







代码:https://github.com/KHU-VLL/CAST
论文:[2311.18825] CAST: Cross-Attention in Space and Time for Video Action Recognition (arxiv.org)
-
问题背景:
-
空间和时间理解的平衡:识别视频中的动作不仅需要理解单帧中的空间信息(例如物体的位置、形状等),还需要捕捉帧之间的时间动态(即动作的变化过程)。现有的大多数模型在处理空间和时间信息时,往往会侧重某一方面,缺乏平衡。
-
-
解决方案(CAST架构):
-
双 流架构:该方法使用了两条流,即空间专家模型和时间专家模型。空间流负责提取视频中的空间信息(例如每个帧的内容),而时间流负责处理帧之间的时间序列关系。
-
交叉注意力机制(Cross-Attention Mechanism):这是一种信息交换机制,用来在空间和时间流之间共享信息。通过这种交叉注意力,两个专家模型能够协同工作,整合空间和时间信息,从而形成对视频中动作更全面的理解。
-
瓶颈交叉注意力:这里的“瓶颈”指的是通过某种机制有效地减少信息传递的复杂度或冗余,保持效率的同时提升模型的性能。
-
-
验证与结果:
摘要翻译 识别视频中的人类动作需要对空间和时间信息的理解。现有的大多数动作识别模型在处理视频时缺乏对空间和时间的平衡理解。在这项工作中,我们提出了一种新的双流架构,称为Cross-Attention in Space and Time (CAST),它通过仅使用RGB输入,实现了视频的平衡的时空理解。我们提出的瓶颈交叉注意力机制允许空间专家模型和时间专家模型相互交换信息并协同做出预测,从而提升了性能。我们通过在具有不同特性的公开基准数据集上进行大量实验验证了该方法:EPIC-KITCHENS-100、Something-Something-V2和Kinetics-400。我们的方法在这些数据集上始终表现出良好的性能,而现有方法的性能则会根据数据集的特性波动。
-
研究者在多个具有不同特点的数据集上验证了这种方法的有效性,例如:
-
EPIC-KITCHENS-100:注重日常厨房环境中物体交互的复杂动作。
-
Something-Something-V2:专注于物体之间互动行为的复杂动作识别。
-
Kinetics-400:一个包含大量常见人类动作的通用数据集。
-
-
实验结果表明,CAST模型在这些数据集上的表现稳定且优异,而其他现有方法的性能则根据数据集的特性有所波动,表现不如CAST一致。
-
图一
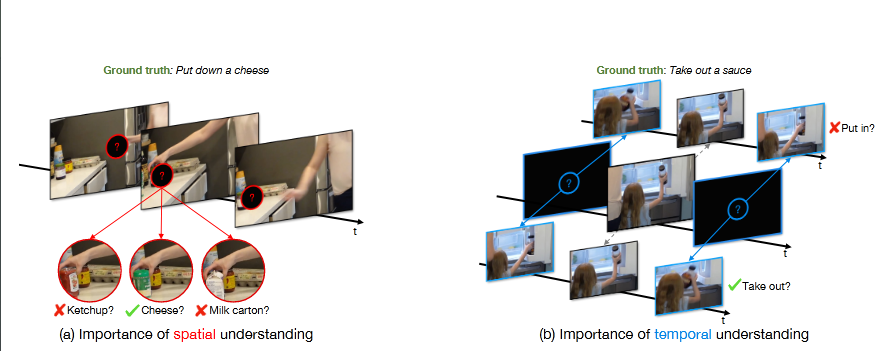
为了准确识别视频中的人类动作,模型必须同时理解空间和时间上下文。一个缺乏精细空间理解的模型很可能无法预测正确的动作。例如,如图1(a)所示,一个能够理解时间上下文(例如手的运动)的模型,但不能理解精细的空间上下文,可能会混淆手中的物体是番茄酱、奶酪还是牛奶盒。因此,模型无法正确预测动作“放下奶酪”。同样,一个缺乏时间上下文理解的模型也可能无法预测正确的动作。如图1(b)所示,假设一个模型理解了空间上下文,但无法理解时间上下文(例如模型不清楚手是从冰箱外移到冰箱内还是反之),那么模型就无法预测正确的动作“取出调料”。因此,为了准确识别动作,模型需要同时理解视频的空间和时间上下文。
尽管通过Transformer等方法在动作识别上取得了进展,但实现平衡的时空理解仍然是一个具有挑战性的问题。与图像相比,视频中的额外时间维度使得时空表示学习在计算上更加密集,并且需要大量的训练数据。因此,大多数动作识别模型缺乏对视频的平衡时空理解。值得注意的是,在静态偏向的数据集(如Kinetics-400)上表现良好的模型,可能在时间偏向的数据集(如Something-Something-V2)上表现不佳,反之亦然。
针对平衡时空理解的挑战,一个可能的解决方案是使用多模态学习。例如,双流网络使用RGB流和光流流来学习空间和时间上下文。然而,这种方法由于需要估计光流,计算量非常大。
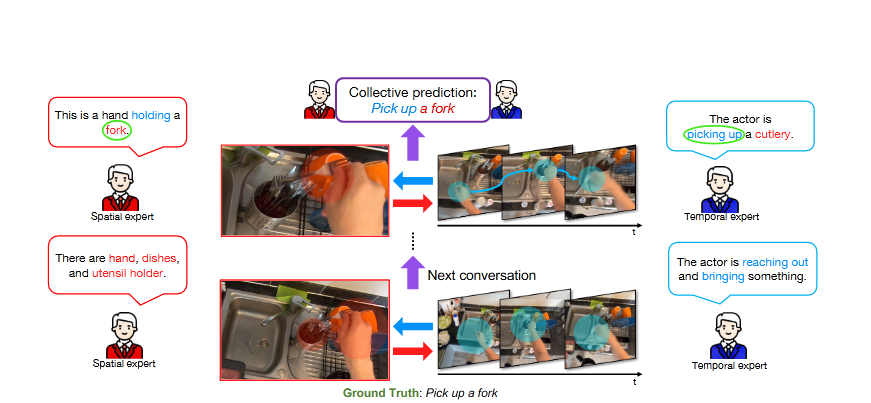
图2
在这项工作中,我们提出了一种双流架构——Cross-Attention in Space and Time (CAST),以仅使用RGB输入来应对平衡时空理解的挑战。如图2所示,我们展示了该方法的高级别示意图。我们的架构使用了两个专家模型——空间专家模型和时间专家模型,这两个模型通过交叉注意力交换信息,从而协同做出集体预测。我们通过在瓶颈架构中引入交叉注意力实现了信息交换,实验验证表明,这种设计可以促使更有效的学习。为了验证该方法的有效性,我们在具有不同特征的多个数据集上进行了大量实验,包括时间偏向的Something-Something-V2、静态偏向的Kinetics-400以及精细化的EPIC-KITCHENS-100。结果表明,CAST能够实现平衡的时空理解,并在这些不同的数据集上表现出良好的性能。
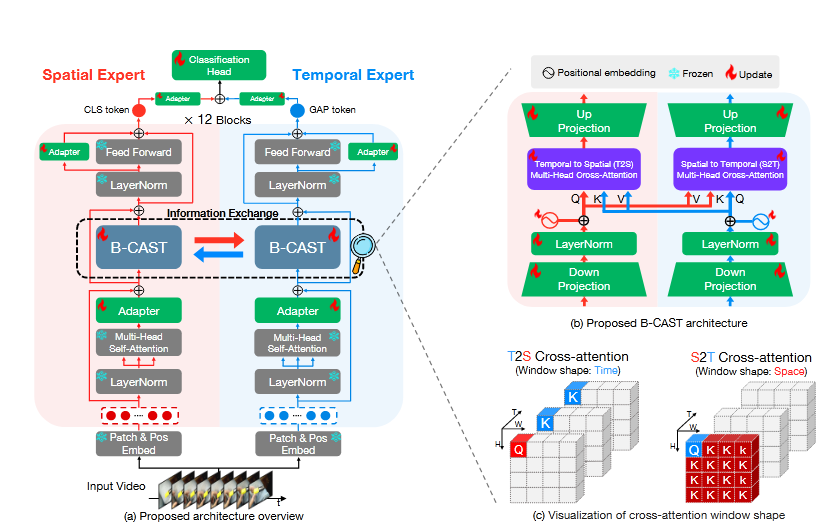
我们引入了CAST,一种用于动作识别的平衡时空表示学习方法,如图3所示。我们使用冻结的空间和时间专家模型,它们可以是任何视觉Transformer,每个模型包含12个Transformer块。为了在这些专家之间实现信息交换,我们在冻结层之上引入了时空瓶颈交叉注意力模块(B-CAST)。该模块使得专家能够交换信息,并比单独的专家模型学习到更平衡的时空上下文。为了增强对下游任务的适应性,我们根据AIM [72]的做法,使用了一小部分可学习参数的适配层。在接下来的小节中,我们将详细描述我们提出的CAST方法的各个组件。、
注:适配层理解
-
Adapter 类是一个轻量级的模块,通常用于增强现有模型的能力,尤其是在微调大模型时。它通过引入一个小型的额外网络来改进模型的表现,同时保持主模型结构不变。下面详细介绍 Adapter 的作用及其工作原理。
Adapter 的作用
轻量级微调:
在微调大模型时,直接修改整个模型的权重可能会导致过拟合。
Adapter 通过引入一个小的附加网络,使模型能够在特定任务上进行微调,而不会显著改变主模型的权重。
参数高效:
Adapter 网络通常包含较少的参数,这使得微调过程更加高效,同时减少了过拟合的风险。
灵活适应不同任务:
可以为不同的任务设计不同的 Adapter,从而使模型能够适应多种任务。
3.1 输入嵌入(Input embeddings)
3.2 CAST architecture

3.3 B-CAST module architecture

个人理解 :论文创新点主要 实现了 时间和空间信息的信息交换,提出的一个核心问题很关键——
时空理解的平衡,理解视频里的内容 时空信息 都很重要,怎么实现的信息交换呢?论文设计了一个交叉注意力瓶颈,并设计了双分流框架,将输入x 分两路输入transformer ,一个作为时间专家模型,一个作为空间专家模型,并在交叉注意力瓶颈 中实现了 信息交换,而这个交换是怎么实现的呢?设计了CrossAttentionT2S 将空间专家模型的输出x_s 作为q 查询,时间专家的输出x_t 作为 k v ,然后进行 attention 机制计算,同理 CrossAttentionS2T 将 时间专家的输出x_t 作为q 查询,空间专家模型的输出x_s 作为 k v ,代码实现起来很简单
主要框架是 使用预训练的vision transformer 冻结参数以后 再进行微调
模型 核心代码
# some codes from CLIP github(https://github.com/openai/CLIP), from VideoMAE github(https://github.com/MCG-NJU/VideoMAE)
from functools import partial
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import drop_path, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from collections import OrderedDict
from einops import rearrange
import random
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 400, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9201
9201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









