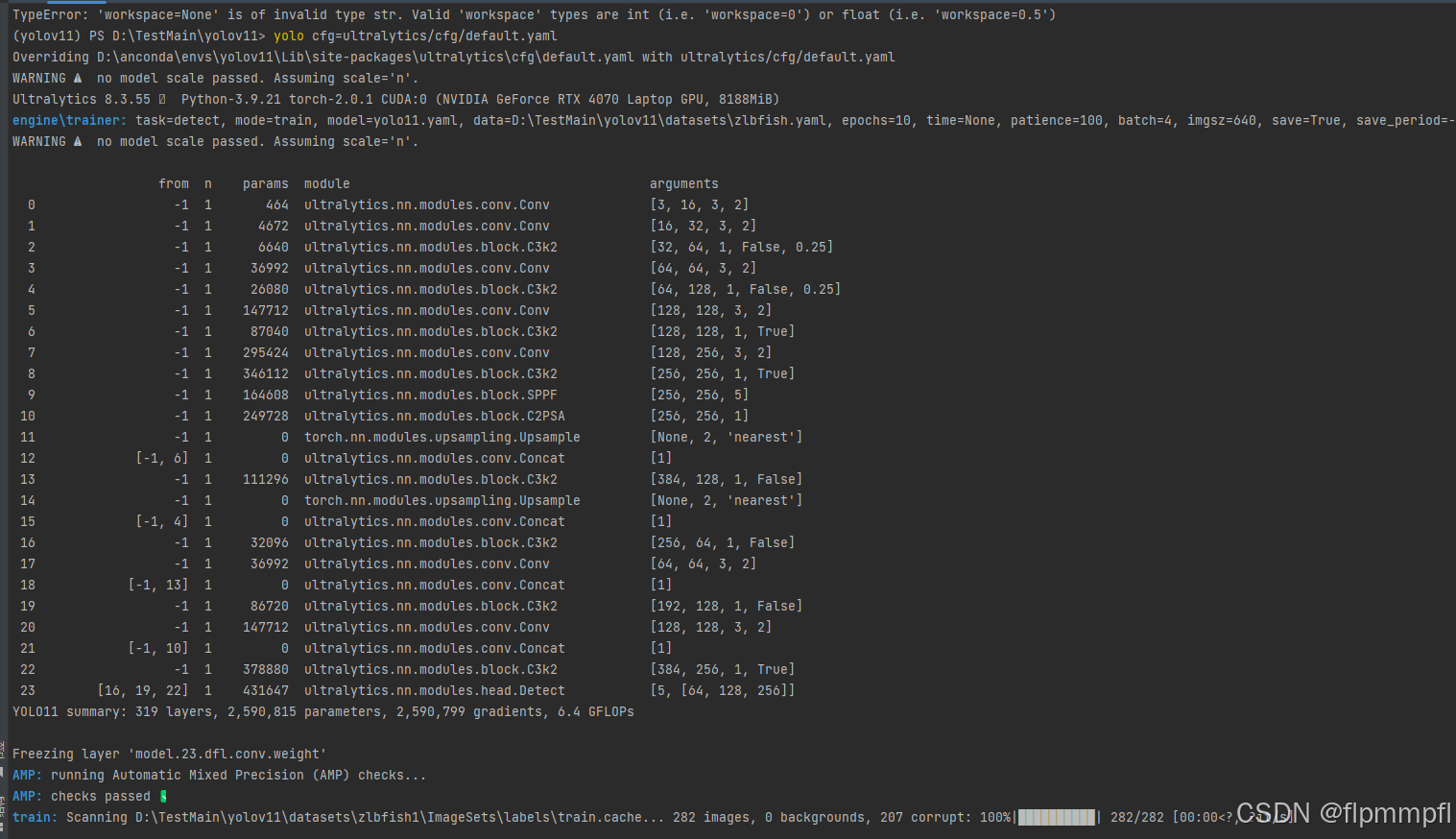
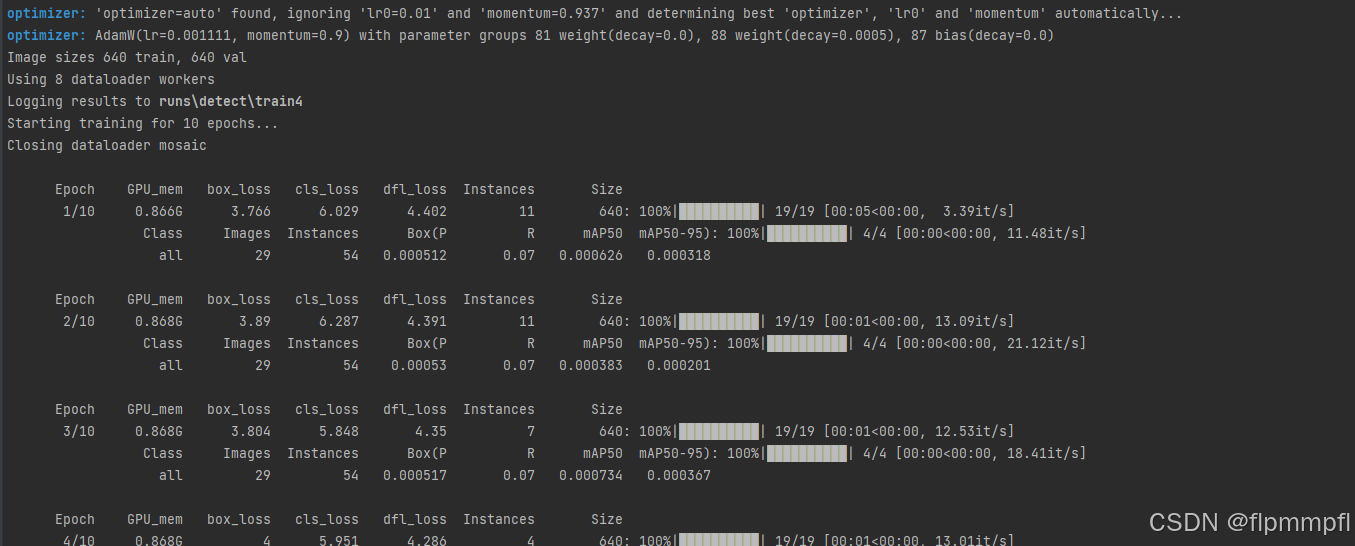
9、常见问题
报错:ImportError: DLL load failed while importing _imaging: 找不到指定的模块。
原因:pillow版本没有对应上,导致torchvision模块不能加载进来
先卸载pillow
pip uninstall Pillow重新安装Pillow
pip install Pillow报错:RuntimeError: Numpy is not available
原因:numpy没有安装对应版本
先卸载numpy
pip uninstall numpy重新安装numpy
pip install numpy==1.23.5报错:ModuleNotFoundError: No module named 'numpy._core'
原因:在训练之前,模型会对已有的数据集有一个预处理,在dataset/train和dataset/val文件夹中,生成一个.cache格式的文件,如果这个文件已有的话,是不会再次生成的。而这个文件的生成依赖于numpy,不同的numpy版本会造成上面的报错。所以解决方式就是把dataset文件夹中已有的.cache文件删掉,然后重新跑,让服务器环境的numpy再生成一个.cache文件,就没有上面这个报错了
大功告成,觉得好的就点点赞,点点收藏,如有什么错误或者建议麻烦指出(字码错了也可以说,毕竟经常这样),谢谢



















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









