







1 前言
本文要是对《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》这篇论文的一个解读与总结,原文链接http://arxiv.org/abs/2103.14030
本文提出一种新型Transformer模型,Swin Transformer。它解决了将Transformer模型从语言调整到视觉任务的挑战。其中一个主要的挑战是两个领域之间的差异,例如视觉实体的规模和图像的分辨率。为了克服这些差异,Swin Transformer使用Hierarchical和Shifted window这两技术进行解决。
其中Hierarchical和Shifted window这两种方法为Swin Transformer提供了在各种尺度上建模和处理不同大小图像的灵活性,它还确保模型的计算时间复杂度与图像大小保持线性关系。
Swin Transformer的功能已经通过各种视觉任务进行了演示,可以作为一个代替CNN作为通用骨干使用,包括在图像分类、对象检测和语义分割任务上。它实现了很高的精度,并且经过多方面的比较,Swin Transformer大大优于以前的最先进的模型。
2 现已有研究存在的问题
计算机视觉中的建模长期以来一直由卷积神经网络(CNNs)主导。由于CNN作为各种视觉任务的主干网络,这些架构的进步导致了性能的改进,广泛提升了整个领域。由Transformer在语言领域的巨大成功促使研究人员研究它对计算机视觉的适应性,最近它在某些任务上展示了有希望的结果,特别是图像分类和联合视觉-语言建模。
将Transformer在语言领域的高性能转移到视觉领域的重大挑战可以用两种模式之间的差异来解释。
2.1 规模
与语言转换器中用作处理基本元素的单词标记不同,视觉元素的规模可能会有很大变化,这一问题在对象检测等任务中受到关注。
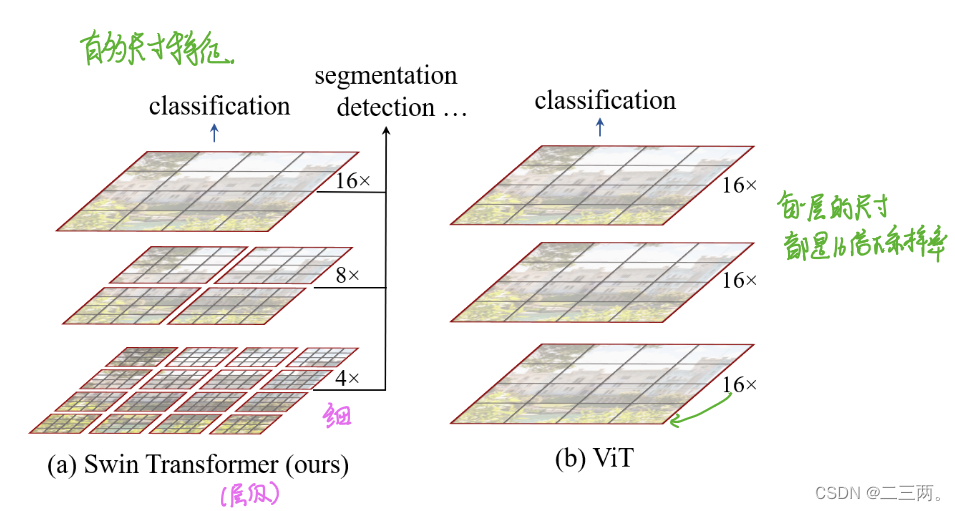
在下图中(a)表示Swin Transformer采用的是每层采用不同的下采样率得到多尺寸特征图,这使得Swin Transformer可以作为图像分类以及稠密识别任务的通用骨干。(b)表示ViT在实验过程中每层采用的都是16倍的下采样率,产生是单一的低分辨率的特征图。
2.2 分辨率
与文本段落中的单词相比,图像中的像素分辨率高得多。
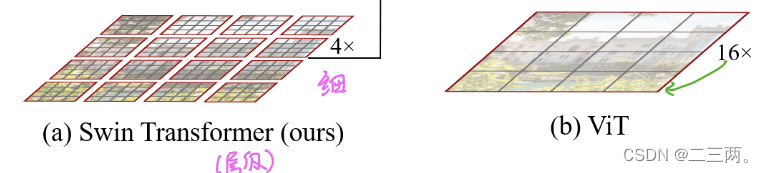
在下图中(a)表示Swin Transformer在每个局部窗口计算自注意力,时间复杂度与图像大小成线性关系,适合稠密任务(b)表示ViT始终对全局图像进行自注意力,时间复杂度为图像大小的平方,不适合稠密任务。
3 Swin Transformer
3.1 Self-attention in non-overlapped windows
由于传统Transformer是计算全局自注意力,具有时间复杂度过高这个问题,不能处理高分辨率图像。
本文提出在局部计算自注意力机制,将图像均匀划分成不重叠的patch(大小为M×M),然后再对每个patch采取自self-attention,从而达到降低时间复杂度的效果。
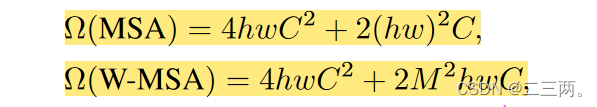
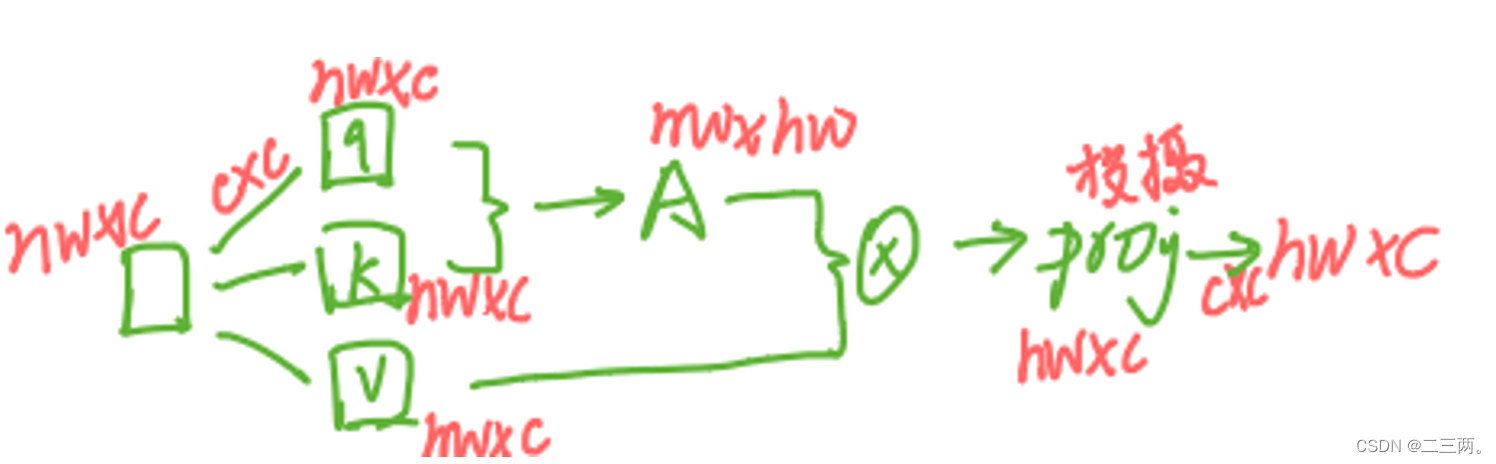
(1) 表示全局多头注意力机制的计算时间复杂度。
①输入原图像X, ,计算时间复杂度为
②计算 ,因为存在两次点积,计算时间复杂度为
③最后投影映射,计算时间复杂度为
所以总的时间复杂度为 。
(2)其中 表示窗口多头注意力机制的时间复杂度。
每个patch大小为M×M,则每个patch经过self-attention的计算时间复杂度为 ,一共有
个patch,所以它的总self-attention的时间复杂度为
。
与上面分析的类似,所以总的时间复杂度为 .
3.2 Shifted window partitioning in successive blocks
通过上面对图像进行划分成均匀patch,对每个patch进行局部self-attention降低时间复杂度。但是这样操作存在以下两个问题:①缺乏全局图像信息;②每个patch之间相互独立,失去每个patch之间的信息交互。
针对以上问题,本文引入cross-window connections,提出移位窗口分区方法,在这个方法中还需要保持每个局部窗口的不重叠。
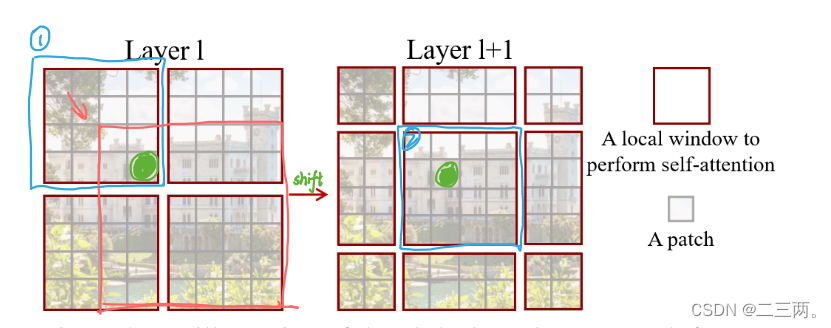
我们可以看到在上图中,每个红色框代表一个局部窗口,灰色框代表一个patch,cross-window connections表示经过一个Swin Transformer,往下移一半之后,原本属于第L层窗口1的patch现在在第L+1层中属于窗口2了实现了作者说的跨窗口连接,窗口与窗口之间进行了交互。
但是我们将他移动后会出现窗口大小不一的问题,简单办法是将小窗口填充成相同大小窗口块,但是这样也相应的提高了计算时间复杂度。本文作者提出一种有效的批处理方法,通过向左上方向循环移位。
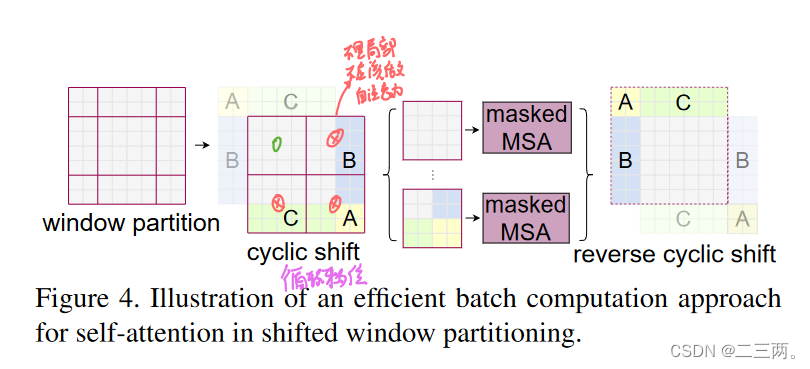
我们将经过循环移位后的每个块进行编号,以3,6块为例,先将3,6块拉直,然后两个矩阵进行相乘,得到矩阵,我们不需要36,63块进行自注意力(因为他们不是相邻块,没有局部关系),因此将他们的掩码都设为-100,与矩阵内结果进行相加,后面进行softmax时,里面的值将会变成0。
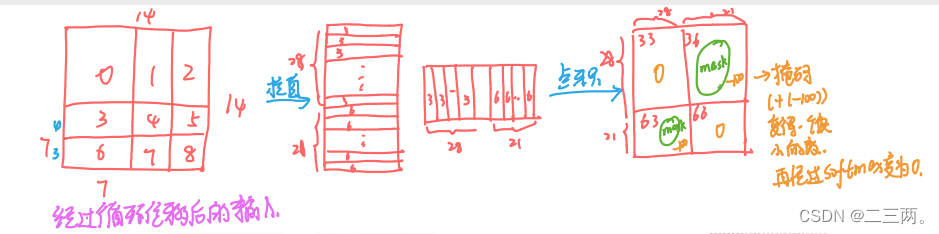
以下为作者提出的mask可视化:
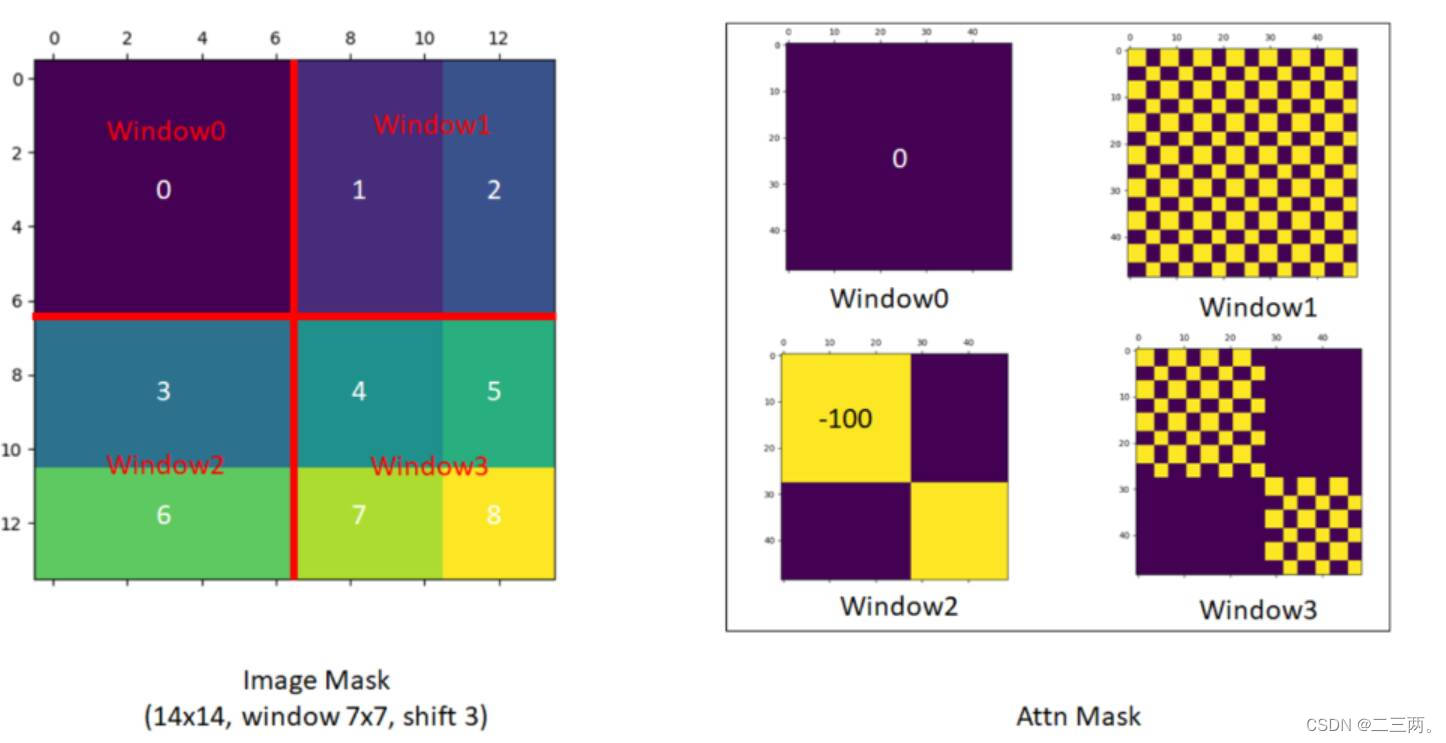
图片来源:swin transformer - 搜索 (github.com)
再配合后面提出的Path merging,合并到Swin Transformer的最后几层时,每个path的本身感受野就已经很大了,再加上移动窗口操作,每个path基本上是拥有全局的感受野。同时我们还是在局部窗口做的自注意力,减小了时间复杂度。
4 整体架构
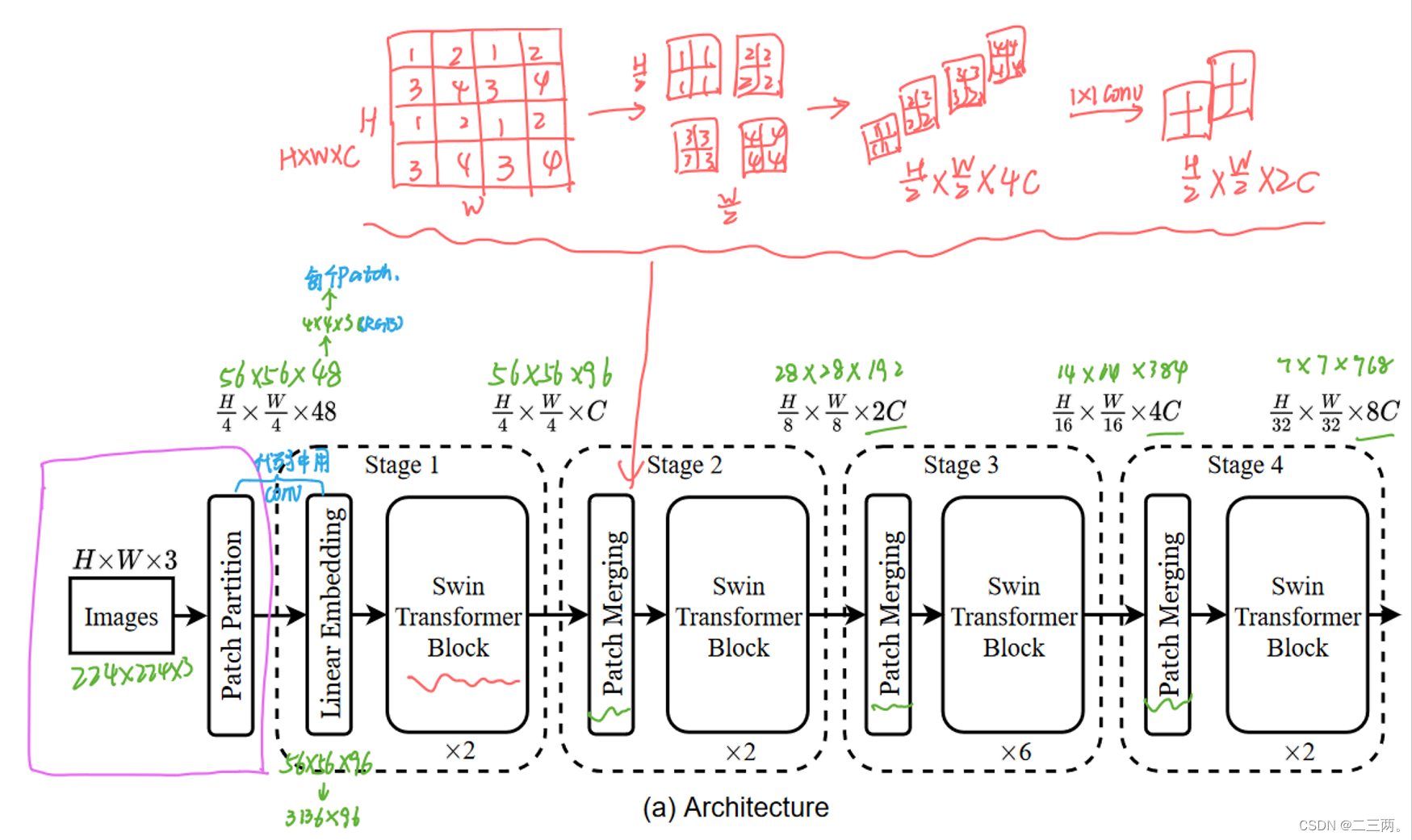 在上图中,
在上图中, 采用的时在C的维度上用一个1×1的卷积,将通道数降为2C。
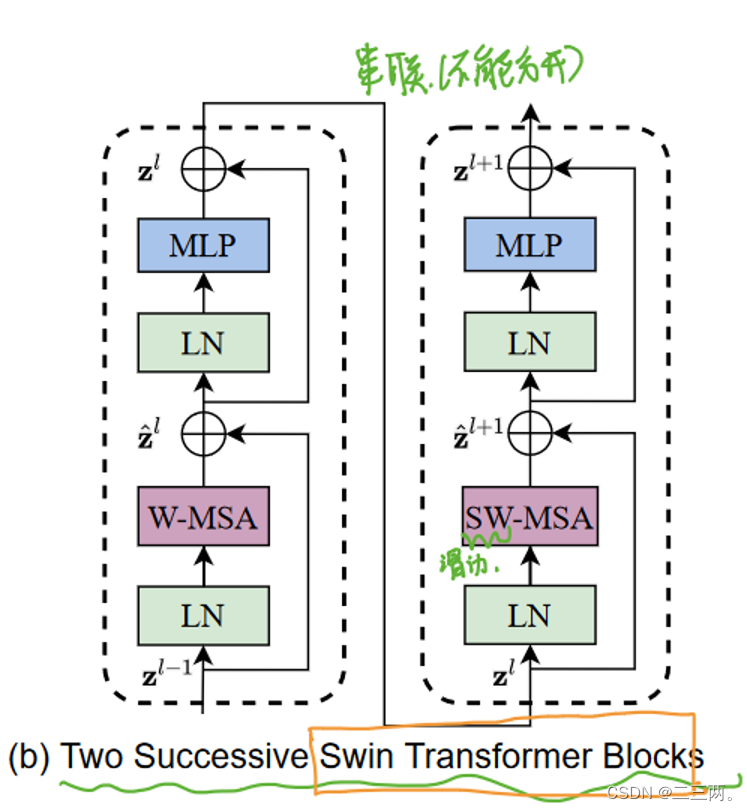
两个连续的Block架构如上图所示,我们在整体架构图中可以注意到每一次的Swin Transformer Block都是偶数个,因为需要交替包含Window Attention和Shifted Window Attention。
以上就是我对本片论文的一个理解,如有不当请指正!


















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











