







现在针对YOLOv8的架构改进越来越多,今天尝试引入了Coordinate Attention注意力机制以改进对小目标物体的检测效率。
yolov8的下载和安装参考我这篇博客:
首先我们可以去官网找到CA注意力机制模块的相关文件:
官网链接:GitHub - houqb/CoordAttention: Code for our CVPR2021 paper coordinate attention
接下来我们就可以去下载好的yolov8配置文件中进行修改:
首先是modules.py文件,路径如下:
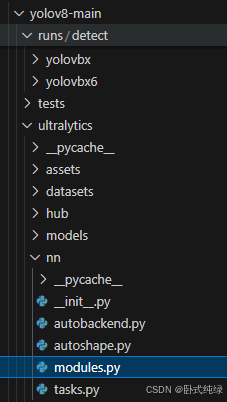
在最下方添加CA注意力机制类的定义:
class CA(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
torch.use_deterministic_algorithms(True, warn_only=True) # 允许非确定性操作但继续运行
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out结果如下:
接着去tasks.py文件下:
最上方注册CA模块:
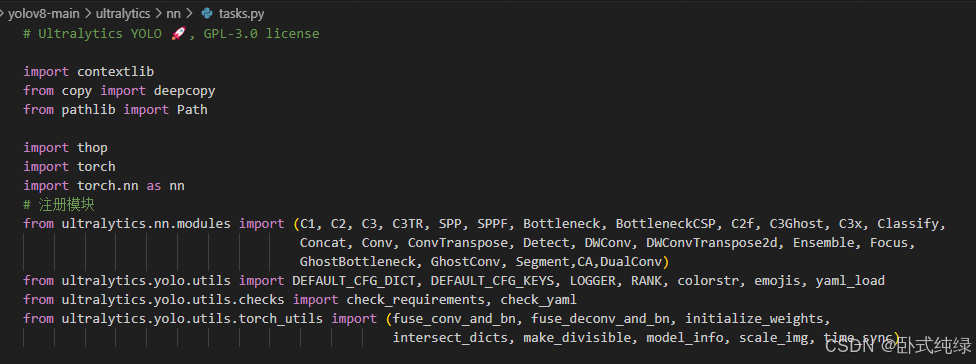
用以下代码:
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF, Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,
Concat, Conv, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble, Focus,
GhostBottleneck, GhostConv, Segment,CA,DualConv)然后找到parse_model函数:
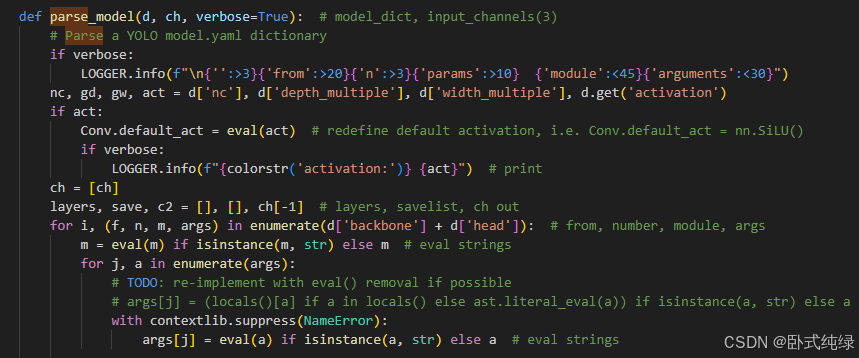
可以Crtl+F全局搜索一下比较快,找到其中一行:
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):在最后C3x后面加入CA即可。
最后再找到你的yaml配置文件:

修改backbone和检测头head,根据你需要添加CA机制的地方来引入CA模块,注意前后输入输出的一致性,以及添加层之后的层序号变动,这些都是需要考虑的,这里给出我的配置文件代码供参考:
# Parameters
nc: 6 # number of classes
depth_multiple: 1.00 # scales module repeats
width_multiple: 1.00 # scales convolution channels
# YOLOv8.0l backbone-only CA
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 [3,64,320,320]
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 [64,128,160,160]
- [-1, 3, C2f, [128, True]] # 2 [128,128,160,160]
- [-1, 1, CA, [128]] # 3 [128,128,160,160]
- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8 [128,256,80,80]
- [-1, 6, C2f, [256, True]] # 5 [256,256,80,80]
- [-1, 1, CA, [256]] # 6 [256,256,80,80]
- [-1, 1, Conv, [512, 3, 2]] # 7-P4/16 [256,512,40,40]
- [-1, 6, C2f, [512, True]] # 8 [512,512,40,40]
- [-1, 1, CA, [512]] # 9 [512,512,40,40]
- [-1, 1, Conv, [512, 3, 2]] # 10-P5/32 [512,512,20,20]
- [-1, 3, C2f, [512, True]] # 11 [512,512,20,20]
- [-1, 1, CA, [512]] # 12 [512,512,20,20]
- [-1, 1, SPPF, [512, 5]] # 13 [512,512,20,20]
# YOLOv8.0l head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 14 [512,512,40,40]
- [[-1, 8], 1, Concat, [1]] # 15 拼接 [512,512,40,40] + [512,512,40,40] → [1024,512,40,40]
- [-1, 3, C2f, [512]] # 16 [1024,512,40,40] → [512,512,40,40]
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 17 [512,512,80,80]
- [[-1, 5], 1, Concat, [1]] # 18 拼接 [512,512,80,80] + [256,256,80,80] → [768,768,80,80]
- [-1, 3, C2f, [256]] # 19 [768,256,80,80]
- [-1, 1, Conv, [256, 3, 2]] # 20 [256,256,40,40]
- [[-1, 16], 1, Concat, [1]] # 21 拼接 [256,256,40,40] + [512,512,40,40] → [768,768,40,40]
- [-1, 3, C2f, [512]] # 22 [768,512,40,40]
- [-1, 1, Conv, [512, 3, 2]] # 23 [512,512,20,20]
- [[-1, 13], 1, Concat, [1]] # 24 拼接 [512,512,20,20] + [512,512,20,20] → [1024,1024,20,20]
- [-1, 3, C2f, [512]] # 25 [1024,512,20,20]
- [[19, 22, 25], 1, Detect, [nc]] # 26 Detect(P3, P4, P5)这样就全部改进完毕了,接下来运行命令就可以看结果了。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









