








Abstract
过去几年,遗传编程(GP)语义的研究有所增加。该领域的结果清楚地表明,它在 GP 中的使用可显着提高性能。许多基于语义的方法都依赖于试错法,该方法试图使用交叉算子(基于交叉语义-CSB)进行多次试验来找到在语义上与其父母不同的后代。因此,这有一个主要缺点:这些方法可以评估数千个节点,导致付出高昂的计算成本,同时试图通过促进语义多样性来提高性能。在这项工作中,我们提出了一种简单且计算成本低廉的方法,称为选择语义,它消除了 CSB 方法中观察到的计算成本。我们在 14 个 GP 问题(包括连续值和离散值适应度函数)中测试了这种方法,并将其与传统 GP 和 CSB 方法进行了比较。我们的结果与 CSB 方法的结果相同,在某些情况下甚至优于 CSB 方法,而无需使用“强力”机制。
I. INTRODUCTION
遗传编程(GP)[12]已成功应用于各种不同的挑战性问题(请参阅Koza关于human competitive results for a comprehen-
sive review[ 13])。尽管它已被证明是成功的,但它也存在一些局限性,研究人员一直对通过研究搜索过程的各种要素(例如中立性 [4]、[8]、[9]、[ 21],地点[5],[6],[7],特殊表示[3])。
最近引起研究人员注意的这些元素之一是语义研究,导致相关出版物数量急剧增加(例如,[1]、[10]、[11]、[14]、[15] ]、[16]、[20]、[23])。
语义是一个广泛的概念,已在不同领域(例如自然语言、心理学)进行研究,因此很难给出该概念的精确定义。因此,在这项工作中,我们采用了最近相关工作 [10]、[20]、[22]、[23] 中 GP 中语义的流行用法,其中研究人员将其用作两个程序原始输出的差异。
该领域的研究清楚地表明,在 GP 过程中语义的研究和应用可以提高其性能[10]、[11]、[20]、[22]、[23]。这些研究依赖于交叉语义算子的使用试图找到,经过一段时间的试验,后代在语义上与父母不同。尽管这些类型的方法已被证明在寻找问题解决方案方面比传统的 GP 具有更优越的性能,并且开始摆脱 GP 中语义的重要性,但它们也受到一个特定的限制:由于它们的试验,这些方法的计算成本很高误差方法[16]。
本文的主要目标是探索在规范 GP 中使用语义的可能性,而无需评估潜在的数千个节点,同时与基于试错的方法相比保持相似的性能。更具体地说,我们提出了一种在选择过程中使用语义的简单且计算成本低廉的方法,其中通过考虑其适应性来选择一个父级,而选择第二个父级则考虑适应性和语义相异性。第一个选定的父级。这消除了使用“蛮力”机制来查找语义上与其父母不同的 children 的需要,因此,这种新的基于语义的方法(称为选择语义(SiS))的计算成本与传统的 GP 系统。
论文结构如下。在第二节中,我们介绍了之前在 GP 语义领域开展的工作。在第三节中,我们介绍了我们提出的方法。第四节提供了所用实验设置的详细信息。本文提出的结果在第五节中讨论,最后,第六节得出结论和未来的工作。
II. RELATED WORK
麦克菲等人。 [15]通过提出两种形式的方法来分析子树交叉在语义构建块方面的影响:子树语义和上下文语义。在布尔问题的背景下,作者能够展示 GP 语义多样性的重要性。即麦克菲等人。指出GP中使用的90%10%交叉算子(即90%-10%内部外部节点选择策略)如何导致高比例的交叉事件在GP的语义空间中没有任何有用的影响,从而导致绩效缺乏提高,以几代人寻找 fitter individuals 来衡量。
Beadle 和 Johnson [1] 提出了一种交叉算子,称为语义驱动交叉 (SDC),它可以促进搜索过程中的语义多样性。更具体地说,他们在布尔问题(即多路复用器和偶数 5 奇偶校验问题)上使用降序二元决策图 (ROBDD) 来检查父母和后代之间的语义相似性。 Beadle 和 Johnson 在使用 SDC 后,在增强体能方面表现出了显着的改善。此外,他们还表明,通过在这些特定问题上使用 ROBDD,SDC 操作员能够显着减少膨胀。
乌伊等人。 [20]提出了在实值场景(例如符号回归问题)上应用语义交叉算子的四种不同形式。为此,作者通过根据从域中采样的随机点集进行测量来测量两个给定表达式的语义等价性。如果这两个表达式的结果输出彼此接近,并且受到称为语义敏感性的阈值的影响,则这些表达式被视为语义等效。在他们的前两个场景中,Uy 等人。他们将注意力集中在子树的语义上。更具体地说,对于场景 I,作者尝试通过在多个试验中执行交叉(如果两个子树在语义上等效)来鼓励语义多样性。场景 II 探索了与场景 I 相反的想法。对于最后两个场景,作者将注意力集中在完整的树上。也就是说,对于场景 III,Uy 等人。检查后代和父母在语义上是否等效。如果是这样,父母就会被遗传到下一代,而后代就会被丢弃。作者在场景 IV 中探讨了场景 III 的相反想法(孩子在语义上与父母不同)。他们表明,对于许多符号回归问题,与他们提出的其他树场景相比,场景 I 产生了更好的结果。
Jackson [10]也研究了语义学,称之为表型多样性。在他的工作中,作者根据程序的输出来测量程序的语义。为此,作者使用了来自不同领域的问题(例如布尔问题、符号回归问题和迷宫类问题)。对于布尔问题(例如偶数奇偶校验问题),作者根据两个程序输出字符串相应位的差异来测量两个程序之间的语义差异。对于符号回归问题,Jackson 使用了类似于上述 Uy 方法 [20] 的方法。对于迷宫问题(例如人工蚂蚁),作者记录了路径历史。作者的方法也类似于 Uy 的方法,基于使用最大数量的试验(大约 20 次)来尝试促进语义多样性。 Jackson 展示了语义多样性如何促进更好的搜索,与传统的 GP 相比,更频繁地找到解决方案。
最近,莫拉里奥等人。 [16]提出了几何语义GP,其主要思想是直接在潜在解决方案(程序)的底层语义空间中使用它。也就是说,作者考虑了语义空间的属性,针对不同的指标,并为设计基于语义的几何交叉算子提供了见解。他们在各种问题中测试了他们的方法,展示了通过交叉产生的语义不同的程序如何产生比标准 GP 更好的结果,这与其他基于语义的方法获得的结果一致。有趣的是,作者还报告了他们的方法如何产生更大的程序,这与 Uy 等人发现的结果相矛盾。 [20]。
最近,Krawiec 和 Pawlak [14] 探索了几何语义 GP 的概念,其关键概念是产生作为父程序的语义中值的后代是理想的。这意味着,如果后代具有父母语义的平等混合或混合,那将是有益的。他们推测,找到满足父母之间语义中值测量的后代,将增加后代比父母双方具有更高适应性的机会。他们的方法试图调节交叉效应。在句法交叉可能导致语义发生巨大变化(或根本没有变化)的情况下,他们的方法试图在创建后代时提供更统一的语义变化。由于创建这样的后代很困难,作者通过检查位于父程序同源区域的语义中值的更实用的测量方法,为这一主张提供了初步证据。
A. Final Comments on Semantics in GP
从前面的总结中可以清楚地看出,没有单一的方法可以将语义合并到 GP 中。例如,Beadle 和 Johnson [1] 开展的工作与 Uy 等人提出的工作完全不同。 [20]。
然而,值得注意的是,当明确考虑语义时,作者如何一致地报告 GP 搜索性能的改进(以更频繁地找到解决方案来衡量)。
受到这些方法及其在[10]、[11]、[20]、[22]、[23]中报告的令人鼓舞的结果的启发以及之前的简要总结,这项工作继续使用相同形式的语义(例如,[10]、 [22]),在下一节中根据所使用的问题进行了强化,并提出了一个简单的想法来克服这些 CSB 试错方法所观察到的计算昂贵的限制。然而,值得一提的是,最近的工作已经开始对此进行一些阐述,但使用其他形式的语义 [16] 以及所谓的基于行为的方法 [17]、[18]、[19]。
III. SEMANTICS IN SELECTION
从上一节可以看出,在 GP 中主要使用交叉作为主要遗传算子来探索语义(很少有工作也探索使用突变来使用它,例如[2]),在连续[10]中报告了出色的结果。和离散值适应度函数[20]。这些方法(例如,[10]、[11]、[20]、[22]、[23])的一个潜在限制是,作者报告了在应用交叉时使用最大尝试次数,寻找与父母语义不同的孩子。由于采用这种试错方法,与传统 GP 相比,GP 系统有可能评估更多的节点。
在这项工作中,我们努力通过在选择过程中考虑语义来克服这一限制,而不需要使用最大数量的试验。该方法通过使用众所周知的 GP 基准问题(即第四节中介绍的Artificial Ant, Even-n-Parity and Symbolic Regression问题)在连续和离散值适应度情况下进行测试。
在解释该方法之前,重要的是要说明我们如何测量语义,这是基于[10]、[20]报告的先前工作,其中作者将语义定义为语法正确的程序的含义。我们认为最好将语义定义为程序的功能(原始输出)。主要原因是因为在这些作品中,作者通过两个 GP 个体在执行指令时的输出差异来衡量语义多样性。接下来将针对本工作中使用的每个问题进行解释。
对于人工蚂蚁问题的情况,我们通过记录程序执行产生的动作来跟踪个体的语义。因此,每次蚂蚁移动到不同的方块时,我们都会在向量中记录蚂蚁面对的位置(即北、东、南、西)。对于这个特定问题,如果两个个体的输出向量不同,我们认为它们在语义上不同,否则它们在语义上相似。
对于 Even-n-Parity 问题 (n = {3, 4, 5}),个体的语义是根据它产生的输出来衡量的。更具体地说,我们将每个健身案例产生的结果记录在大小为 2 n 2^n 2n 的向量中。因此,如果两个个体的输出向量不同,我们就认为它们在语义上不同,否则就认为它们在语义上相似。
最后,对于符号回归问题,我们再次根据个体产生的输出来跟踪个体的语义,就像在 Even-n Parity 问题中一样。主要区别在于,在这个连续值适应度函数问题中,我们还使用阈值 (α = 0.01) 来指示两个个体在语义上是否不同。也就是说,在大小为 fc 的向量中,其中 fc 是所使用的适应度案例的数量,我们检查相应输出之间的绝对差异是否在 α 范围内。因此,如果对于向量中包含的每个对应值的差异大于阈值α,我们认为两个个体在语义上不同,否则认为它们在语义上相似。
如前所述,研究人员报告称,通过鼓励语义多样性(例如,父母和后代在语义上不同),GP 系统的性能得到了改善。在这项工作中,不是在交叉级别上推广它,而是重复该运算符的应用,直到后代在语义上与其父母不同,或者直到执行最大数量的试验(例如, n m a x n_{max} nmax = 20),无论先发生什么[10]、[11]、[20]、[22]、[23]我们鼓励选择运算符的语义多样性,在本例中使用锦标赛选择。
也就是说,我们以典型的方式选择第一个父代:我们定义一个 t s i z e t_{size} tsize 个体池,对于最大化问题,选择具有最高适应度的个体用于交叉算子中。第二个父代的选择是通过考虑以下两个因素来选择的:适合度和与第一个选择的父代的语义差异。更具体地说,第二个父代是从 t s i z e t_{size} tsize 个个体池中选择的,如前几段所述,该个体在语义上与第一个父代不同,并且具有最高的适应值。算法 1 详细描述了这个想法。对于目标是最小化的问题,该方法的工作原理相同,不同之处在于选择适应度最低的个体。
这个想法背后的动机是,通过拥有两个不仅适合而且语义不同的父母,他们通过交叉获得的后代可以增加产生语义不同个体的可能性,而无需使用试错方法,消除了由于应用交叉
n
m
a
x
n_{max}
nmax 次而产生的不必要的评估节点的数量。我们在第五节进一步讨论这一点。

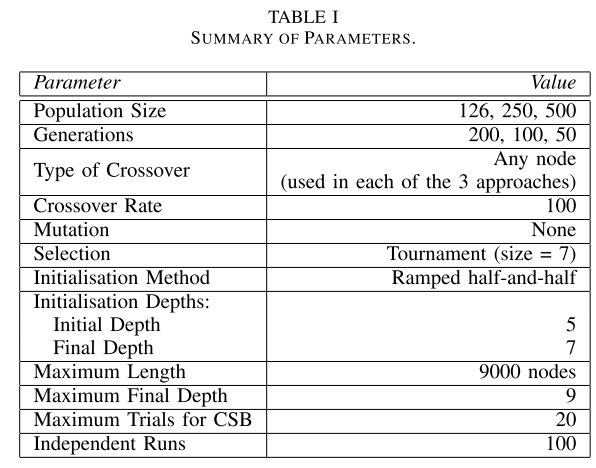
IV. EXPERIMENTAL SETUP
在我们的分析中,我们使用了 14 个 GP 基准问题:人工蚂蚁问题 [12]、Even-n-Parity (n = {3, 4, 5}) 问题(需要组合多个 XOR 函数的问题,以及如果没有有利于它们归纳的偏差被添加到算法的任何部分)很困难,和实值符号回归问题(具有 10 个不同的目标函数,如表 II 最左列所示)。

第一个问题是人工蚂蚁问题 [12,第 147-155 页],其任务是找到一个程序,能够成功地引导人工蚂蚁沿着 32 x 32 环形网格上的 89 颗食物颗粒的路径行驶。当蚂蚁遇到食物颗粒时,它的(原始)适应度会增加 1,最高达到 89。由于多种原因,这个问题本身就具有挑战性。蚂蚁必须吃掉沿着一条扭曲的轨道散布的所有食物颗粒(通常为 600 步),轨道上有一个、两个和三个间隙。该问题使用的终端集是 T = {Move, Right, Left}。函数集为 F = {IfFoodAhead,P2, P3}。
第二、第三和第四个问题是布尔偶校验问题 (n = {3, 4, 5}),其目标是演化一个函数,如果偶数个输入计算结果为 true,则返回 true,否则返回 false。此类问题的最大适应度为 2 n 2^n 2n。终端集是输入集。函数集为 F = {AND, OR,NOT}。
其余问题是实值符号回归问题。此类问题的目标是找到一个输出等于函数值的程序。因此,群体中个体的适应度反映了个体的输出与目标( F 1 , ⋅ ⋅ ⋅ ⋅ , F 10 F_1,····,F_{10} F1,⋅⋅⋅⋅,F10)的接近程度(参见表II最左列)。通常将适应度定义为在自变量 x 的不同值(在本例中为 [1.0,1.0] 范围)下测量的绝对误差之和。在本研究中,我们测量了 x , y ∈ { − 1.0 , − 0.9 , − 0.8 ⋅ ⋅ ⋅ 0.8 , 0.9 , 1.0 } x, y ∈ \{−1.0, −0.9, −0.8 · · · 0.8, 0.9, 1.0\} x,y∈{−1.0,−0.9,−0.8⋅⋅⋅0.8,0.9,1.0} 的误差。我们定义了一个任意阈值0.01,表示适应度小于阈值的个体被视为正确解,即“命中”。函数集为 F = {+, −, *, /, Sin,Cos, Exp, LOG},其中 / 为保护除法。我们使用相同的阈值 0.01 来指示两个个体在语义上是否不同或相似(α = 0.01), 如第三节所述。
为了评估我们提出的方法,选择语义(SiS),并出于比较的目的,我们实现了另外两种方法:传统的 GP 系统和基于交叉语义的方法,分别称为 GP 和 CSB。 CSB 尝试通过最大数量的试验来促进交叉算子的语义差异,如第 III 节中所述(详细信息请参阅[20])。
对于所使用的三种方法中的每一种,均使用具有锦标赛选择的稳态方法和传统交叉算子来进行实验。使用的其余参数如表 I 所示。为了获得有意义的结果,我们进行了广泛的经验实验(总共 100 * 42 * 3 次运行).
V. RESULTS AND ANALYSIS
A. Performance Comparison
让我们首先分析所用三种方法中每种方法的性能(以找到解决方案的运行百分比来衡量),即群体大小 = 126 和代数 = 200 的第一个组合,如第二、第三和第四列所示表 II,针对本研究中使用的 14 个问题中的每一个。对于第一个问题,人工蚂蚁,没有什么可说的,因为所有三种方法,GP,CSB 和 SiS,表现同样糟糕。也就是说,他们都没有找到解决办法。对于 Even3-Parity 问题,这些方法之间的性能没有差异,因为所有方法都能够始终找到解决方案(100% 成功率)。对于 Even-4-Parity Problem,情况就更清楚了。在这个问题中,基于语义的方法比传统的 GP 系统要好得多:GP、CSB 和 SiS 的成功率分别为 19、60、58。对于 Even-5-Parity 问题,所有方法的性能都很差,区别在于 SiS 能够找到解决方案,尽管次数很少,而 GP 和 CSB 都无法解决该问题。对于最后一类问题,即符号回归,如表 II 的最后 10 行所示,其中对于某些函数(即 F 1 、 F 2 、 F 3 、 F 4 、 F 6 F_1、F_2、F_3、F_4、F_6 F1、F2、F3、F4、F6),基于语义的方法显示出优于 GP 方法的性能。与没有语义的 GP 相比,语义如何持续提高性能是显而易见的。对于其他符号回归问题(例如 F 5 、 F 9 、 F 10 F_5、F_9、F_{10} F5、F9、F10),情况不太清楚,因为所有三种方法的性能或多或少相似。最后,有趣的是,对于几乎所有使用的问题,与传统的 GP(Even-4 除外)相比,两种基于语义的方法都需要更长的时间(表 II 括号内指示了代数)来找到解决方案奇偶校验问题)。
现在让我们将注意力转向第二种配置:种群规模 = 250,本研究中使用的三种方法世代 = 100,示于表II的第五、第六和第七列。和以前一样,对于人工蚂蚁问题没什么可说的,因为这三种方法的表现同样糟糕。对于 Even-n-Parity 问题,GP 方法和基于语义的方法之间存在一些显着差异。特别是,对于 Even-4-Parity 问题,基于语义的方法(即 CSB 和 SiS)发现的结果要好得多,比 GP 好大约四倍。在一些符号回归函数(例如 F1、F2、F3、F6)中观察到类似的趋势,尽管性能差异不如 Even4-Parity 问题的情况那么令人印象深刻,在 Even4-Parity 问题中,平均性能提高了,是 GP 方法的两倍。对于其他函数(例如 F5.F10),这三种方法的表现同样糟糕,因为很少有运行能够找到这些问题的解决方案。
对于种群规模和代数的最后组合(分别为 500 和 50),本研究中使用的三种方法和 14 个基准问题观察到相同的趋势。
也就是说,基于语义的方法始终优于 GP 方法(例如,Even-4-Parity、 F 1 、 F 2 、 F 3 、 F 4 F_1、F_2、F_3、F_4 F1、F2、F3、F4),无论用于种群大小和迭代次数的组合如何
B. Crossover-Semantics Based vs. Semantics in Selection
从表 II 报告的结果可以清楚地看出,两种基于语义的方法都优于 GP 系统的性能,在某些情况下,这些方法比后一种方法好四倍。
CSB 方法显示的性能(见表 II)与 Jackson [10] 和 Uy 等人先前报告的结果一致。 [20] 其中作者报告了在交叉级别使用语义来尝试查找语义不同的子项(使用最大尝试次数)时取得的出色结果。后者的结果是,GP 系统可以评估数十万个节点,从而导致计算成本极高的过程。
我们的方法(SiS)的主要好处是它不会存在需要评估数千个节点的缺陷(我们将在下面的段落中讨论这一点)。此外,如上所述,我们提出的方法与 CSB 方法相比在性能上是等效的,并且在某些情况下更优越。
现在,让我们将注意力集中在 CSB 和 SiS 评估的节点数量上,如图 1 所示(请注意,由于出于空间限制和清晰目的,我们绘制了人工蚂蚁、偶数奇偶校验和前三个符号回归问题的评估节点)。从图 1 所示的图中可以清楚地看出,与其他语义方法(基于交叉)相比,我们提出的方法 (SiS) 评估的节点数量要少得多。这是可以预料的,因为正如我们在第三节中讨论的那样,后一种方法通过交叉执行详尽的搜索,并进行最大次数的试验,以找到在语义上与其父母不同的孩子。同样有趣的是,注意到人口规模和基于交叉语义的方法评估的节点数量之间似乎存在正相关。

基于交叉的方法可能是膨胀(个体快速成长)的结果,而不是使用交叉算子执行广泛的搜索。因此,为了证明情况并非如此,我们测量了 CSB 方法所需的平均试验次数。如图 2 所示。这些图证实了我们之前的发现:在所提到的方法中评估数十万个节点的结果是尝试通过交叉运算符查找在语义上与其父代不同的后代的结果。试验次数(本研究中设置为 20,如表 I 所示)。

CSB 方法使用的试验次数因问题而异。例如,对于人工蚂蚁问题(如图 2 顶部所示),大约进行了 3 次尝试,无论定义的种群规模和代数的大小
对于 Even-n-Parity 问题,这个数字会有所不同。当 n = 3 时,需要更多的试验才能找到与父母语义不同的孩子,并且随着 n 的增加而减少。这是可以预料的,因为使用的适应度案例数量越多,找到语义上与其父母不同的孩子的机会就越大,因为如第三节中所解释的,如果两个个体的输出向量不同,则两个个体被认为在语义上不同。在这类问题中还需要指出的是,Even-4 和 Even-5 问题的试验次数随着总体规模的增加而增加,这表明总体规模较大并不一定意味着更容易发现孩子在语义上与父母不同。
对于符号回归问题也观察到相同的趋势(为了清楚起见,我们再次仅绘制了 F1、F2、F3,请参见图 2 底部)。也就是说,试验数量随着群体规模的增加而增加,直到达到一定限度。例如,当使用 126 人和 250 人时,试验次数几乎翻倍,分别为 9 次和 18 次。当使用 250 和 500 个人时,没有观察到这种增加,当使用这两种人群规模时,试验数量或多或少保持相同(大约 18 项试验)。
VI. CONCLUSIONS AND FUTURE WORK
在过去的几年里,在其机制中明确考虑语义的 GP 系统已被证明具有比传统 GP 方法更优越的性能。在这项工作中,我们提出了一种简单且计算成本低廉的方法来在 GP 中使用语义,称为选择语义,与试图促进使用昂贵的试错方法(例如[10]、[11]、[20]、[23])来实现交叉算子的语义多样性,在本工作中称为基于交叉语义的方法。
因此,通过在选择中使用语义,我们保证 GP 系统的计算量保持不变。为了测试这种方法的效率,我们使用了 14 个 GP 基准问题,包括连续值和离散值适应度函数,并比较了使用传统 GP 和基于交叉语义的方法的结果。
本文提出的选择方法中的语义已经显示出有希望的结果,在许多情况下与基于交叉语义的方法相比取得了更好的结果。我们将扩展和完善我们的方法,以探索更多的好处。例如,可以通过使用明确定义的度量(例如汉明距离)来调整布尔问题和 Ant 问题所使用的比较语义差异。对于符号回归问题,可以根据GP搜索的进度动态调整阈值。
References
Galvan-Lopez E, Cody-Kenny B, Trujillo L, et al. Using semantics in the selection mechanism in genetic programming: a simple method for promoting semantic diversity[C]//2013 IEEE Congress on Evolutionary Computation. IEEE, 2013: 2972-2979.
@inproceedings{galvan2013using,
title={Using semantics in the selection mechanism in genetic programming: a simple method for promoting semantic diversity},
author={Galvan-Lopez, Edgar and Cody-Kenny, Brendan and Trujillo, Leonardo and Kattan, Ahmed},
booktitle={2013 IEEE Congress on Evolutionary Computation},
pages={2972--2979},
year={2013},
organization={IEEE}
}















 9794
9794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









