







 超级会员免费看
超级会员免费看
 本文提出了一种多大型语言模型(LLM)协商框架,用于情感分析任务,以克服单轮输出的局限性。通过推理增强生成器、解释派生鉴别器以及多轮协商机制,实现了更精确的情感决策。实验表明,这种方法在多个数据集上提高了准确度,尤其是在多LLM协商和引入第三个LLM解决分歧时,性能得到提升。
本文提出了一种多大型语言模型(LLM)协商框架,用于情感分析任务,以克服单轮输出的局限性。通过推理增强生成器、解释派生鉴别器以及多轮协商机制,实现了更精确的情感决策。实验表明,这种方法在多个数据集上提高了准确度,尤其是在多LLM协商和引入第三个LLM解决分歧时,性能得到提升。
Sentiment Analysis through LLM Negotiations
https://arxiv.org/abs/2311.01876![]() https://arxiv.org/abs/2311.01876
https://arxiv.org/abs/2311.01876
1.概述
在情感分析任务中,传统的单一大型语言模型(LLM)通常只通过单轮输出来做出决策。这种方法的主要缺点是无法完美应对需要深入推理的复杂语言现象,如从句构成、反讽等。即便是在较为简单的情况下,单轮输出也可能因为缺乏足够的上下文理解而导致决策失误。
为了克服这些限制,本论文提出了一个多LLM协商框架,通过以下三个核心组件实现更为精确和深入的情感分析:
-
推理增强生成器:该生成器不仅产出情感决策,还提供决策背后的推理链,增强了生成器在情感分析中的解释能力和准确性。
-
解释派生鉴别器:鉴别器的角色是评估生成器输出的可信度,并提供评估的理由。这一过程帮助识别和修正生成器可能产生的错误或偏差。
-
多轮协商机制:两个LLM(生成器和鉴别器)通过迭代对话直至达成共识。这种协商过程模拟了人类决策中的理性讨论,通过不断的相互质疑和逻辑推理,提升了决策的整体质量。
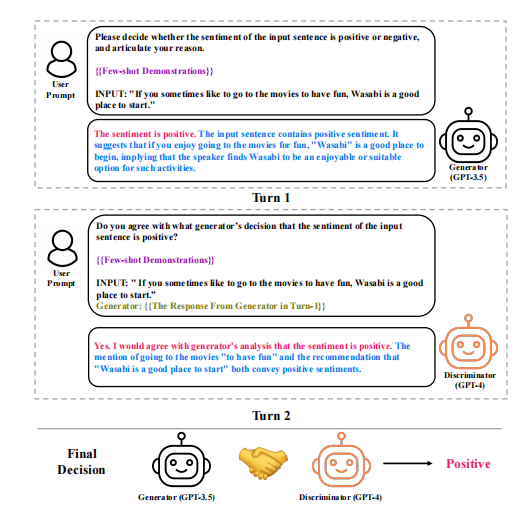
2.具体流程
在多LLM协商框架中,两个LLM分别扮演答案生成器和鉴别器的角色。它们通过不断的交互协商,直到达成一致意见或超过最大协商轮数。
(1)推理增强生成器
生成器由一个大型语言模型支持,基于上下文学习(ICL)范式通过提示(prompt)生成答案。这些提示旨在引导生成器沿着一条推理链逐步推进,从而做出对测试输入情感极性的决策。提示包括三个元素:任务描述、示范案例和测试输入。生成器首先从训练集中检索与测试输入最接近的几个示例作为演示,然后将这些演示转化为包含输入、推理过程和情感决策的三元组。之后,生成器会根据这些信息产出一个推理链和一个情感决策。
(2)解释派生鉴别器
鉴别器同样由一个LLM支持,其任务是评估生成器产生的答案的正确性并提供合理解释。鉴别器的提示包括四个部分:任务描述、示范案例、测试输入和生成器的响应。鉴别器对生成器的输出进行评估,并提供支持或反对生成器决策的理由。
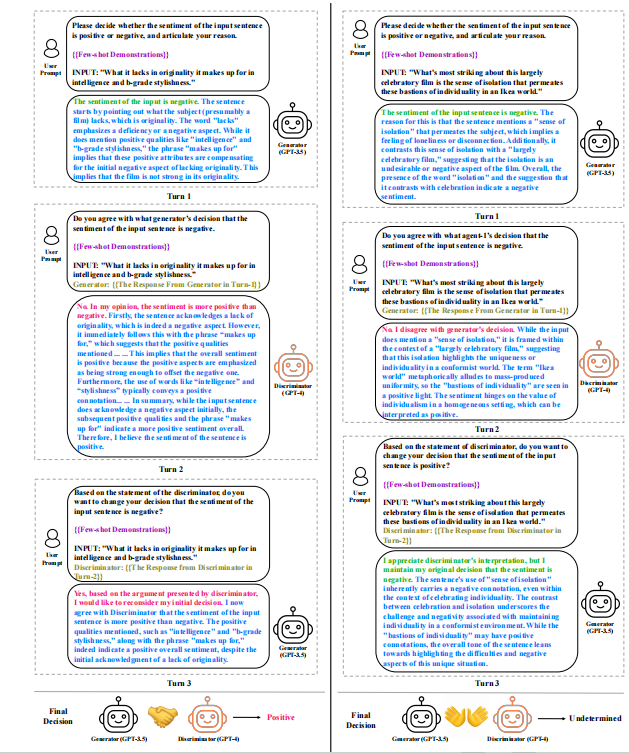
(3)角色翻转协商
将判别器的结果再输入到生成器中,评估两个LLM是否协商一致。如果两轮协商结果一致,这个结果就被接受为最终决策。如果两轮结果不一致,则可能需要引入第三个LLM帮助解决分歧。
(4)引入第三个LLM
当两轮角色翻转协商后依然没有达成一致的决策时,引入第三个LLM进行额外的协商。这个第三个LLM会与前两个LLM分别进行协商和角色翻转协商,共计产生六个不同的协商结果。从这些结果中,选择出现频率最高的决策作为最终的情感判断。
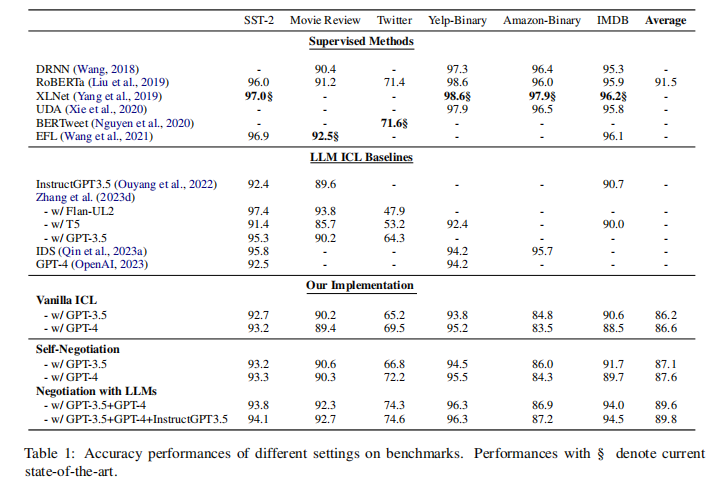
3.实验
(1)实验设置
使用了GPT-3.5、GPT-4和InstructGPT-3(由OpenAI提供)作为模型的主干,利用RoBERTa-Large模型提供的相似性功能来检索最接近的示例作为演示。实验探索了三种不同的上下文学习(ICL)方法:
- Vanilla ICL:通过向LLM提供一个提示来完成情感分析任务,无需进行梯度更新。
- Self-Negotiation:使用单一LLM同时执行生成器和鉴别器的角色,以自我修正生成的答案。
- Negotiation with two LLMs:使用两个不同的LLM分别作为生成器和鉴别器,通过协商来完成任务。
(2)数据集
实验涉及多个情感分析数据集,包括SST-2、电影评论、Twitter、Yelp-Binary、Amazon-Binary和IMDB。
(3)基准和比较
实验结果与多种监督和非监督的方法进行了比较,包括使用RoBERTa、XLNet、UDA、BERTweet和EFL等模型。
(4)结果与分析
实验结果表明:
- 与单独使用一个LLM的Vanilla ICL和Self-Negotiation相比,使用两个LLM进行协商的方法在SST-2、Twitter和IMDB数据集上表现更好,提高了准确度。
- 引入第三个LLM来解决两个LLM协商未达成一致的情况下,可以进一步提高性能,显示出多轮协商和多角度评估确实能够提升情感分析的准确性和可靠性。
- 多模型协商方法不仅在情感分析任务上超越了Vanilla ICL,还在某些情况下超越了传统的监督学习方法,如RoBERTa-Large。
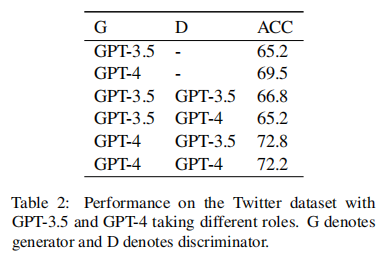
4.消融研究
(1)角色分配的影响
实验展示了在多LLM协商中,不同模型扮演生成器或鉴别器角色时的性能差异。当GPT-3.5作为生成器、GPT-4作为鉴别器时(G3.5-D4),模型的表现(68.8%的准确率)优于单独使用GPT-3.5或GPT-4进行情感分析的设置。这表明,不同LLM之间的互补性对于优化协商结果非常关键。
(2)共识百分比
当GPT-4作为生成器时,系统更容易达成共识或在更少的协商轮次中达成共识。这说明GPT-4在推理过程中可能更为有效,促使协商结果更快地被接受。

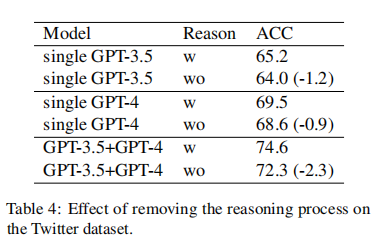
(3)推理过程的效果
在协商过程中,LLMs被要求表达推理过程,这类似于链式推理(Chain of Thought)。消融实验通过移除推理过程来测试其对性能的影响。结果显示,移除推理过程会导致所有设置下性能的下降,特别是在使用协商策略的情况下,性能下降更为显著(GPT-3.5和GPT-4的协商设置减少了2.3个百分点),这强调了在协商设置中保持推理过程的重要性。
















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











