语义标记与几何和辐射重建高度相关,因为具有相似形状和外观的场景实体更有可能来自相似的类。最近的隐式神经重建技术很有吸引力,因为它们不需要事先的训练数据,但同样的完全自监督方法对于语义来说是不可能的,因为标签是人类定义的属性。我们扩展神经辐射场(NeRF)来联合编码语义与外观和几何形状,以便使用少量特定于场景的就地注释来实现完整且准确的2D语义标签。 NeRF 内在的多视图一致性和平滑性通过使稀疏标签能够有效传播而有益于语义。当房间规模场景中标签稀疏或非常嘈杂时,我们展示了这种方法的好处。我们在各种有趣的应用中展示了它的优势特性,例如高效的场景标注工具、新颖的语义视图合成、标签去噪、超分辨率、标签插值和视觉语义映射系统中的多视图语义标签融合。
让智能代理(例如室内移动机器人)能够在其环境中规划上下文敏感的动作,需要对场景有几何和语义的理解。机器学习方法已被证明在几何和语义预测任务中都很有价值,但是当训练数据的分布与测试时观察到的场景不匹配时,这些方法的性能就会受到影响。尽管可以通过收集昂贵的注释数据或半监督学习来缓解这个问题,但在具有各种已知和未知类的开放集场景中并不总是可行。因此,拥有自我监督的方法是有利的。特别是,最近在使用特定于场景的方法(例如 NeRF [16])方面取得了成功,这些方法通过仅使用图像和相关相机姿势从头开始训练的神经网络来表示单个场景的形状和亮度。语义场景理解意味着将类标签附加到几何模型。估计场景的几何形状和预测其语义标签的任务是密切相关的,因为场景中具有相似形状的部分比那些差异很大的部分更有可能属于相同的语义类别。这已经在多任务学习的工作中得到了证明 [9, 33],其中同时预测形状和语义的网络比单独处理任务时的表现更好。
然而,与场景几何不同,语义类是人类定义的概念,不可能以纯粹自我监督的方式对新颖的场景进行语义标记。可以实现的最好方法是将场景的自相似结构聚类为类别;但总是需要一些标签来将这些集群与人类定义的语义类别相关联。在本文中,我们展示了如何设计用于联合几何和语义预测的特定于场景的网络,并在仅具有弱语义监督(并且没有几何监督)的单个场景的图像上对其进行训练。因为我们的单个网络必须同时生成几何图形和这些任务之间的相关性意味着,语义预测可以从几何图形自监督学习到的平滑性、一致性和自相似性中获益。此外,多视图一致性是训练过程的固有特性,它能使网络生成准确的场景语义标签,包括与输入集中的任何视图都大不相同的视图。 我们的系统将一组 RGB 图像和相关的已知相机姿势作为输入。我们还为图像提供了一些部分或有噪声的语义标签,如一小部分图像的地面实况标签,或更多图像的有噪声或粗糙标签图。我们对网络进行训练,以共同生成整个场景的几何和语义的隐式三维表示。 我们对 Replica 数据集[28]中的场景进行了定量和定性评估,并对 ScanNet 数据集[3]中的真实场景进行了定性评估。 从部分或嘈杂的输入标签中生成整个场景的密集语义标签对于实际应用非常重要,例如当机器人遇到一个新场景时,要么只有少量的现场标签可行,要么只有不完善的单视角网络可用。、
现有的大多数三维语义映射和理解系统都是通过将(融合)语义标签附加到由标准重建方法创建的三维几何表示上而工作的。例如,[6] 使用点云,[13] 和 [22] 使用曲面,[18] 使用体素,[12] 使用符号距离场。这些经典的三维几何表示法在有效表示复杂拓扑结构中的精细细节方面都有局限性。例如,体积表示法具有便于并行处理或与卷积神经网络一起使用的结构,但由于离散化而需要大量内存,最终限制了它所能表示的分辨率。
为了克服这些限制,人们开发了许多基于学习的表示法。例如,基于代码的表示法使用自动编码器的潜在代码作为场景的紧凑表示法。生成查询网络(GQN)[5] 可以使用潜在场景表示向量来表示简单的三维场景。CodeSLAM[1]在基于视图的视觉里程测量系统中使用紧凑且可优化的潜在代码来表示密集的场景几何。 SceneCode [35] 扩展了 CodeSLAM 的方法,使其包含语义。SceneCode 能够通过优化多帧之间的光度和语义标签的一致性,在推理时完善网络预测。不过,尽管使用深度图进行了训练,但 SceneCode 仍然是一种基于视图的表示法,缺乏对 3D 几何图形的真正认识。
最近,在使用神经隐式场景表征方面的研究大有可为。由于这些表征是连续的,因此可以轻松处理复杂的拓扑结构,而且不会出现离散化误差,实际的表征分辨率取决于所用神经网络的容量。场景表示网络(SRN)[25] 是最早使用多层感知器(MLP)作为给定图像和相关姿势集合的学习场景神经表示的方法之一。DeepSDF [19] 和 DIST [10] 使用深度解码器学习同一类别中各种形状实例的隐式符号距离函数,而 Occupancy Networks [15, 21] 则在三维监督下学习形状或大规模场景的隐式三维占用函数。 Kohli 等人[8]还建议在 SRN 的基础上,使用线性分割渲染器学习三维形状的外观和语义的联合隐式表示。在经过两步半监督方式的训练后,该网络可以根据颜色或语义观察结果合成新的视图语义标签。 上述方法需要在数据集合上进行大量的预训练,以学习有关它们用来表示的形状或场景的先验知识。虽然在不同的实例或场景中显示出了良好的泛化能力,但并不总能获得各种未见环境的足够数据。另一种选择是针对特定场景的表示方法,这种方法需要最少的就地标记工作。 NeRF [16] 和其他基于 NeRF 的系统 [34, 11, 31, 27] 使用 MLP 对来自单一有界场景的输入进行过拟合,并作为隐式体积表示法用于现实视图合成。在本文中,我们将 NeRF 视为一种强大的特定场景三维隐式表示法,并将其扩展到语义表示法,这种表示法可以从稀疏或嘈杂的注释中有效学习(图 1)。
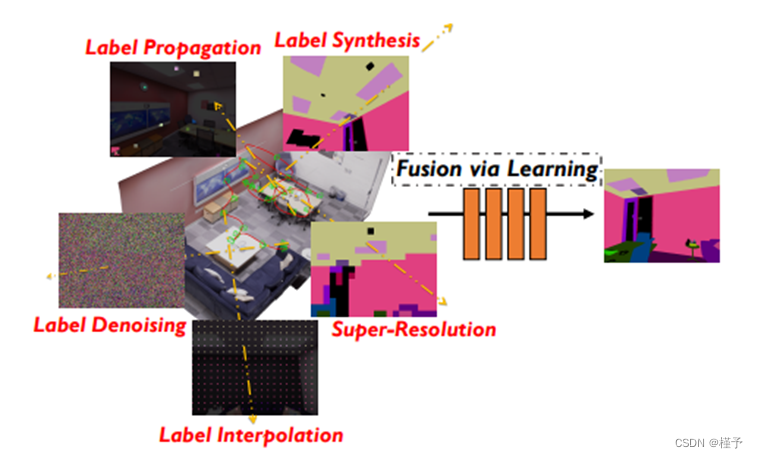
图 1:联合编码外观和几何的神经辐射场 (NeRF) 包含用于分割和聚类的强大先验。在此基础上,我们创建了特定场景的三维语义表示--Semantic-NeRF,并证明它可以通过就地监督进行高效学习,从而实现各种潜在应用。
NeRF [16] 利用 MLPs 将连续三维场景密度 σ 和颜色 c = (r, g, b) 隐式表示为空间坐标 x = (x, y, z) 和观察方向 d = (θ, φ) 的连续 5D 输入向量的函数。具体来说,σ(x) 仅是三维位置的函数,而辐射度 c(x, d) 则是三维位置和观察方向的函数。 为了计算单个像素的颜色,NeRF[16] 采用分层分层采样的数值正交法来近似体积渲染。在一个分层中,如果 r(t) = o + td是从摄像机空间投影中心发出的射线,穿过一个给定的像素点,并穿过近界和远界(tn 和 tf),那么对于在 tn 和 tf 之间选取的 K 个随机正交点 {tk} K k=1 ,其近似期望颜色为:
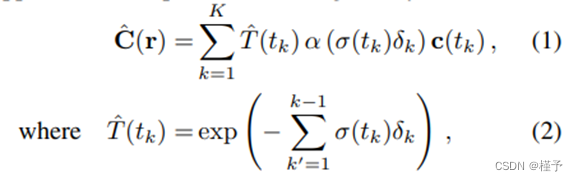
其中,α (x) = 1 - exp(-x),δk = tk+1 - tk 是相邻两个正交采样点之间的距离。 给定观测场景的多视角训练图像后,NeRF 使用随机梯度下降法 (SGD) 通过最小化光度差异来优化 σ 和 c。
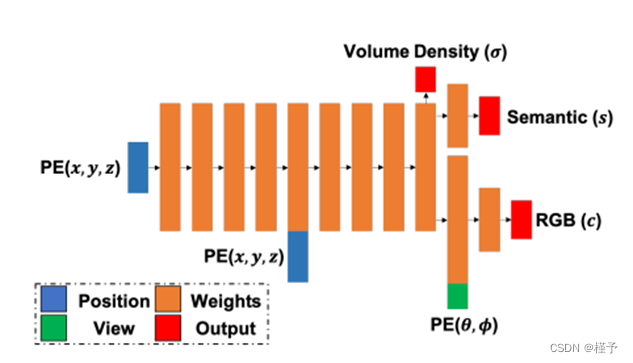
图 2:语义-NeRF 网络架构。三维位置(x、y、z)和观察方向(θ、φ)在位置编码(PE)后输入网络。体积密度 σ 和语义对数 s 是三维位置的函数,而颜色 c 则取决于观察方向。
现在,我们将展示如何扩展 NeRF,以联合编码外观、几何和语义。如图 2 所示,我们在将观察方向注入 MLP 之前,通过添加一个分割渲染器来增强原始 NeRF。 我们将语义分割形式化为一种固有的视图不变函数,该函数通过预软最大语义对数 s(x)将世界坐标 x 映射到 C 语义标签的分布上:
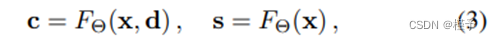
其中,FΘ 代表学习到的 MLP。
图像平面中给定像素的近似预期语义对数 Sˆ(r)可写成:
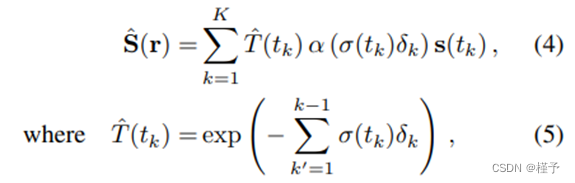
α (x) = 1 - exp(-x),δk = tk+1 - tk 是相邻样本点之间的距离。然后,语义对数可通过软最大归一化层转化为多类概率。
在光度损失 Lp 和语义损失 Ls 的条件下,我们从头开始训练整个网络。
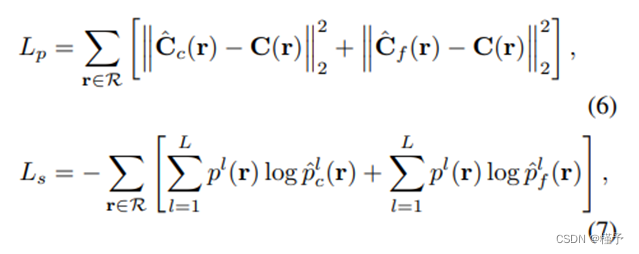
其中,R 是训练批次中的采样射线,C(r)、Cˆ c(r) 和 Cˆ f (r) 分别是射线 r 的地面实况图、粗体预测图和细体预测图的 RGB 颜色。同样,p l、pˆ l c 和 pˆ l f 分别是光线 r 的地面实况图、粗体预测图和精细体预测图中 l 类的多类语义概率。 Ls 被选为多类交叉熵损失,以鼓励渲染的语义标签与所提供的标签保持一致,无论这些标签是地面实况、噪声还是部分观测数据。因此,总训练损失 L 为:
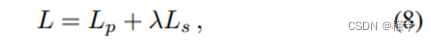
其中,λ 是语义损失的权重,设置为 0.04 以平衡两种损失的大小[8]。在实践中,我们发现实际性能对 λ 值并不敏感,将 λ 设为 1 可获得相似的性能。这些光度和语义损失自然会促使网络从底层联合表示生成多视角一致的二维渲染。
通过为每个场景单独从头开始训练网络,可以获得特定场景的语义表示。我们使用与 [16] 类似的设置和超参数。 具体来说,我们使用分层体积采样来共同优化粗略网络和精细网络,前者提供重要性采样偏差,后者可以将更多样本分配到可能可见的位置。长度为 10 和 4 的位置编码[32, 30]分别应用于三维位置和观察方向。此外,由于我们没有深度信息,因此我们将光线采样的边界分别设置为 0.1 米和 10 米,而没有对室内场景进行仔细调整。 在所有实验中,训练图像的大小均调整为 320x240。我们在 PyTorch [20] 中实现了模型,并在配备 11GB 内存的单个 RTX2080-Ti GPU 上进行了训练。由于内存限制,射线的批量大小设置为 1024。 我们使用adam优化器[7]训练神经网络,学习率为 5e-4,迭代次数为 200,000 次。
在对彩色图像和带有相关姿势的语义标签进行训练后,我们获得了特定场景的隐式三维语义表征。我们通过将三维表征投射回二维图像空间来定量评估其有效性,在二维图像空间中,我们可以直接获取明确的地面实况数据。我们旨在展示高效学习这种用于语义标注和理解的联合三维表示法的益处和应用前景。我们恳请读者在项目网页 In-Place Scene Labelling and Understanding with Implicit Scene Representation 上查看更多定性结果。
Replica: Replica [28] 是一个基于重构的三维数据集,包含 18 个高保真场景,其中有密集的几何图形、HDR 纹理和语义注释。我们使用 Habitat 模拟器[23],从随机生成的类似手持摄像机运动的 6-DOF 轨迹中渲染 RGB 彩色图像、深度图和语义标签。我们沿用 SceneNet RGB-D [14] 的程序,并锁定滚动角度,使摄像机的向上矢量沿 Y 轴指向。 在特定场景实验中,我们使用 Replica 提供的 88 个语义类别,并在第 4.4 节中按照 ScanNet [3] 的映射约定,将这些标签手动映射到流行的 NYUv2-13 定义 [24, 4],以进行多视角标签融合。对于每个由房间和办公室组成的复制场景,我们使用水平视场角为 90 度的默认针孔摄像机模型,以 640x480 的分辨率渲染了 900 幅图像。我们从序列中每隔 5 个帧取样,组成训练集,并对中间帧取样,组成测试集。
ScanNet:ScanNet[3]是一个大规模的真实世界室内RGB-D视频数据集,包含1513个场景中的250万个视图,具有丰富的注释,包括语义分割、摄像机姿势和表面重构。我们仅使用提供的彩色图像、摄像机姿势和二维语义标签在 ScanNet 场景上训练 SemanticNeRF。每个场景中的序列都是均匀采样的,因此训练数据的总量大约为 300 帧。在实验过程中,我们选择了几个室内房间规模的场景,并使用来自 NYUv2-40 定义的姿势图像和语义标签对每个场景训练一个 Semantic-NeRF。
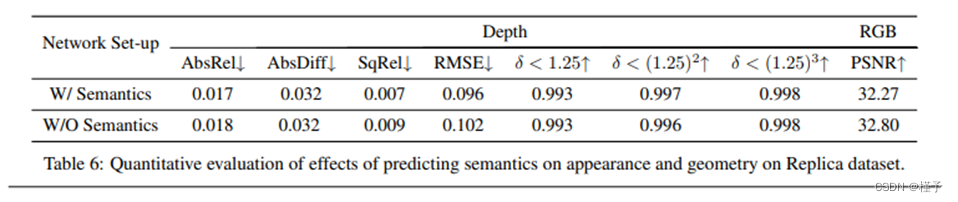
我们通过定量计算在启用和未启用语义预测功能的 Replica 场景上渲染的 RGB 图像和深度图的质量,来检验语义对外观和几何的影响。实验表明,两者并无明显差异,这表明当前的网络有能力联合学习这些任务。
需要注意的是,我们可能会认为大量高质量的语义标注信息可以提高重建质量,但在本文中,我们关注的是在语义标注稀少或嘈杂的相反情况下,几何如何帮助语义学。
我们首先利用随机生成的特定场景序列中所有带有相机姿势和相应语义标签的可用 RGB 图像(即 180 幅图像),训练我们的语义-NeRF 框架,以实现新颖的视图语义标签合成。这种完全监督的设置是在有大量标注训练数据的情况下,Semantic-NeRF 语义分割性能的上限。
然而,在实践中,为场景中所有观察到的图像获取精确的密集语义注释既昂贵又耗时。考虑到重叠帧间语义标签的冗余性,我们借鉴了 SLAM 系统中关键帧的概念,并假设只为选定帧提供标签就足以高效地训练语义表示。我们通过从序列中均匀抽样来选择关键帧,并只使用来自这些选定关键帧的语义标签从头开始训练网络,而合成性能则始终在所有测试帧上进行评估。
图 3 和图 4 验证了我们的假设,即可以从稀疏注释中高效地学习语义,稀疏率从 0% 到 95% 不等,同时还有相应的摄像机运动基线作为补充说明。当使用的语义帧少于 10%时,仅会出现微小的性能损失,这主要是由于关键帧中未观察到或被遮挡的区域的渲染造成的。为了更进一步,我们从每个场景中手动选择两个关键帧(稀疏率为 99%),以尽可能多地覆盖场景。事实证明,我们的网络仅使用两个标记的关键帧进行训练,就能从不同视角提供准确的标记。
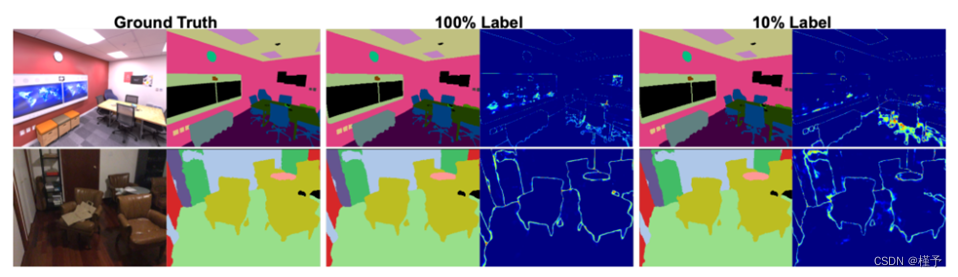
图 3:测试姿势下的合成语义标签,在训练过程中分别使用了 100% 和 10% 的地面实况标签。从左到右,我们分别展示了作为参考的地面真实颜色和语义图像,以及在 100% 和 10% 监督下渲染的语义标签及其信息熵。熵图中明亮的部分与相应训练设置中的物体边界或模糊/未知区域非常吻合。
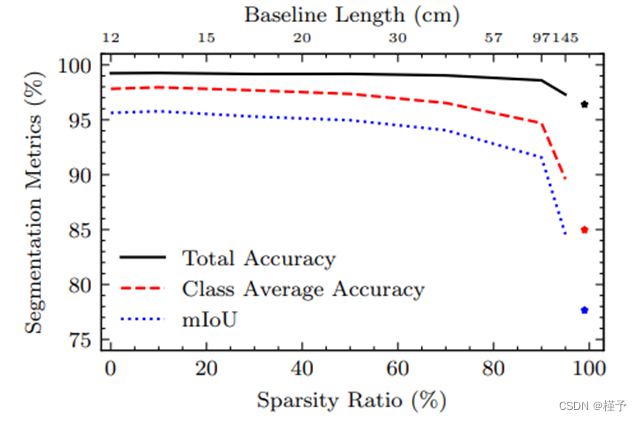
图 4:在具有稀疏语义标签的 Replica 上训练的 Semantic-NeRF 的定量性能。稀疏率是指与完整序列监督相比丢帧的百分比。使用三个标准指标来评估测试姿势的语义分割性能(越高越好)。由于未覆盖或被遮挡的区域,标签数量越少,性能下降越慢,这表明可以通过较少的注释进行高效的密集标记。只有两个标记关键帧(*)的结果显示了极具竞争力的性能。
4.4. 语义融合
除了能够利用语义标签中存在的冗余来学习稀疏注释的语义表示之外,Semantic-NeRF 的另一个重要特性是,语义标签之间的多视角一致性得到了加强。 在语义映射系统(如 [29, 13, 18])中,多个二维语义观察结果被整合到三维地图或目标帧中,以产生更加一致和准确的语义分割。多视角一致性是语义融合的关键概念和动机,Semantic-NeRF 的训练过程本身就可以看作是一个多视角标签融合过程。给定多个有噪声或不完整的语义标签,网络可以将它们融合到一个联合的隐式三维空间中,这样我们就能在以下情况下提取出去噪标签我们会将学习到的语义标签重新渲染回输入的训练帧。 我们展示了 Semantic-NeRF 在多种不同情况下进行多视角语义标签融合的能力:像素标签噪声、区域标签噪声、低分辨率密集或稀疏标签、部分标签,以及使用不完善的 CNN 的输出。
具有像素噪声的标签我们通过添加独立的像素噪声来破坏真实的训练语义标签。具体来说,我们在每个训练帧中随机选择固定的一部分像素,并将其标签随机翻转为任意标签(包括无效类别)。在仅使用这些噪声标签进行训练后,我们通过渲染回相同的训练姿势来获得去噪语义标签。
图 5 显示了标签去噪的定性结果。 当 90% 的训练像素被随机翻转,甚至人类都很难识别场景的底层结构时,去噪后的标签仍能保留准确的边界和细节,尤其是精细结构。与图 3 相比,这项去噪任务的熵值更高,因为噪声训练标签缺乏干净标签的多视角一致性。此外,空洞类区域的不确定性往往最高,因为在训练过程中没有对空洞区域的噪声像素进行优化。表 1 所示的定量结果也证实了 "边融合边训练 "可以获得准确的去噪标签。
虽然像素去噪的破坏程度如此严重并非现实应用,但这仍然是一项极具挑战性的任务,更重要的是,它凸显了我们的主要观点,即训练本身就是一个融合过程,通过隐式联合表征的内部一致性,可以获得连贯的渲染效果。

图 5:语义去噪的定性结果。即使 90% 的训练标签都是随机损坏的,我们也能恢复准确的去噪语义图。从左到右依次为噪声训练标签、训练后根据相同姿势渲染的去噪标签以及信息熵。 我们在去噪任务中看到的整体高熵表明,噪声训练标签之间存在很大的不一致性。
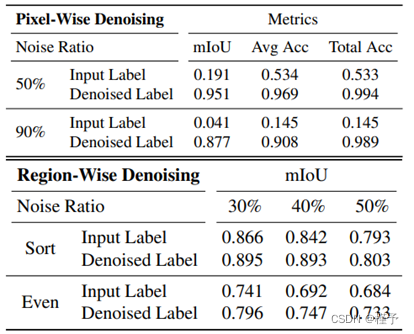
表 1: 对 Replica 标签去噪的定量评估。mIoU 用于区域去噪,因为它对场景中椅子类别的错误预测更为敏感。两个表格都是根据干净的训练标签计算的。
具有区域噪声的标签我们通过在标签图中随机翻转某些整体实例(而不是像素)的类别标签,进一步验证了语义一致性的有效性。这可以更好地模拟真实的单视角 CNN 的行为,因为从受阻或模糊的视角看,整个物体很容易被标记为相似但不正确的类别。 我们选择包含 8 个椅子实例的复制房间 2 作为测试场景。对于每个椅子实例,我们计算占用面积比(即属于该实例的像素数与图像中每个地面实况标签帧的像素总数之比),然后根据占用面积比对序列中的标签图进行排序。有两个标准用于选择其中的帧随机扰动每个实例: (1) 排序: 选择占用面积比最小的标签图。这样做的直觉是,由于上下文模糊不清,有部分观察结果的帧更容易被语义标签预测网络误标。(2) 均匀: 从排序序列中均匀选择标签图,引入更多的大面积不一致。将帐篷区域纳入训练过程。
图 6 显示了训练后重新渲染语义标签的定性结果。我们确实观察到,由于在训练过程中执行了多视角一致性,椅子实例的语义标签可以得到修正。 表 1 还显示,标签的质量在稳步提高,而当更多标签受到扰动时,要渲染出改进的标签就会变得更加困难。

图 6:当我们随机改变椅子实例的训练语义类别标签(蓝色)时,呈现标签的定性结果。从左至右:带有区域性噪声的训练标签;从相同姿势渲染的恢复语义标签;以及信息熵,突出显示带有噪声预测的区域。
语义标签超分辨率也是场景标签的一项有用应用。在增量实时语义映射系统中,可以采用轻量级 CNN 预测低分辨率语义标签,以降低计算成本(例如 [17])。另一个可能的用例是场景标注工具,因为在粗糙图像中手动标注效率更高。
在这里,我们表明,我们可以只用低分辨率语义信息来训练 Semantic-NeRF,然后为输入视点或新视角呈现准确的超分辨率语义。如图 7 所示,我们测试了两种不同的生成低分辨率训练标签的策略,即使用插值和不使用插值。例如,在缩放因子 S = 8 的情况下:
(1) 将所有地面实况标签从 320×240 缩放到 40 × 30,然后再缩放回原始尺寸;使用近邻插值法确定像素大小。
(2) 除了来自低分辨率标签图(行和列除以 8)的像素外,所有像素都被无效类屏蔽,从而不会造成训练损失。
方法(1)使用插值标签为采样射线批提供 "密集 "监督,但会错误地插值某些像素,而方法(2)提供稀疏但几何精确的标签。我们在表 2 中报告了所有复制场景中 S = 8 和 S = 16 两种比例的训练姿势的超分辨率性能。图 1 和图 7 显示了通过融合许多低分辨率或稀疏注释的语义帧来恢复详细语义信息的一些示例。 在语义标签去噪和超分辨率方面取得的可喜成果证明了联合表示外观、几何和语义的主要优势之一:任何一帧中缺失或损坏的语义标签都可以通过融合许多其他帧来纠正。 我们将在下一节更详细地探讨这一特性。

图 7:超分辨率:我们仅使用低分辨率标签(稀疏采样或插值)来训练 Semantic-NeRF,并通过从相同姿势重新渲染语义来获得超分辨率标签。请注意,为了便于可视化,稀疏标签被放大了 4 倍,并叠加在彩色图像之上。
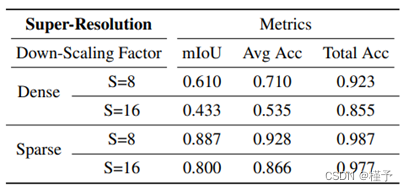
表 2: 标签超分辨率的定量评估,无论是采样标签还是插值低分辨率标签,都有良好的表现。mIoU 指标表明,稀疏但几何精度高的标签对高分辨率下的精细结构更有帮助。
我们的超分辨率实验表明,Semantic-NeRF能够从低分辨率注释中插值出丰富的细节。对于一款实用的场景标注工具来说,用户以点击或划痕的形式提供的直接标注是可取的,并且希望这些稀疏的点击能够扩展和传播,从而准确而密集地标注场景。
为了模拟用户注释,我们在标签图中的每个类别中随机选择一个连续的子区域来应用地面实况标签,而其他区域则不贴标签。图 8 和表 3 中的结果表明,从每个类别的单个像素进行监督,可以得到令人惊讶的高质量渲染标签,并能很好地保留全局和精细结构。当有更多监督时,物体边界会逐渐细化,而更多标签带来的增量改进也会趋于饱和。

图 8:分别使用帧内每个类别的单像素、1% 或 5%像素的部分注释进行标签传播的结果。出于可视化目的,即使是放大 9 倍的单击也能获得准确的标签。
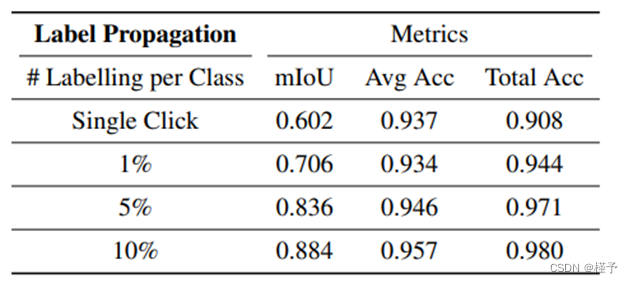
表 3:使用测试姿势对复制场景的标签插值和传播进行评估。即使是单像素监督也能在准确度指标上取得有竞争力的表现,这突出表明了该表示法在交互式场景标注方面的有效性。
我们已经证明,语义表征可以从稀疏或有噪声/部分监督中学习。在此,我们进一步验证了它在使用 CNN 预测进行多视角语义融合方面的实用价值。 目前已有几种经典的像素语义融合方法 [6, 13, 12],用于整合来自多个视角的单目 CNN 预测,以完善分割。为了进行公平比较,我们在此将多视角融合方法从此类系统中分离出来。两种基准技术是 贝叶斯融合:将多类标签概率相乘,然后重新归一化(例如 [13]);平均融合:简单地取所有标签分布的平均值(例如 [12])。
为了准备 Replica 数据集的训练数据,我们为每个 Replica 场景渲染了两个不同的序列,以覆盖场景的各个部分。每个序列包括从 900 个大小为 640×480 的渲染中均匀采样的 90 个帧,并将语义标签重新映射为 NYUv2-13 类别惯例。 我们选择以 ResNet-101 为骨干的 DeepLabV3+ [2] 作为单目标签预测的 CNN 模型。 为了生成合适的单目 CNN 预测并避免过度拟合,我们在 SUN-RGBD [26] 上训练 DeepLab,然后使用所有 Replica 场景的数据对其进行微调,但用于训练 Semantic-NeRF 和标签融合评估的场景除外。我们重复这一微调过程,为每个测试场景训练一个单独的 DeepLab CNN 模型。 测试场景的单目 CNN 预测用于两个目的:(1)我们特定场景 Semantic-NeRF 模型的训练监督;(2)基线多视图语义融合方法的单目预测(每像素密集软最大概率)。我们使用摆好姿势的彩色图像和 CNN 预测的标签对 Semantic-NeRF 进行 200,000 步的训练,然后将融合后的语义标签重新渲染回训练姿势,作为融合结果。 值得注意的是,两种基线融合技术都需要深度信息来计算帧间的密集对应关系,而我们的技术只需要图像。我们在表 4 中报告了所有测试场景的平均性能,其中两种基线方法都使用了地面实况深度图来代表 "最佳情况"。我们的方法在所有指标上都取得了最高的改进,这表明了我们的联合表示法在标签融合中的有效性。
我们已经证明,将语义输出添加到特定场景的几何和外观隐式 MLP 模型中,意味着在只有部分、噪声或低分辨率语义监督的情况下,也能为场景生成完整的高分辨率语义标签。这种方法可实际应用于机器人或其他需要在新场景中理解场景的应用中,因为在新场景中只能进行有限的标注。 未来研究的一个有趣方向是交互式标注,即持续训练网络要求提供最能解决整个场景语义模糊问题的新标签。
本文中的研究得到了戴森科技有限公司的支持。支帅峰获得了国家留学基金委-帝国奖学金。我们非常感谢 Edgar Sucar、Shikun Liu、Kentaro Wada、Binbin Xu 和 Sotiris Papatheodorou 富有成效的讨论。
与主论文第 4.2 节相对应,表 6 显示了在启用和未启用语义的情况下,将 Replica 场景投影到 2D 时的光度和几何重建质量的量化结果。我们发现这两种设置之间没有明显差异。峰值信噪比(PSNR)用于衡量渲染彩色图像的质量,用于评估 2D 深度图的指标如表 5 所示。

表 5:深度指标的定义:n 为有效深度像素的数量,d 和 dgt 分别为测试姿态下的渲染深度和地面实况深度。
在使用现场标注训练语义-NeRF 后,我们还可以从学习的 MLP 中提取显式三维场景,以检查隐式三维表示。首先在场景的密集三维网格上查询 MLP,然后应用行进立方体提取几何网格。在体积渲染过程中,将网格中顶点的负法线方向视为光线行进方向,从而渲染出附加的语义纹理。我们在图 9 中展示了三个复制房间场景的定性结果。

图 9:使用 Semantic-NeRF 获得的语义三维重建。请注意,我们学习到的特定场景三维表示法可以预测隐蔽区域的几何形状和语义,并在一定程度上填补了未观察区域造成的漏洞。
在预测体积密度之前,三维位置的轴对齐位置编码(PE)被输入到具有 256 个神经元和 ReLU 激活的第一和中间全连接(FC)层。在合并输入的观察方向后,使用带有 128 个神经元的附加 FC 层来处理视图不变语义和视图相关辐射。 位置编码 L 的长度与使用的最大频率有关,并影响渲染质量。在标签传播任务中,我们发现只使用低频分量(L = 5)会导致二维渲染过度平滑,而使用高频分量(L = 40)则会导致插值噪声,这与最近文献[16, 30]的研究结果一致。根据经验,L = 10 的效果最好。
D. 更多定性结果
图 10、图 11 和图 12 分别展示了语义视图合成、标签去噪和超分辨率的定性结果。 我们恳请读者观看我们在项目页面 Shuaifeng Zhi Semantic-NeRF 上的补充视频,该视频重点介绍了在各种情况和应用中语义渲染的准确性和一致性。


























 9655
9655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









