







1.1 简介
GMapping 是经典的基于滤波器的 2D-SLAM 算法,现在基本不会部署在智能车上,对2D-SLAM而言,目前 Cartographer 是比较常用的,尤其是引入odom,IMU之后。
GMapping 在 Fast-SLAM 的基础上经过了优化。使用了 RBPF(Rao-Blackwellized Particle Filters)粒子滤波算法,并对 RBPF 计算中的一些环节加以进一步优化,进而提高了 proposal 分布采样的位姿质量,并降低 了重采样次数,进而缓解了粒子耗散的问题。
1.2 代码地址
GMapping : https://github.com/ros-perception/slam_gmapping
1.3 算法原理
首先我们理解 GMapping 是在已知激光雷达数据情况下,同时来进行估计机 器人位姿与地图的问题。简介中提到的 RBPF 即把它分成了两个问题,先定位,再建图,具体对于定位于建图的原理可以参考此论文:
Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters
我将它结合网上大神和自己的理解整理了一下,如有错误请以论文为准:
1.3.1 GMapping 理论模型
SLAM 问题的概率模型如下:
𝑝(𝑥1:𝑡 , 𝑚|𝑢1:𝑡 , 𝑧1:𝑡) (4-17)
式中 𝑧1:𝑡—传感器的信息,𝑢1:𝑡—控制信息,
即需要对地图𝑚,机器人位姿𝑥1:𝑡进行同时估计。 RBPF 算法把 SLAM 问题分为两个问题:机器人定位问题,即位姿;已知机器人 位姿进行地图构建。
对式(4-17)概率模型进行化简:
𝑝(𝑥1:𝑡 , 𝑚|𝑢1:𝑡 , 𝑧1:𝑡 ) = 𝑝(𝑥1:𝑡 |𝑢1:𝑡 , 𝑧1:𝑡)𝑝(𝑚|𝑥1:𝑡 , 𝑢1:𝑡 , 𝑧1:𝑡) (4-18)
式(4-18)中,因有轨迹推算,𝑢1:𝑡与𝑚无关,可得:
𝑝(𝑥1:𝑡 |𝑢1:𝑡 , 𝑧1:𝑡)𝑝(𝑚|𝑥1:𝑡 , 𝑧1:𝑡) (4-19)
式中,𝑝(𝑥1:𝑡 |𝑢1:𝑡 , 𝑧1:𝑡)表示对机器人当前位姿进行估计,𝑝(𝑚|𝑥1:𝑡 , 𝑧1:𝑡)表示已知位姿信息与传感器信息进行地图构建。
据式(4-19)可知,对位姿的估计是极其重要的,每一个粒子构建一个地图,则每 个粒子包含了机器人的位姿与环境地图。
需要利用贝叶斯准则对公式进行变化,将其转 换为增量估计的问题。 为寻找𝑥1:𝑡 , 𝑧1:𝑡关系,对式(4-19)进行转换为:
𝑝(𝑥1:𝑡 |𝑧𝑡 , 𝑢1:𝑡 , 𝑧1:𝑡−1) (4-20)
根据条件贝叶斯公式对式(4-20)化简:
𝑛𝑝(𝑧𝑡 |𝑥1:𝑡 , 𝑢1:𝑡 , 𝑧1:𝑡−1)𝑝(𝑥1:𝑡 |𝑢1:𝑡 , 𝑧1:𝑡−1) (4-21)
对𝑡时刻,𝑥𝑡即可预测𝑧𝑡,约减为:
𝑛𝑝(𝑧𝑡 |𝑥𝑡)𝑝(𝑥1:𝑡 |𝑢1:𝑡 , 𝑧1:𝑡−1) (4-22)
根据条件联合概率对式(4-22)化简:
𝑛𝑝(𝑧𝑡 |𝑥𝑡)𝑝(𝑥𝑡 |𝑥1:𝑡−1, 𝑢1:𝑡 , 𝑧1:𝑡−1)𝑝(𝑥1:𝑡−1|𝑢1:𝑡 , 𝑧1:𝑡−1) (4-23)
式中,𝑥𝑡只与𝑥𝑡−1和𝑢𝑡有关,约减为:
𝑛𝑝(𝑧𝑡 |𝑥𝑡)𝑝(𝑥𝑡 |𝑥𝑡−1, 𝑢𝑡)𝑝(𝑥1:𝑡−1|𝑢1:𝑡−1, 𝑧1:𝑡−1) (4-24)
经过上述一系列推理,将机器人的位姿估计转化为增量估计问题。
式(4-24)中,𝑝(𝑥1:𝑡−1|𝑢1:𝑡−1, 𝑧1:𝑡−1)代表 𝑡 − 1 时刻机器人位姿,用𝑡 − 1时刻粒子 群表示。𝑝(𝑥𝑡 |𝑥𝑡−1, 𝑢𝑡 )为运动学模型,𝑝(𝑧𝑡 |𝑥𝑡)为观测模型。每个粒子先用𝑝(𝑥𝑡 |𝑥𝑡−1, 𝑢𝑡) 进行状态统计,即可得到预测位姿,后用𝑝(𝑧𝑡 |𝑥𝑡)进行权重计算,进行地图构建。
每个粒子都有自己的栅格地图信息,在建图环境和变化较大时,每个粒子所占内存 较大。若里程计误差大,proposal 与真实的分布有很大的偏离,那么需要更多的粒子提 供足够的信息才能对位姿进行估计,会导致内存占用巨大。
为解决此问题,GMapping 将 粒子的数量控制在一定范围内,并使用极大似然估计方法,提升 proposal 分布采样的位 姿质量。 即对式(4-24)进行优化:
𝑥𝑡 𝑖 = 𝑝(𝑥𝑡 |𝑢𝑡 , 𝑥𝑡−1 𝑖 ) (4-25)
经优化后极大似然估计方法为:
𝑥𝑡 𝑖 = arg 𝑚𝑎𝑥 𝑥𝑡 {𝑝(𝑧𝑡 |𝑥𝑡 , 𝑚)𝑝(𝑥𝑡 |𝑢𝑡 , 𝑥𝑡−1 𝑖 )} (4-26)
每一次的再取样都是随机的,当取样次数增多时,会产生分散的粒子,也就是所谓 的粒子消散问题。
在 GMapping 中,通过计算颗粒的离散度来降低再取样次数,来确定 是否重采样,即粒子权重方差,表示预测和实际的差异性,:
𝑁𝑒𝑓𝑓 = 1 ∑(𝑤𝑖) 2 (4-27)
式(4-27)中,𝑁𝑒𝑓𝑓较大,差异性较小不进行重采样;𝑁𝑒𝑓𝑓较小,差异性较大重采样。
1.3.2 代码流程
整理流程可以参考论文中的第 6 页 Algorithm 1 Improved RBPF for Map Learning 部分,这里做一次究极简化:

由 Scan 做数据输入,以 Scan->odom 的 /tf 做转换,定位为 base_link->map,输出为 SLAM部分给到 map。
对应代码中的结构为:
(1)slam_gmapping.cpp:167:void SlamGMapping::init() 初始化函数
(2)slam_gmapping.cpp:269:void SlamGMapping::startLiveSlam() 订阅发布注册
(3)slam_gmapping.cpp:352: void SlamGMapping::publishLoop(double transform_publish_period) 发布TF
(4)slam_gmapping.cpp:609:void SlamGMapping::laserCallback(const sensor_msgs::LaserScan::ConstPtr& scan) 雷达数据处理
(5)slam_gmapping.cpp:676:SlamGMapping::updateMap(const sensor_msgs::LaserScan& scan) 更新地图
其他的几个函数就是初始化地图,计算姿态粒子等等。下面就是对粒子形成Map图的过程做一个究极简化,上面我们说每一个姿态𝑝(𝑥1:𝑡−1|𝑢1:𝑡−1, 𝑧1:𝑡−1)的粒子都含有其观测𝑝(𝑧𝑡 |𝑥𝑡),对这些粒子观测进行权重计算即可输出地图 Map:
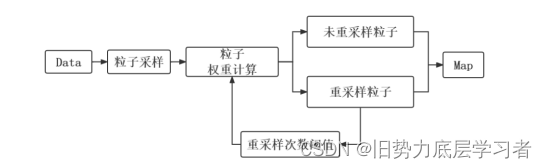
这里的观测 𝑝(𝑧𝑡 |𝑥𝑡) 很明显是当前姿态下观测模型的概率值,就需要引出栅格地图这个概念,即灰度图(最终地图):
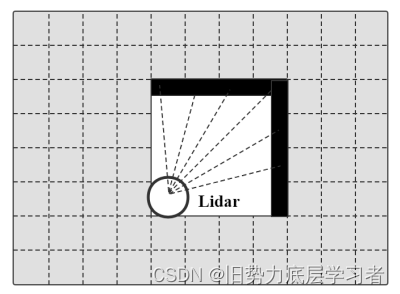
白色:激光束穿过,黑色:激光束击中,灰色:未知。对每个栅格访问次数 𝑣 ,栅格被选用次数 𝑛 , 物理位置总选用次数p。栅格的占用概率可以用式表示: 𝑝 = 𝑛 / v
从观测模型得到的观测 𝑝(𝑧𝑡 |𝑥𝑡) 即可引入栅格击中概率,输出到Map。
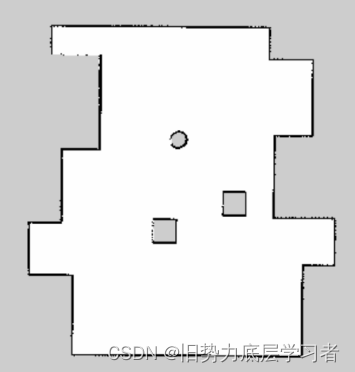
1.4 GMapping结果图
不积跬步无以至千里,不积小流无以成江河 ------------------------1:08


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









