







前言
需求概述:我有两个模态的数据集,这两个模态的数据集是一一对应的,即文件名相同。数据集格式如下,我想要将两个模态的图片一一对应打包在一起。
然后在输入模型之前,取出其中一个模态传入模型()训练。
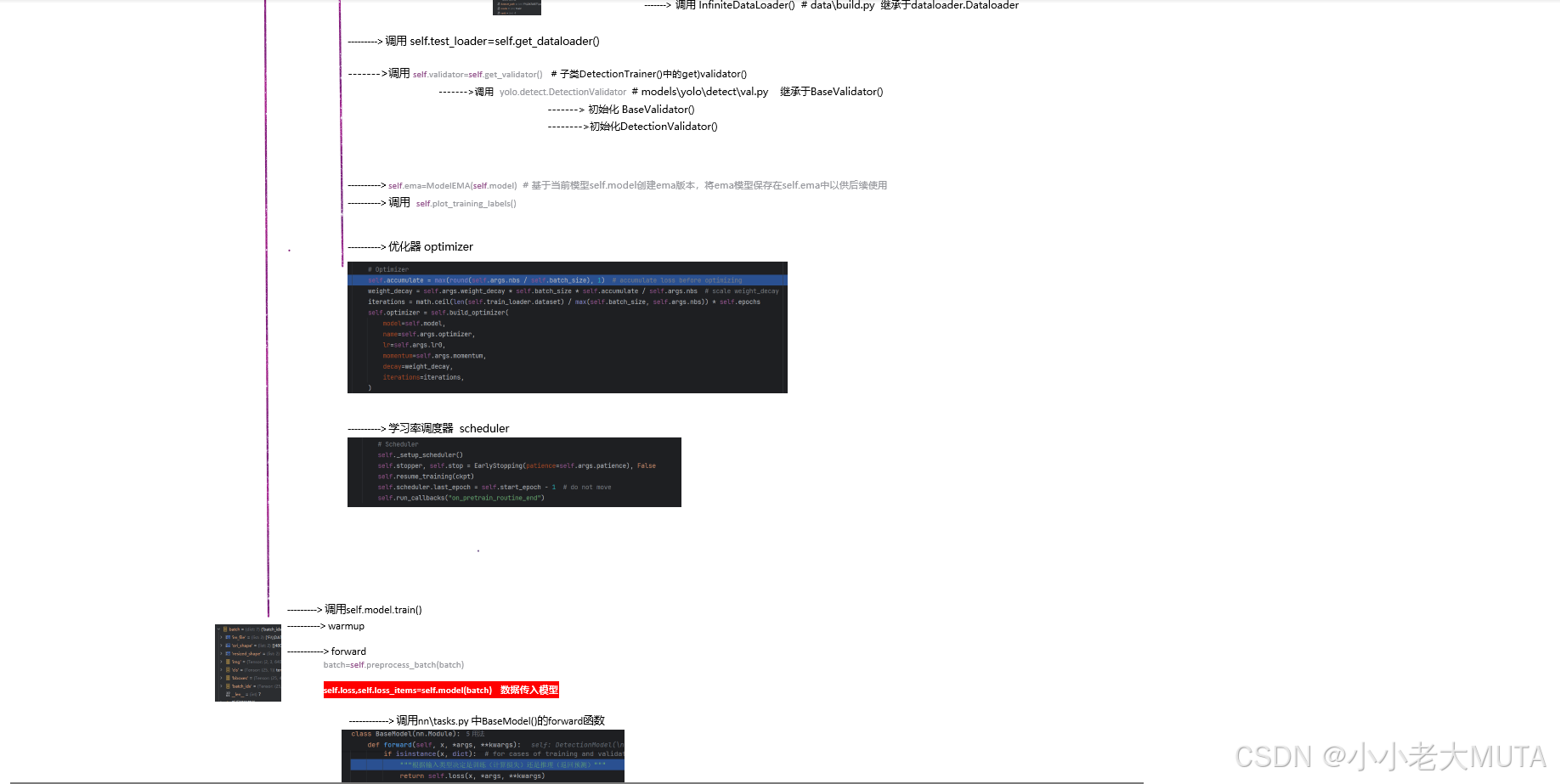
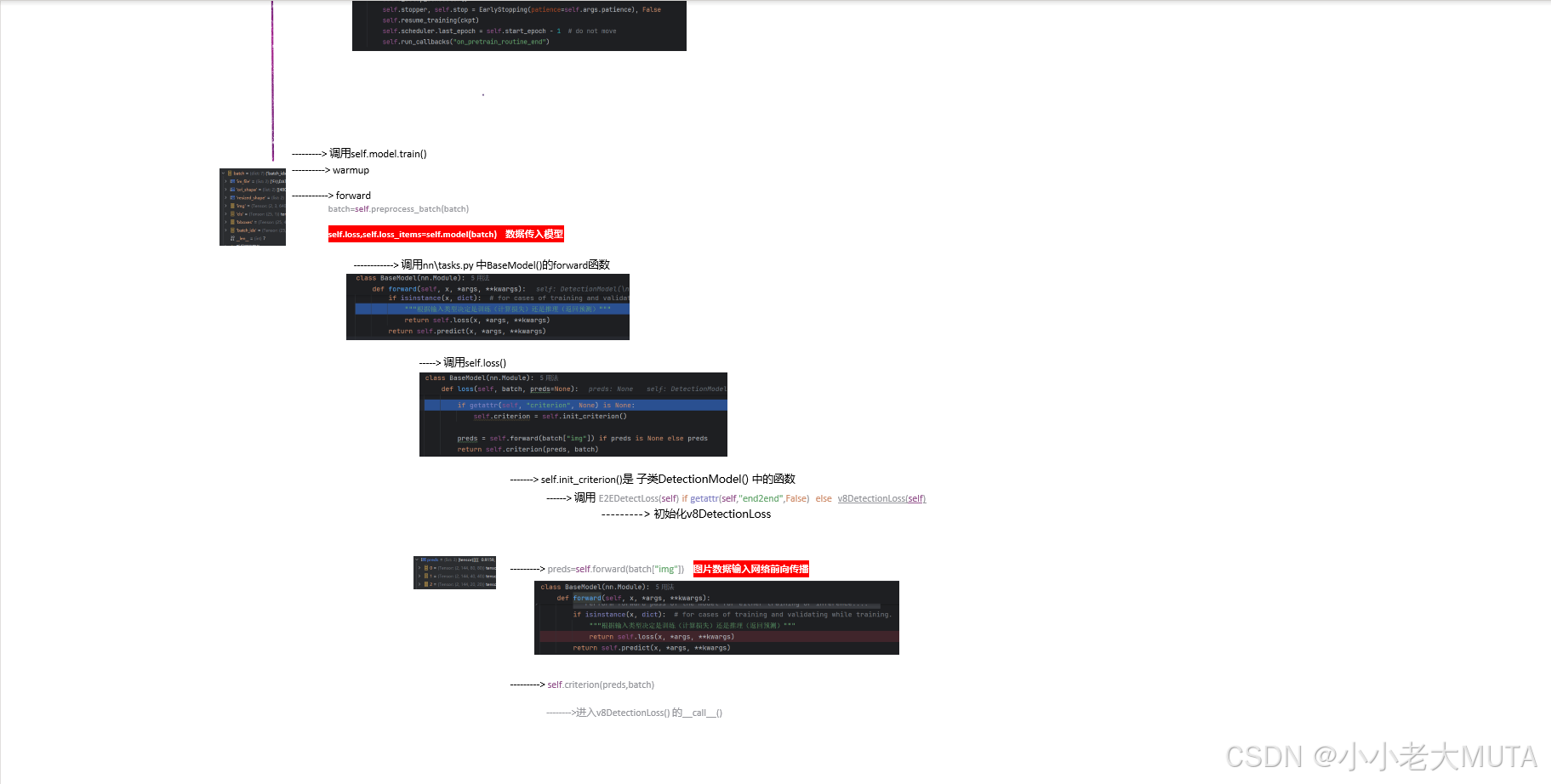
YOLO的U版代码封装了很多层,不容易找到dataset 和 dataloader的加载地方,下面是YOLO检测的训练流程,建议先浏览。

一、dataset
检测Detection的dataset入口在ultralytics/models/yolo/detect/train.py的build_dataset中。我们可以新建一个build_dataset的函数来替换掉这里的build_yolo_dataset。
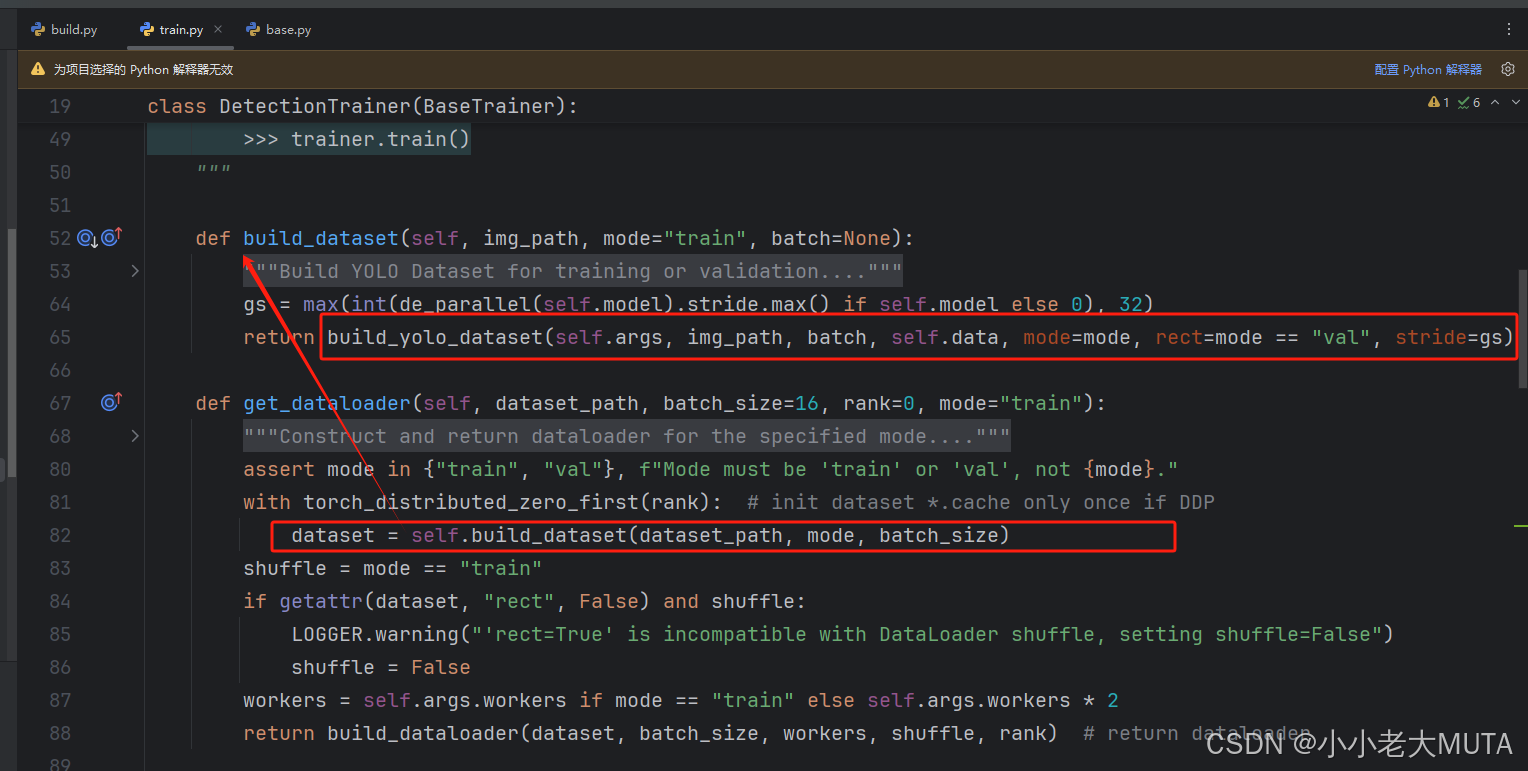
1.1 替换build_yolo_dataset函数
原来的build_yolo_dataset函数在ultralytics/data/build.py中。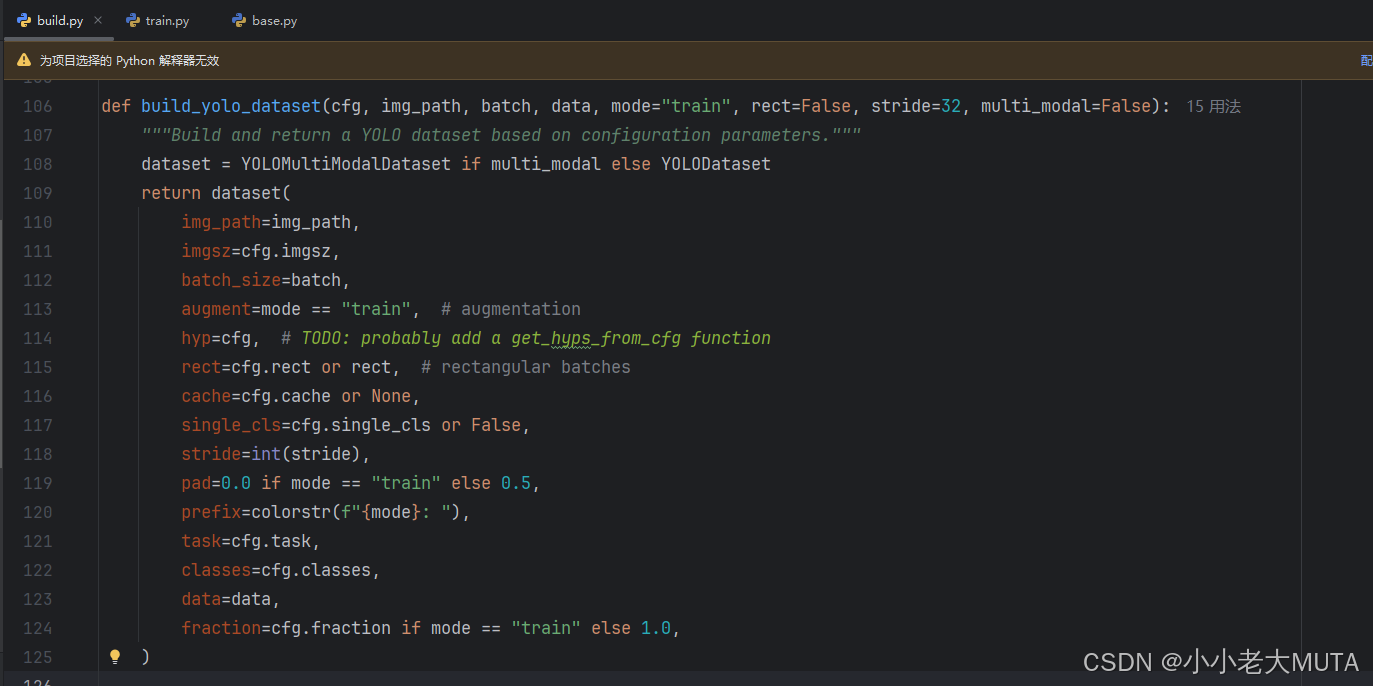
在ultralytics/data/build.py中新建一个build_rgbs_dataset()函数,需要重新创建一个自己的dataset类(RGBSDataset),然后return 的时候实例化这个类。

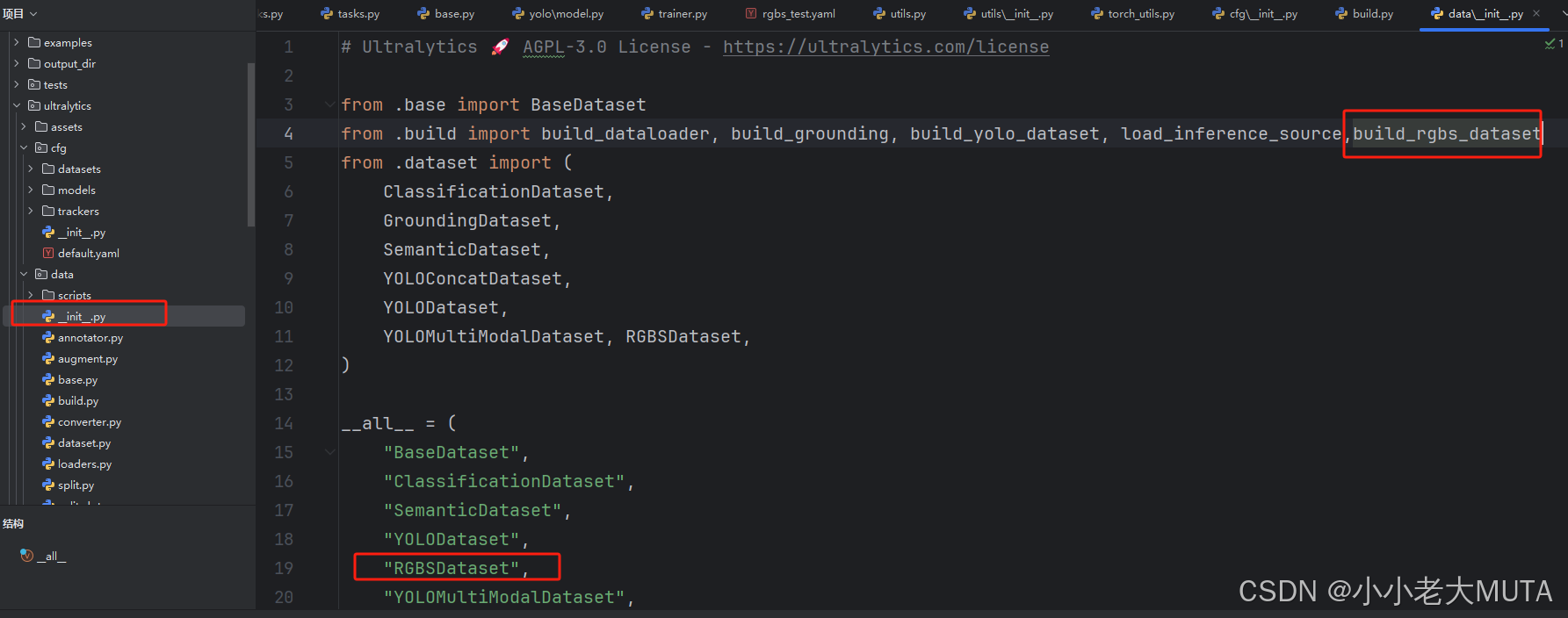
记得在ultralytics/data/dataset.py创建完RGBSDataset以后,在build.py文件开头import 这个类
![]()
在ultralytics/models/yolo/detect/train.py 开头import build_rgbs_dataset函数
![]()
1.2 改写YOLODataset
我们自己的dataset类 (RGBSDataset) 需要参考 YOLODataset(ultralytics/data/dataset.py),而YOLODataset 其实是 BaseDataset(ultralytics/data/base.py)的子类,复写了他的函数扩展了部分功能。
(详情请看这篇博客:Ultralytics中的YOLODataset和BaseDataset-CSDN博客)
所以我们也可以在YOLODataset() 的相同文件下,新建一个RGBSDataset()类,并且继承BaseDataset(), 然后针对部分功能复写或者拓展。
注意要在dataset的同级目录下的__init__.py文件中添加我们新建的类。
1.2.1 __init__初始化
关键是需要传入两个模态的图片和标签路径的根路径或者直接单独分别传入。
① 加载
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











