







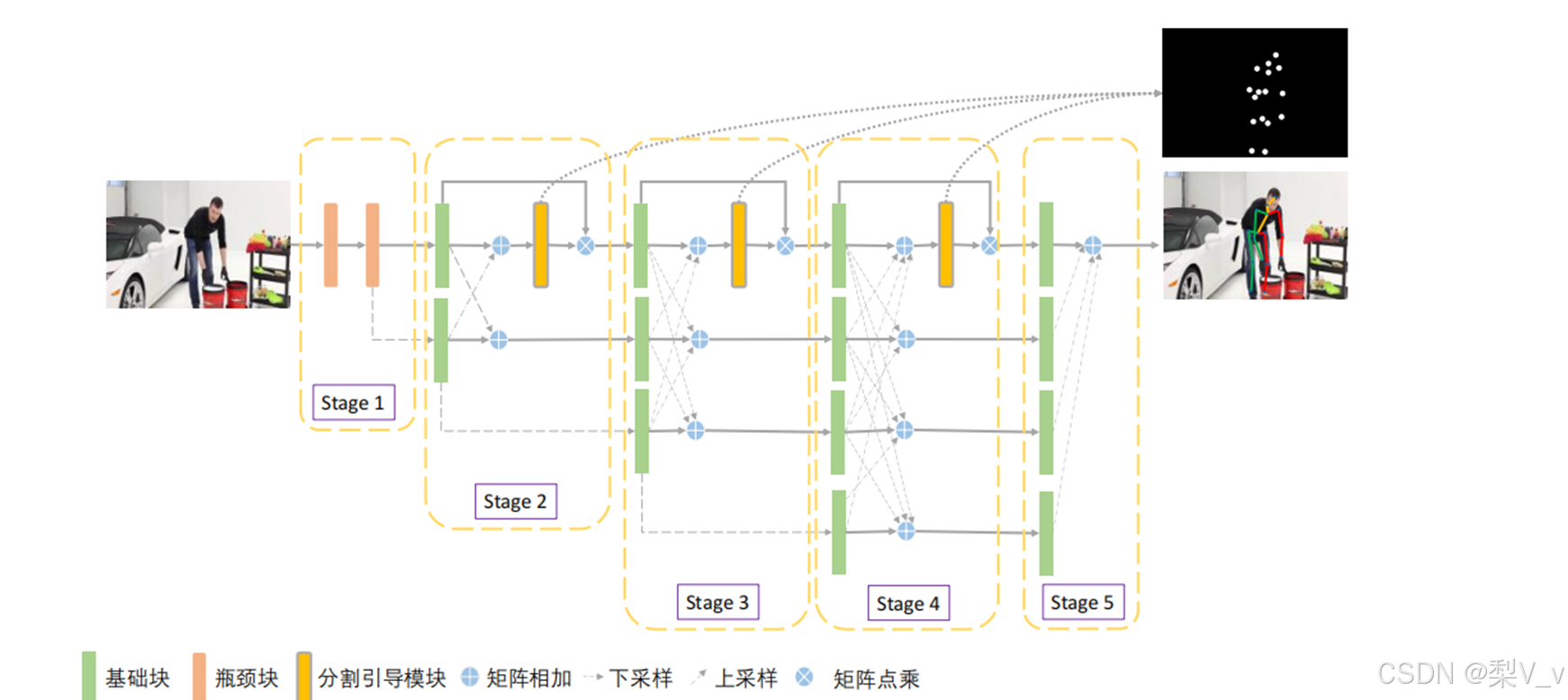
基于分割引导的深度高分辨率网络
主要思想
为扩展骨骼点标注的监督作用并降低背景区域对模型的干扰,提出了基于分割引导的深度高分辨率网络(Segmentation Guided High-Resolution Network, SG-HRNet)。首先设计分割引导模块来引导模型关注骨骼点区域,从而降低背景区域对预测结果的影响。除此之外,使用骨骼点标注产生的真值分割图监督分割引导模块的输出。最后,使用动态加权算法进行多任务训练。得到最终模型。
骨骼点标注
热力图完成使人体姿态估计任务
骨骼点标注生成的真值分割图可以为模型提供空间焦点
图像中人体第𝑖个骨骼点真值热力图和真值分割图的计算公式所示:


分割引导模块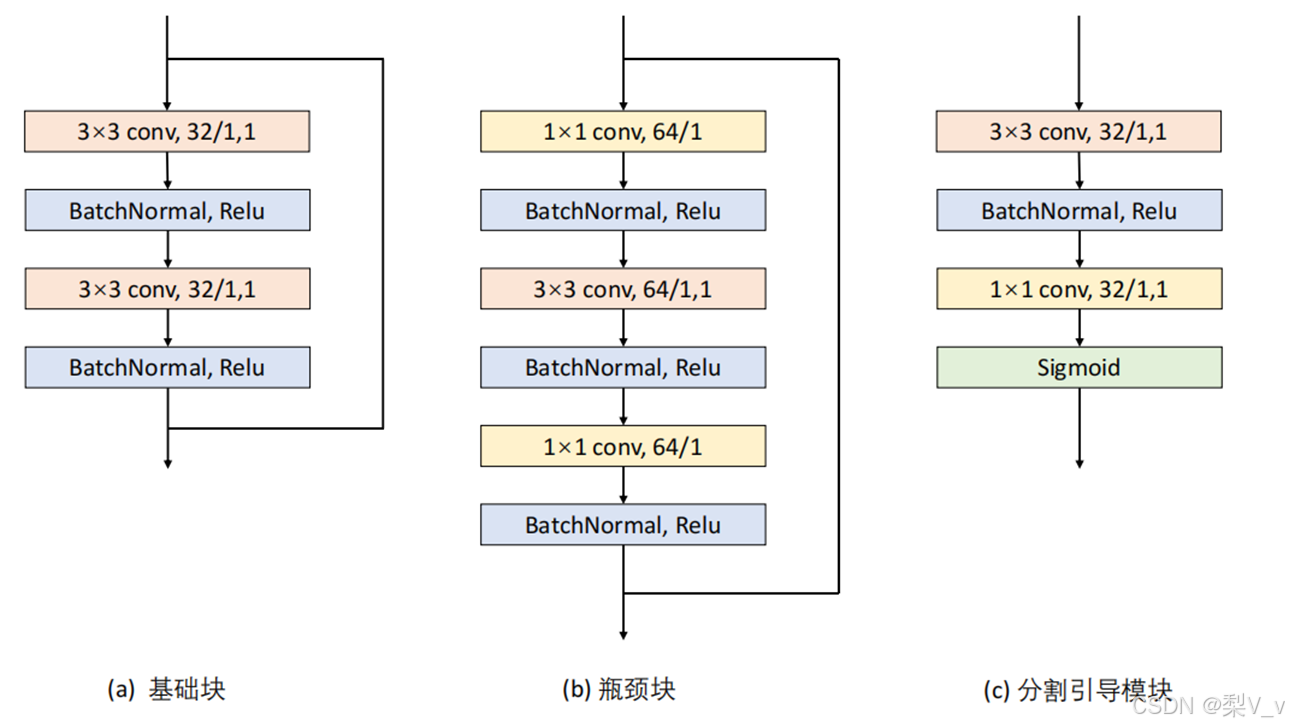
分割引导模块(Segmentation Guided Module, SGM)在真值分割图的监督下生成空间注意图。直观来说,图像中各区域对于任务的重要程度是不同的, 模型应重点关注任务相关区域,通过空间注意力机制找出图像的重要区域,可以 有效解决复杂背景干扰问题,从而提升模型最终效果。


基于动态加权的损失函数
模型的最终损失由两部分组成:分割损失与姿态估计损失
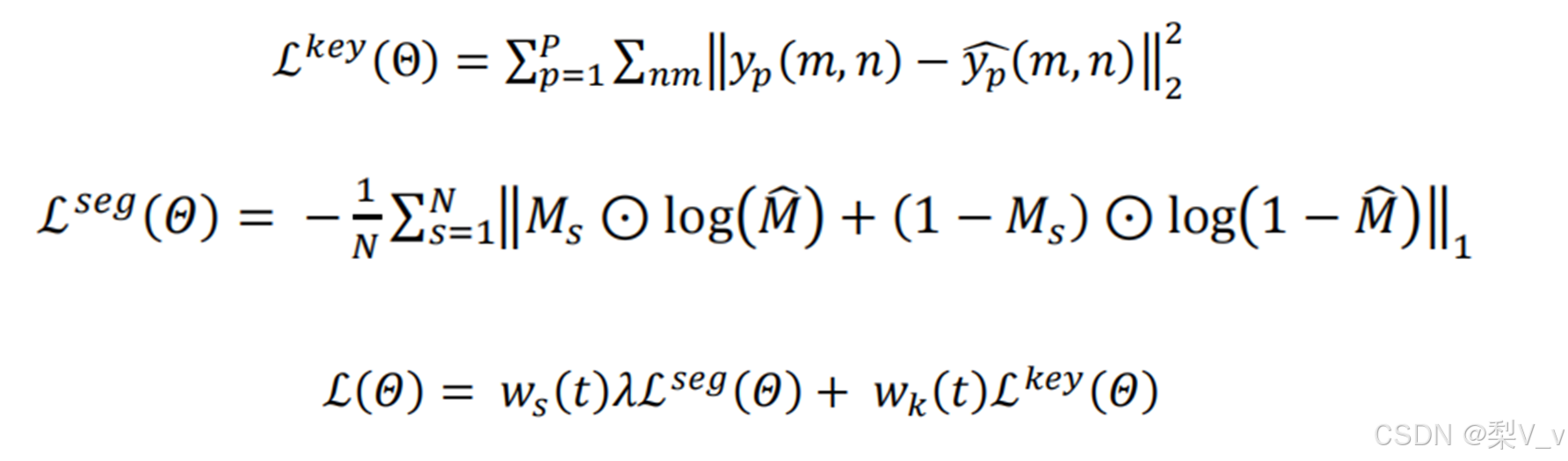
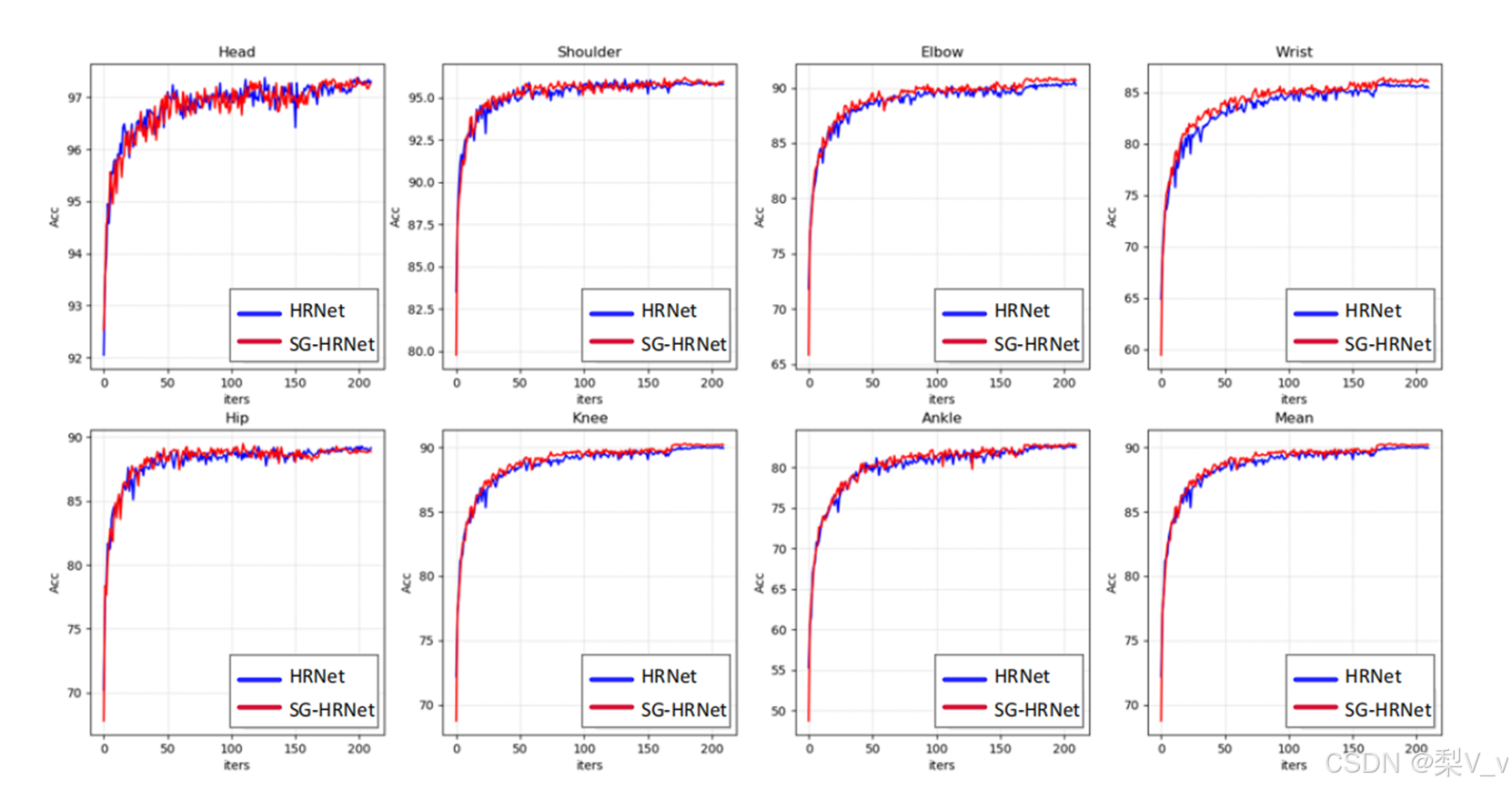
分割引导模块消融实验
基于多尺度子图的人体动作识别方法
主要思想
现有的基于 GCN 的模型大多选择串行堆叠更多的层来线性增加网络的感受野。但是叠加过多的层会增加模型的参数量甚至发生过拟合的问题。
基于以上分析,提出了基于多尺度子图并行预测图卷积网络的动作识别模型来解决上述问题。在该模型中,首先设计骨骼点采样模块,根据不同的融合策略产生三个不同尺度等级的骨架子图,骨架子图可以在不同尺度的空间划分中提供更大的感受野,有助于全局语义信息和局部运动信息的提取。在此基础上,构造三种图卷积块:局部图卷积块、基础图卷积块和全局图卷积块,提取不同尺度骨架子图的特征信息。最后,使用运动注意力模块在特征级别对运动信息进行建模,可以有效降低模型的计算成本。
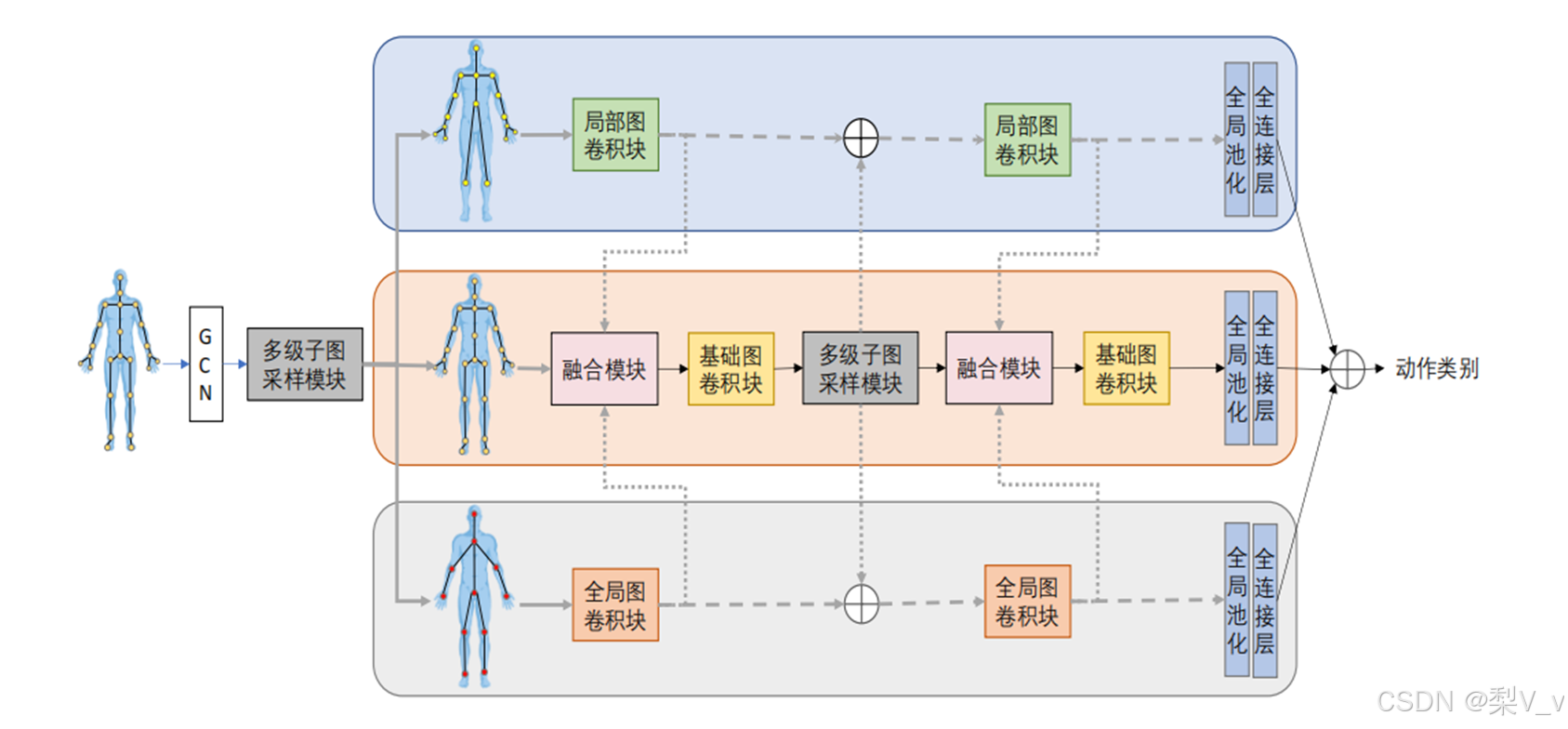
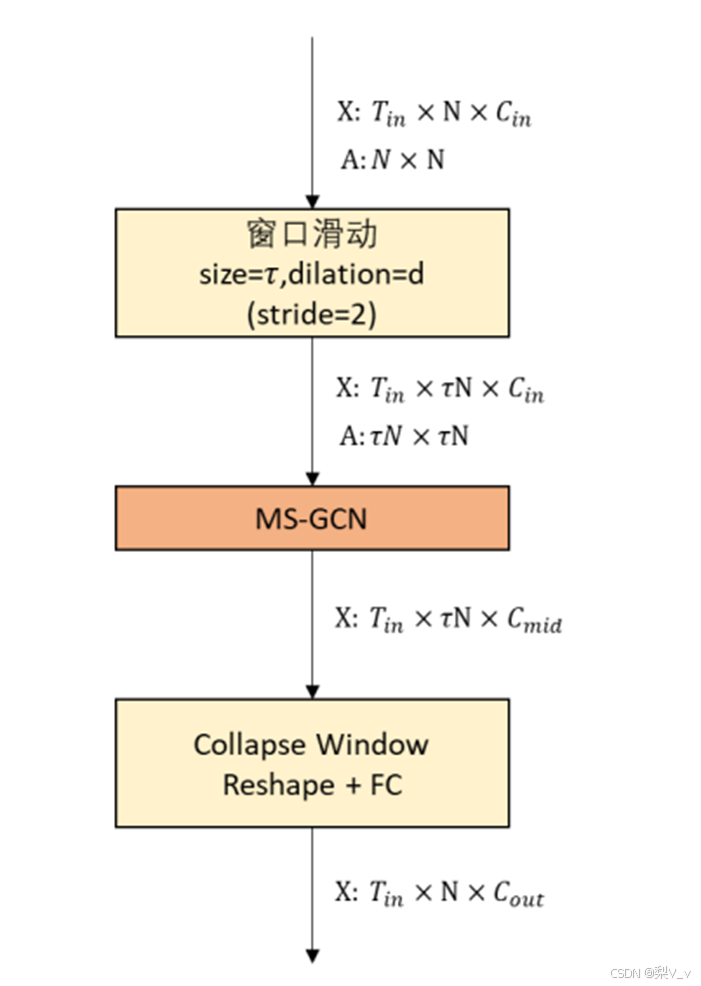
多级子图采样与融合模块
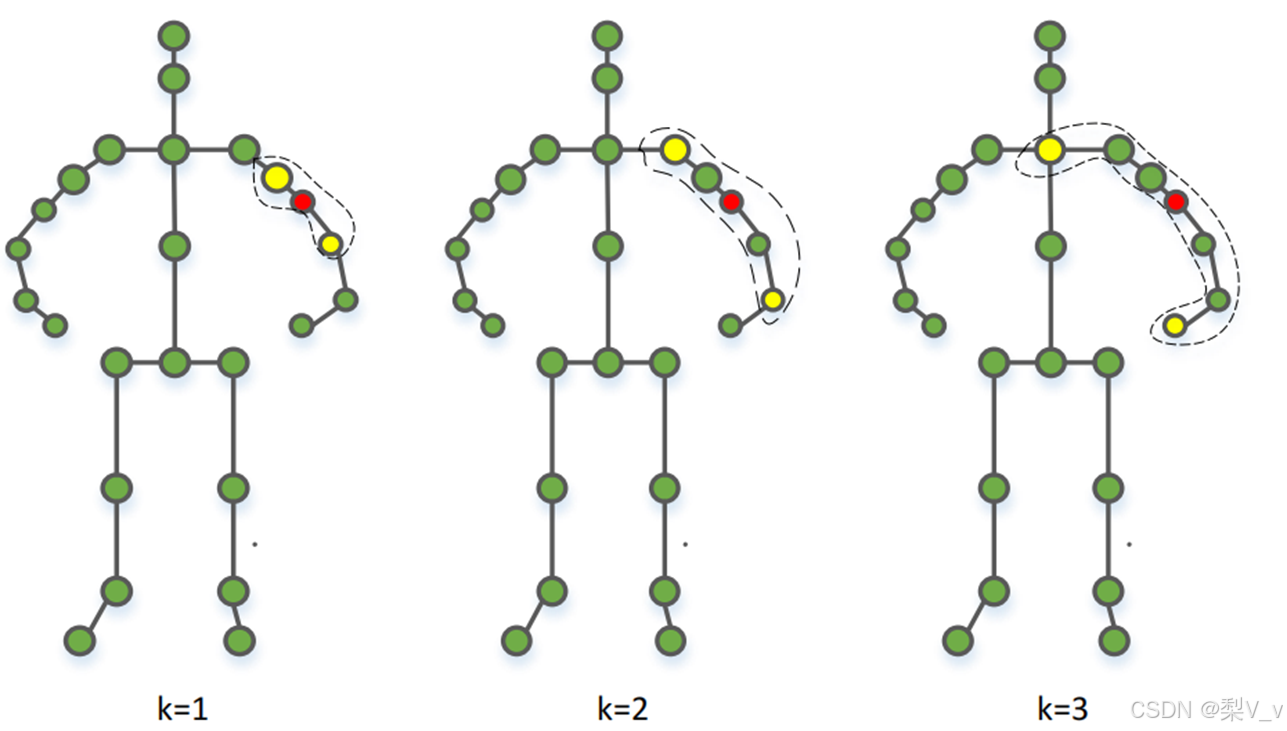
模型使用多级子图采样模块来实现对骨架图𝐺𝑛𝑜𝑟𝑚𝑎𝑙的高效归并操作从而产生两个尺度等级子图𝐺𝑙𝑜𝑐𝑎𝑙和𝐺𝑔𝑙𝑜𝑏𝑎𝑙。
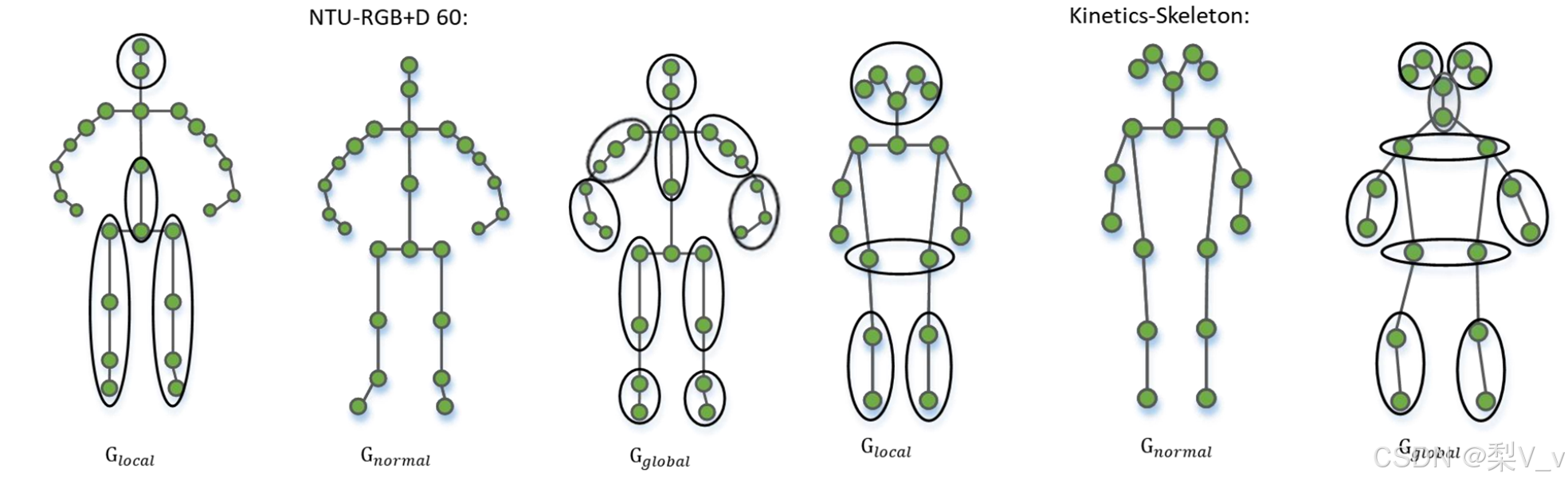
具体来说,多级子图采样模块首先根据人体自然骨骼关节的语义属性和渐进原则,将人体骨骼分割成若干个部件。然后,以权重和的方式合并骨架图中同一部件中的顶点。
部件𝒦中顶点合并操作:
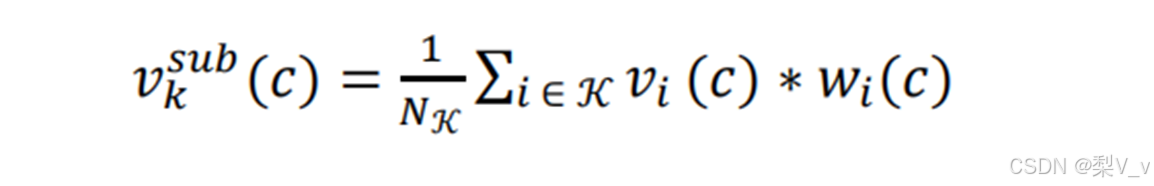
各尺度骨架子图所提取的特征融合操作:
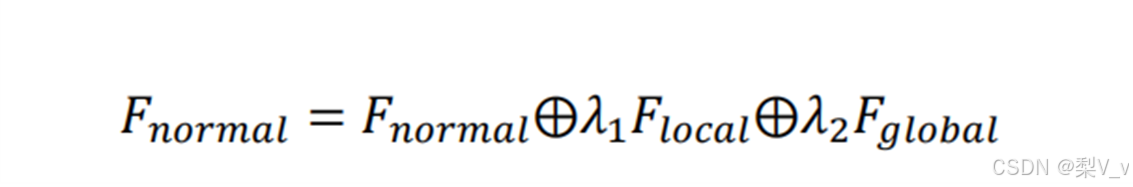
图卷积模块
多尺度图卷积(Multi-Scale Graph Convolutions , MS-GCN)结构图:

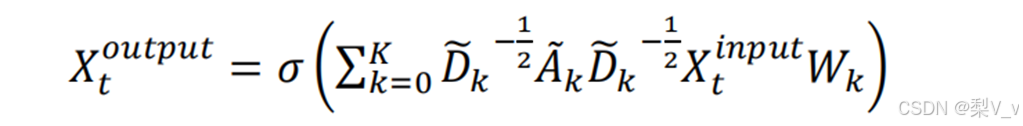
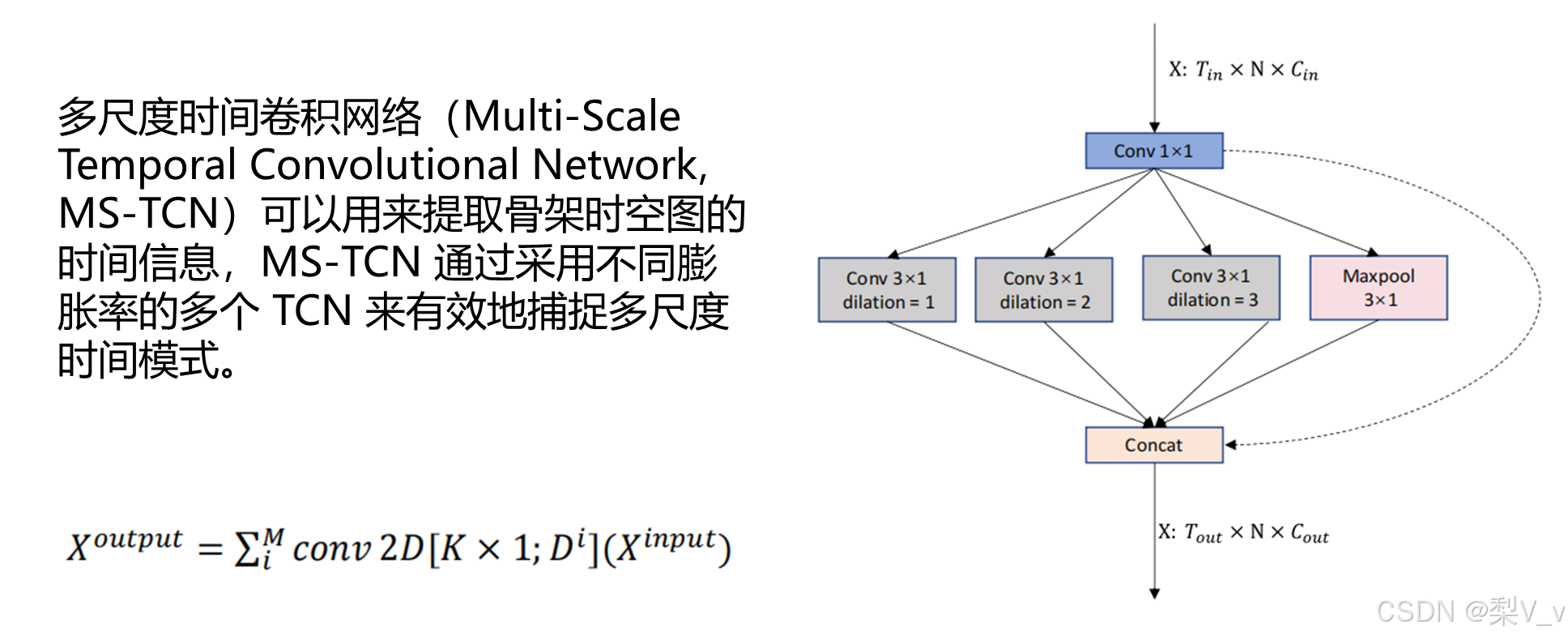
MS-G3D 采用空间和时间上的统一图形操作来同时捕获时间与空间的变化模式。
局部图卷积块重点关注手部骨骼点,基础图卷积块提取对适用于所有动作的特征信息,全局图卷积块提取人体各部分相互协调运动的全局特征信息。
最后,所有图卷积块头部添加特征级别运动注意力模块,建模特征级别的运动信息。
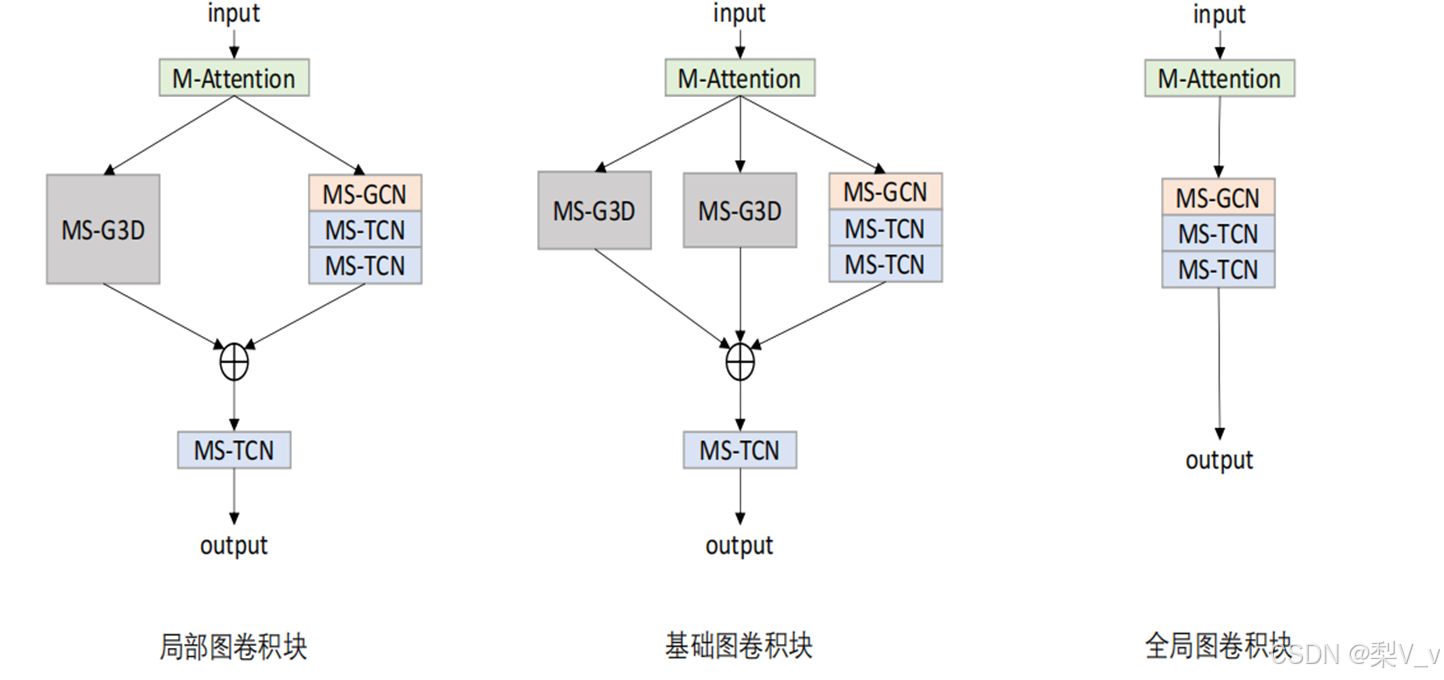
特征级别运动注意力模块
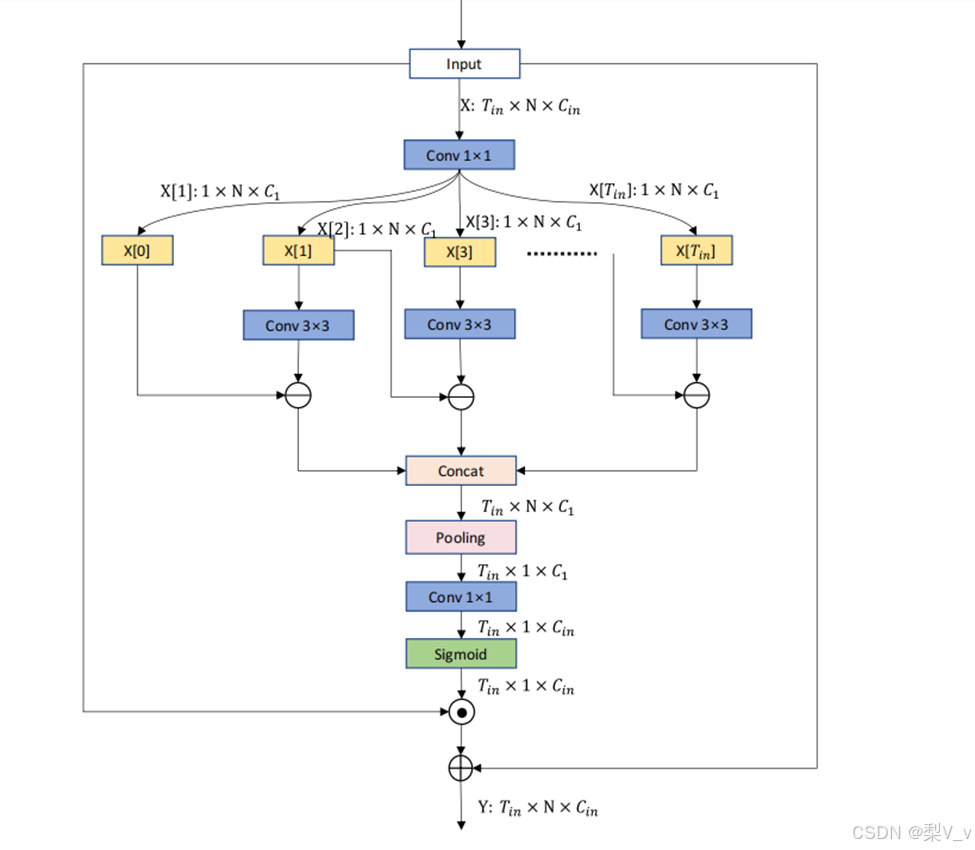
运动注意力模块(Motion Attention, M-Attention)旨在建模特征级别的运动信息。为此,M-Attention 首先生成运动掩码𝑀 然后将此与输入特征𝑋 进行骨骼点维度的哈达玛乘积运算。
消融实验
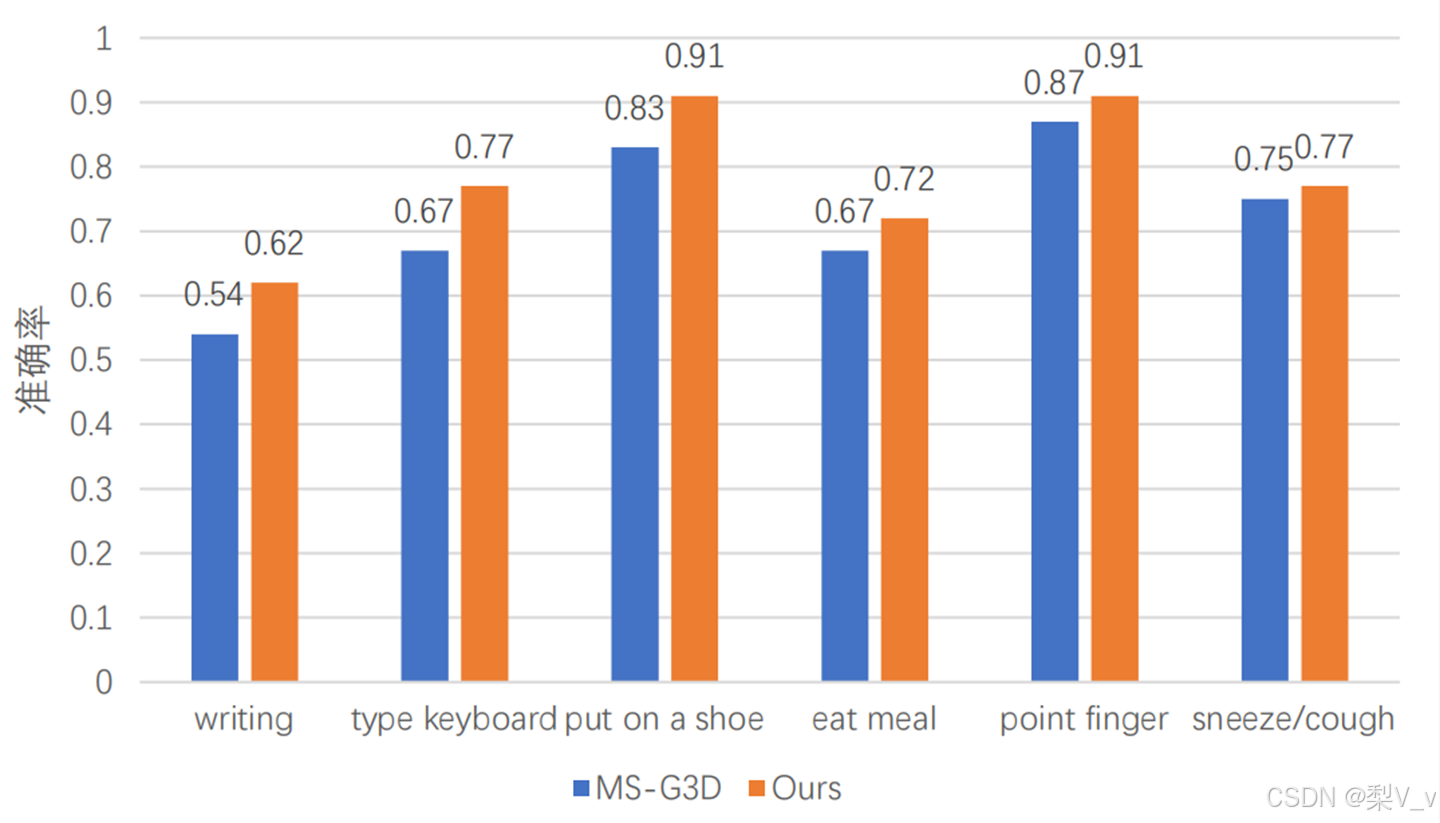
与 MS-G3D 对 NTU-RGB+D 数据集 X-Sub 中 6 种较难识别的动作进行了对比实验

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









