







2022 SigSpatial
1 intro
1.1 背景
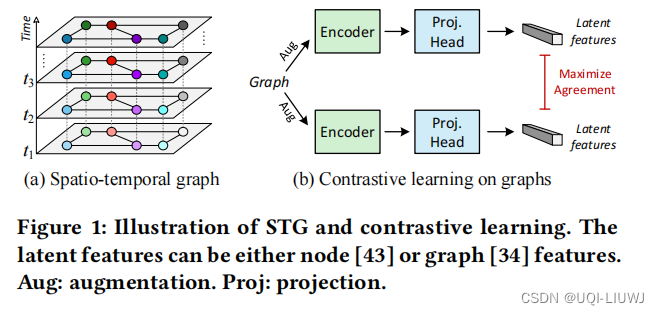
- 论文认为数据稀缺是阻碍时空图(STG)预测的一个关键问题
- 在这一领域的公共数据集通常只包含几个月的数据,限制了可以构建的训练实例数量
- ——>学习模型可能会对训练数据过拟合,导致泛化性能较差
- 自监督学习在graph任务中展现出巨大的潜力
- 从数据本身中获取监督信号,通常利用数据的潜在结构
- 大多数表现最佳的自监督方法都基于对比学习
- 基本思想
- 在具有类似语义(positive pair)的节点或图的表示之间最大化一致性
- 在没有关联语义信息(negative pair)的表示之间最小化一致性
- 通常通过对同一输入(锚点,anchor)应用数据增强来建立正对
- 负对则是在一个批次内的锚点和所有其他输入视图之间形成的
- 图对比学习(GraphCL)的loss略有别于InfoNCE,分母没有正样本对的那一项
- 基本思想

1.2 贡献
- 论文首次系统地研究一个关键问题
- 能否利用对比学习技术所衍生的额外自监督信号来缓解数据稀缺,从而有益于STG预测?
- 如何将对比学习整合到时空神经网络中?
- 具体而言,论文希望解决以下的四个问题
- Q1:在将对比学习与STG预测整合时,什么是适当的训练方案?(pretrain+finetune,还是联合训练?)
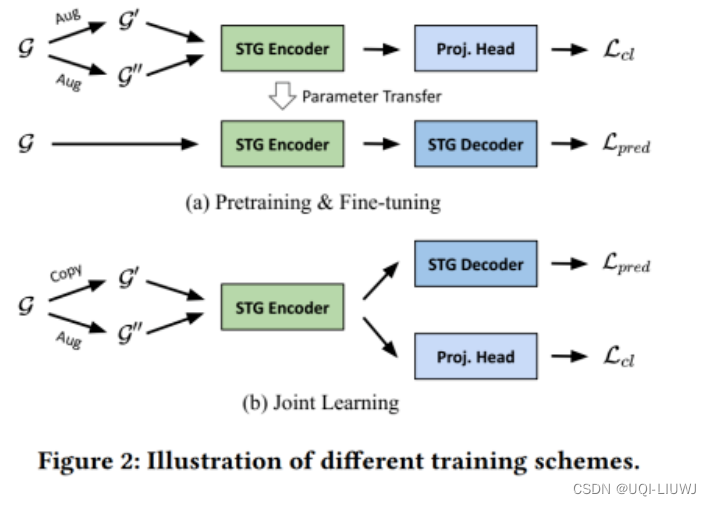
- A1:通过在流行的STG基准测试中评估,我们证明了在预训练方案中联合进行预测和对比任务的有效性
- Q2:对于STG,有两种可能的对象(节点或图)可以进行对比学习。应该选择哪一个?

- A2:实证研究表明,图层次的对比与预测联合学习方案结合可以取得最佳性能
- Q3:应该如何执行数据增强以生成正对?增强方法的选择是否重要?
- A3:论文为STG数据引入了四种数据增强方法,这些方法在图结构、时间域和频率域三个方面扰动输入数据。我们的实验显示,模型对所提出的增强方法的语义并不敏感。
- Q4:给定一个锚点,是否应该将所有其他对象视为负对?如果不是,如何筛选出不合适的负对?
- A4:基于STG的独特特征,如时间紧密度和周期性,我们建议根据每个锚点过滤出“最难的负对”(最不应该是负样本的那些点),从而在真实世界的基准测试中提高预测准确性
- Q1:在将对比学习与STG预测整合时,什么是适当的训练方案?(pretrain+finetune,还是联合训练?)
2 方法
2.1 训练策略(问题1)
2.1.1 两种训练策略
- 预训练与微调
- 首先通过数据增强生成相同输入G的第一个视图G'和第二个视图G''
- 然后,我们将这些视图依次输入STG编码器(学习时空图的时间和空间依赖性的模型)
和投影头
中
- 这些模块将根据对比目标函数L𝑐𝑙进行训练
- 最后舍弃投影头,并使用未经训练的解码器𝑔𝜙(·)对编码器进行微调,以通过优化L𝑝𝑟𝑒𝑑来预测未来
- 联合学习
- 同时进行预测和对比任务
- 然而,对于预测使用原始输入,而对于对比则使用两个增强视图,这会引入不必要的开销
- ——>不仅使用原始输入G执行预测任务,还将其作为第一个视图(G' = G),仅对第二个视图G''进行数据增强,以用于对比学习
- 一个STG编码器𝑓𝜃(·)、一个投影头𝑞𝜓(·)、一个STG解码器𝑔𝜙(·)一起进行联合训练
- 对比目标相当于一个正则化项

2.2 如何对比?(问题2)
- 节点级对比学习
- 更加细粒度,与预测任务的层级相匹配
- 记从STG encoder中提取出来的表征为
- N个节点,D维特征
- 假设我们有一批𝑀个具有𝑁个节点的STG(可以理解成M个时刻,每个时刻N个点)
- 在节点级方法中,我们直接取H,并使用一个投影网络𝑞𝜓(·)将其映射到另一个潜在空间
- 在节点级方法中,我们直接取H,并使用一个投影网络𝑞𝜓(·)将其映射到另一个潜在空间
- 在给定锚点(节点表示)的情况下,其正对来自其增强视图
- 为了执行完整的时空对比,其候选负对包括本时间步中的所有其他节点以及本批次中其他时间步中的所有节点,总共会产生𝑀𝑁个负对
- 当计算一对一对的余弦相似度时,这种方法会产生高计算成本和内存使用量
- 在大型图中可能会完全无法承受
- 当计算一对一对的余弦相似度时,这种方法会产生高计算成本和内存使用量
- ——>受 Adaptive Graph Convolutional Recurrent Network for Traffic Forecasting的启发,论文分别捕获时空依赖性,将完整的时空对比沿着空间和时间维度进行分解
- 负对来自本时间步中的其他节点以及其他时间步中的相同节点
- 通过这种方式,我们只有𝑀 + 𝑁个负对
- ——>复杂度降低为
- ——>复杂度降低为
- 为了执行完整的时空对比,其候选负对包括本时间步中的所有其他节点以及本批次中其他时间步中的所有节点,总共会产生𝑀𝑁个负对
- 图级对比学习
- 考虑整个图的全局知识,可能有助于每个节点学习更有用的表示
- 首先使用一个求和函数,以获得图级表示
- 应用一个投影头𝑞𝜓(·)将其映射到潜在空间
- 正对来自其增强版本,其潜在的负对是来自本批次中其他图的表示
2.3 数据增强(问题3)
- 目前的graph增强方法很少考虑STG数据的内在属性(特别是时间依赖性)
- 论文修改了两种流行的graph增强方法
- 边缘遮盖
- 属性mask
- 提出了两种专门针对STG设计的新方法
- 论文修改了两种流行的graph增强方法
- 用
2.3.1 边缘遮盖
- 遮盖(删除)邻接矩阵的条目来对图的结构进行扰动
- M ∼ 𝑈 (0, 1) 是随机矩阵(均匀分布)

3.3.2 输入遮盖
- mask一部分目标entry
- 目标是增强模型对缺失值的鲁棒性

3.3.3 时间移动

- 沿时间轴移动数据,以利用两个连续时间步之间的中间状态

- α从分布
中采样生成
3.3.4 输入平滑
- 为了减少STG中数据噪声的影响
- 通过在频率域中缩放高频条目来平滑输入
- 高频条目指的是变化频繁的部分,更有可能是噪声
- 首先将历史数据和未来数据(训练期间可用的未来数据)拼接起来
- 扩大时间序列的长度至𝐿 = 𝑆 + 𝑇
- 应用离散余弦变换(DCT)将每个节点的序列从时间域转换到频率域
- 保持低频的𝐸𝑖𝑠个条目不变
- 将高频的𝐿 − 𝐸𝑖𝑠个条目缩放
- 生成一个满足M ∼ 𝑈 (𝑟𝑖𝑠, 1) 的随机矩阵,
- 利用规范化的邻接矩阵
,平滑生成的矩阵
- 其直觉是相邻的传感器,在同一个频率上,应具有相似的缩放范围
- 当邻接矩阵不可用时,可以省略此步骤
- 将随机数逐元素地与原始的𝐿 − 𝐸𝑖𝑠个条目相乘,得到缩放后的高频信号振幅
- 生成一个满足M ∼ 𝑈 (𝑟𝑖𝑠, 1) 的随机矩阵,
- 使用逆离散余弦变换(IDCT)将数据转换回时间域

2.4 负样本(问题4)
- 在大多数对比学习方法中,批次中的所有其他对象都被视为给定锚点的负对象。
- 这忽略了这些对象中有些可能在语义上与锚点相似,不适合用作负对象的部分
- 有一些解决方案建议使用实例的标签来分配正负对
- 然而STG预测是一种典型的回归任务,没有语义标签
- ——>提出基于STG数据的独特属性来过滤不适合的负样本
- 记Xi维过滤之后的负样本集合

2.4.1 空间负样本筛选
- 每个节点的一阶邻居在对比损失计算中被排除
- 仅适用于节点级对比
2.4.2 时间负样本筛选
- 时间负样本筛选两个级别都适用

- 记样本在该天的时刻为t
- 每一天t±rf的时间段都不被视为负样本
2.5实现
下图是一个graph级别的联合训练框架图

3 实验
3.1 数据

3.2 训练方式(问题1)

- 采用图级联合学习的GWN(graph wavenet)模型表现更好,且更稳定
- 预训练+微调的表现比基础模型差,揭示了对比学习的预训练效果不佳
- 在预训练与微调设置中,节点级对比方法优于图级对比。
- 必须确保预训练任务与下游任务之间的一致性
- 从图级对比中提取的先验知识无法帮助在节点级上执行的预测任务
- 在联合学习设置中,图级对比超越了节点级对比
3.3 点级别对比 or 图级别对比?(问题3)

- 总体上,图级对比的表现优于节点级对比
- 在联合学习设置中,节点被引导执行预测任务,导致潜在空间中的一定分布
- 同时,节点被强制通过对比目标来区分其他节点
- 基于这些因素,学习强大的对比组件是非常复杂的,从而在预测性能上带来了很轻微的改进
- 相比之下,在图级别上可能更容易区分模式
- 另外,由于这些交通数据集中某个节点的邻居数量通常较少
- ——>因此利用图级对比为每个节点提供全局上下文的能力更为重要和有效
3.4 消融实验
3.4.1 数据增强的影响(问题3)

- 所有提出的数据增强方法都能够相对基础模型带来增益
- 尽管每种增强方法的语义不同,但每种增强方法所达到的最佳性能几乎没有太大差异。
- ——》这表明论文框架对所提增强方法的语义不敏感
3.4.2 负采样的影响(问题4)

- 当将过滤阈值𝑟𝑓设置为30或60分钟时效果最佳
- 当𝑟𝑓设置为120分钟时,有些结果比𝑟𝑓设置为零时更差。
- 原因是120分钟的阈值会过滤掉太多的负样本,从而降低了对比学习任务的难度















 1582
1582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











