






1.SPD-Conv介绍

1.1 摘要
卷积神经网络(CNN)在图像分类和目标检测等许多计算机视觉任务中取得了巨大的成功。 然而,在图像分辨率较低或物体较小的更艰巨的任务中,它们的性能会迅速下降。 在本文中,我们指出,这源于现有 CNN 架构中一个有缺陷但常见的设计,即使用跨步卷积和/或池化层,这会导致细粒度信息的丢失和学习效率较低的特征表示 。 为此,我们提出了一种名为 SPD-Conv 的新 CNN 构建块来代替每个跨步卷积层和每个池化层(从而完全消除它们)。 SPD-Conv 由空间到深度 (SPD) 层和非跨步卷积 (Conv) 层组成,可应用于大多数(如果不是全部)CNN 架构。 我们在两个最具代表性的计算机视觉任务下解释这种新设计:目标检测和图像分类。 然后,我们通过将 SPD-Conv 应用于 YOLOv5 和 ResNet 来创建新的 CNN 架构,并根据经验表明,我们的方法显着优于最先进的深度学习模型,特别是在低分辨率图像和小物体的更艰巨的任务上。
1.2 简单描述
SPD-Conv(Space-to-Depth Convolution)模块是旨在提高低分辨率图像和小物体的处理能力。此模块由两部分组成:首先是一个空间到深度(Space-to-Depth, SPD)层,随后是一个非跨步(non-strided)卷积层。这种设计的核心思想在于替代传统的步长(strided)卷积和池化操作,以保留更多的细粒度信息,从而改善在处理小尺寸对象和低分辨率图像时的性能。
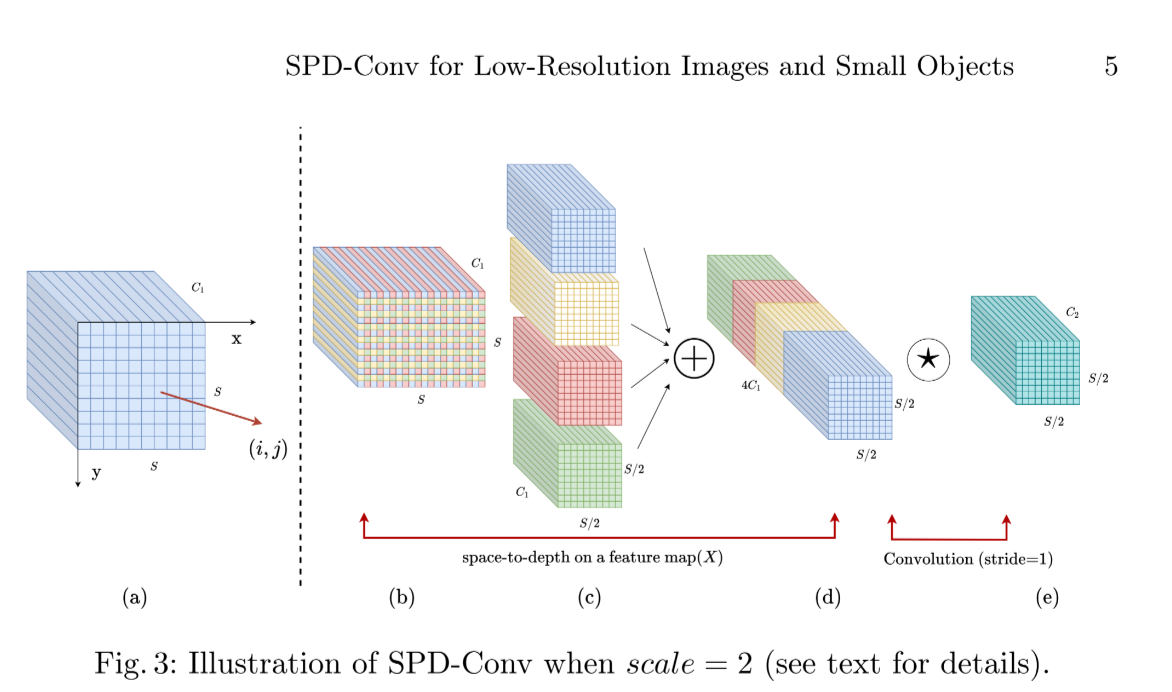
具体来说,SPD层通过对中间特征图进行切片,生成一系列子特征图,这些子特征图通过原特征图的特定区域划分得到,每个子图通过一定的缩放因子(scale)对原特征图进行降采样。这一过程不仅减少了空间维度,同时增加了通道维度。接着,一个非跨步卷积层被用来进一步处理经过SPD层变换后的特征,该层使用可学习的参数来减少通道的数量,这样做是为了防止由于增加的通道导致的信息冗余,同时尽可能保留判别性的特征信息。
通过这种结构设计,SPD-Conv能够在不丢失可学习信息的前提下降低特征图的分辨率,彻底抛弃了广泛使用但在此场景下表现不佳的步长卷积和池化操作。此外,SPD-Conv作为一种通用且统一的方法,不仅可以应用于大多数现有的基于深度学习的计算机视觉任务中,还可以轻松地集成到如PyTorch和TensorFlow等流行深度学习库中。
1.3 SPD-Conv模块结构
2.SPD-Conv代码
class SPDConv(nn.Module):
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
c1 = c1 * 4
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
return self.act(self.conv(x))3.配置文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, SPDConv, [128]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, SPDConv, [256]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, SPDConv, [512]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, SPDConv, [1024]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)注意:nc不需要进行更改,v11会自检classes.txt中检测类的数量后进行替换
4.模型训练代码
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':n
model = YOLO(r'?/ultralytics/cfg/mondels/11/yolo11n.yaml')//将?替换为yaml文件所在位置的绝对路径,下面data同理
model.train(data=r'?/ultralytics/cfg/datasets/coco.yaml',
cache=False,
imgsz=640,
epochs=300,
single_cls=False, # 是否是单类别检测
batch=16,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD',
amp=True,
project='runs/train',
name='exp',
)5.模型测试代码
from ultralytics import YOLO
model = YOLO('?/runs/train/exp/weights/best.pt')//将?替换为训练结果权重文件的绝对路径
# Train the model
results = model.val(data="coco.yaml", imgsz=640, split='test')//只对数据集中的yaml文件中名字叫test文件夹下的数据集测试6.总结
以上就是该模块添加到yolov11中的方法,你可以加在yolov11的任何位置(只要他能跑起来,你可以合理的解释它为什么出现这个位置)。
跑实验的过程是枯燥乏味的,希望我远在天边的朋友你能耐得住寂寞,早日跑出自己想要的结果!!!

















 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









