






三种大模型训练的方式:无参、少参数、全参数
无参数
In-Context Learning(ICL)
全参方法
对大模型进行全量参数训练,主要借助DeepSpeed-Zero3方法,对模型参数进行多卡分割,并借助Offload方法,将优化器参数卸载到CPU上以解决显卡不足问题。
少参数微调
1. Freeze 方法,即参数冻结,对原始模型部分参数进行冻结操作;
2. P-Tuning 方法,参考 ChatGLM 官方代码 ,是针对于大模型的 soft-prompt 方法;
3. LoRA 方法,的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练;
4. AdaLoRA 方法是对 LoRA 的一种改进,并根据重要性评分动态分配参数预算给权重矩阵;
5. QLoRA 方法,是使用一种新颖的高精度技术将预训练模型量化为 4 bit,并添加一小组可学习的低秩适配器权重。
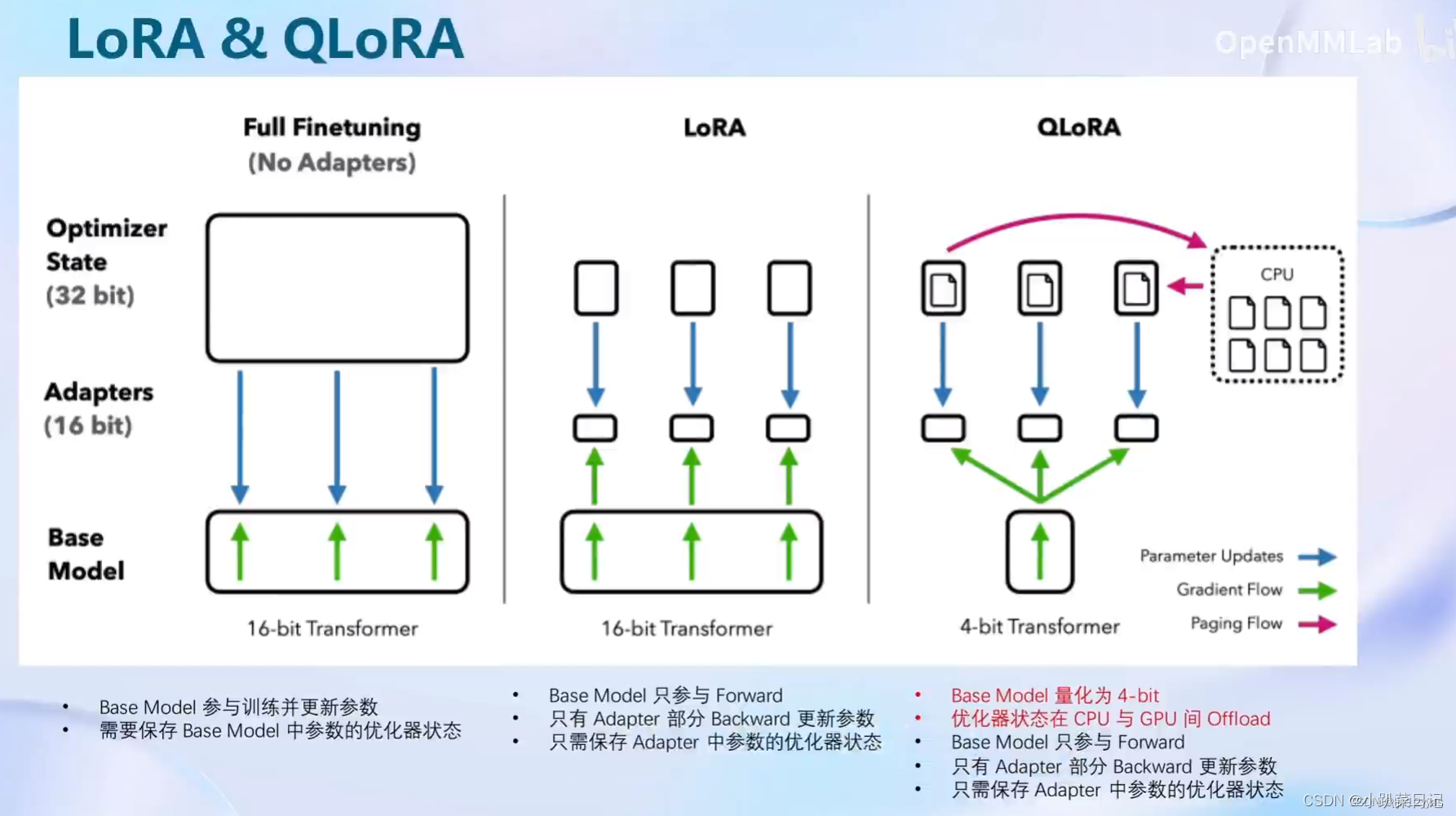
一、LoRA
论文:https://arxiv.org/abs/2106.09685
背景:大模型的参数量都在100B级别,由于算力的吃紧,在这个基础上进行所有参数的微调变得不可能。LoRA正是在这个背景下提出的解决方案
原理:
神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank)。
(可能会发现并不是所有的权重都是必要的。例如,一些全连接层可能并没有提供太多的信息,或者它们学习到的特征对目标并不重要。在这种情况下,通过将权重矩阵投影到一个更低秩的子空间,你可以去除一些不必要的参数,从而减少模型的复杂度。这意味着你可以使用更少的参数来表示相同的信息,从而减少了计算成本,并且仍然保持了良好的性能。)

- 通过低秩分解(先降维再升维)来模拟参数的更新量
LoRA将权重矩阵分解为两个较小的可训练权重矩阵A,B,而原始模型权重参数W0保持冻结。训练的时候固定W0的参数,只训练降维矩阵A与升维矩阵B,而模型的输入输出维度不变。将可训练的秩分解矩阵注入Transformer架构的每一层。- 随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
- 可插拔式的切换任务,当前任务W0+B1A1,将lora部分减掉,换成B2A2,即可实现任务切换;
- 目前对于大多数实验只在 Wq 和 Wv使用LoRA,可训练参数的数量由秩r和原始权值的形状决定。
这样做能节省多少内存呢?这取决于超参数r的秩。例如,如果ΔW有10,000行和20,000列,它存储了2亿参数。如果我们选择的A和B的r=8,那么A有10,000行和8列,B有8行和20,000列,那就是10,000×8 + 8×20,000 = 240,000参数,大约比2亿参数少了830倍。当然,A和B无法捕捉ΔW所能捕捉的所有信息,因此LoRA其实就是牺牲一定性能来降低计算成本。
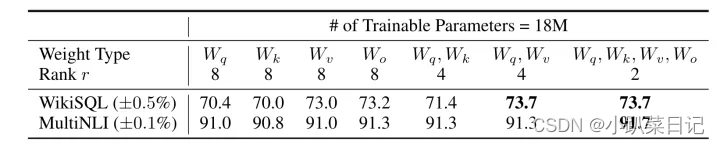
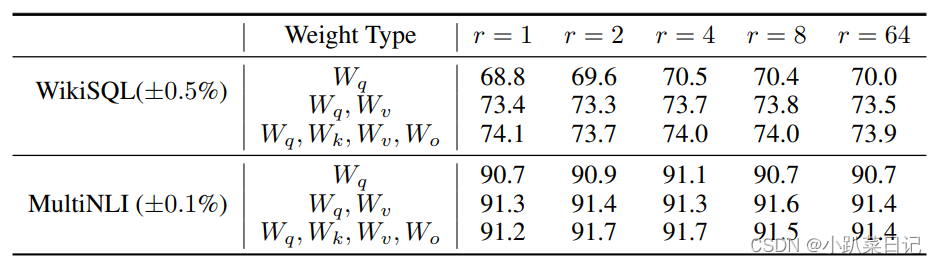
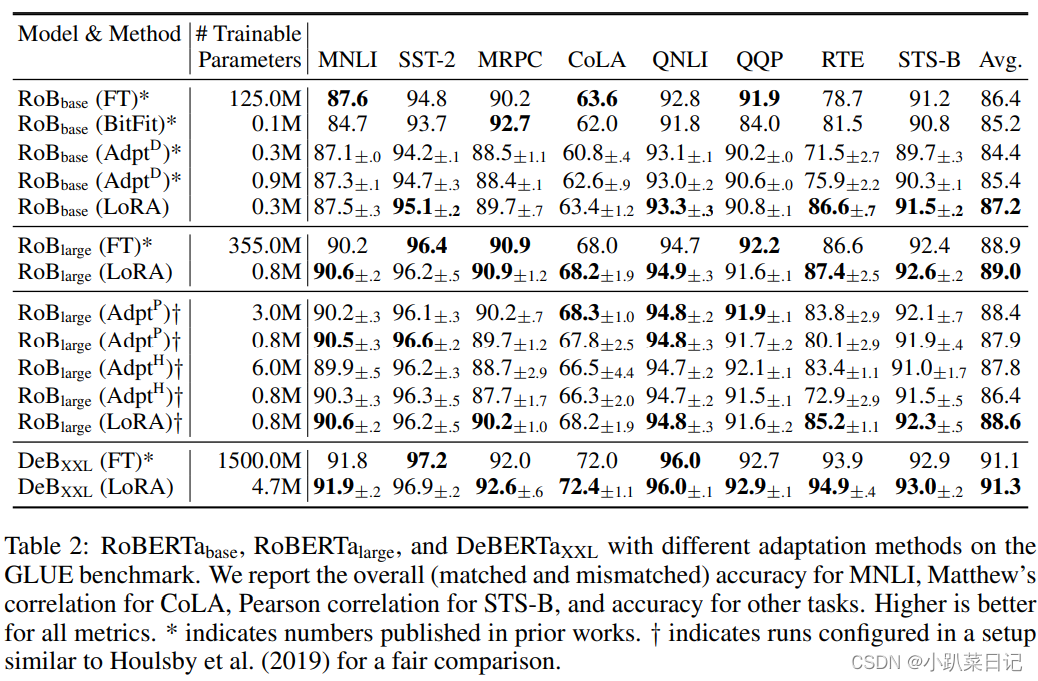
通过实验也发现,在众多数据集上 LoRA 在只训练极少量参数的前提下,最终在性能上能和全量微调匹配,甚至在某些任务上优于全量微调。
二、QLoRA
论文:https://arxiv.org/abs/2305.14314
- 4-bit NormalFloat:提出一种理论最优的4-bit的量化数据类型,优于当前普遍使用的FP4与Int4。对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比 4 bit整数和 4bit 浮点数更好的实证结果。QLORA包含一种低精度存储数据类型(通常为4-bit)和一种计算数据类型(通常为BFloat16)。在实践中,QLORA权重张量使用时,需要将将张量反量化为BFloat16,然后在16位计算精度下进行矩阵乘法运算。模型本身用4bit加载,训练时把数值反量化到bf16后进行训练。
- Double Quantization双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。相比于当前的模型量化方法,更加节省显存空间。每个参数平均节省0.37bit,对于65B的LLaMA模型,大约能节省3GB显存空间。
- Paged Optimizers分页优化器:使用NVIDIA统一内存特性,该特性可以在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
- 增加Adapter:在LoRA中,一般会选择在query和value的全连接层处插入adapter。而QLoRA则在所有全连接层处都插入了adapter,增加了训练参数,弥补精度带来的性能损失。
实验证明,无论是使用 16bit、8bit 还是 4bit 的适配器方法,都能够复制 16bit 全参数微调的基准性能。这说明,尽管量化过程中会存在性能损失,但通过适配器微调,完全可以恢复这些性能。
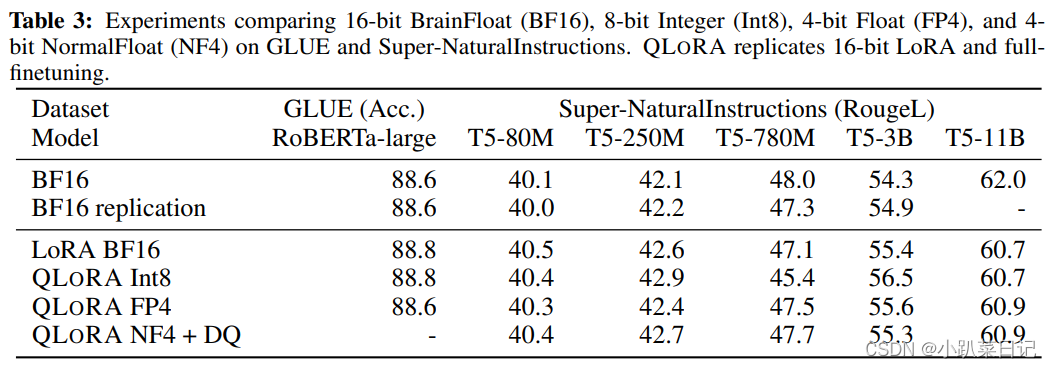
实验还比较了不同的 4bit 数据类型对效果(zero-shot 均值)的影响,其中,NFloat 显著优于 Float,而 NFloat + DQ 略微优于 NFloat,虽然 DQ 对精度提升不大,但是对于显存控制效果更好。
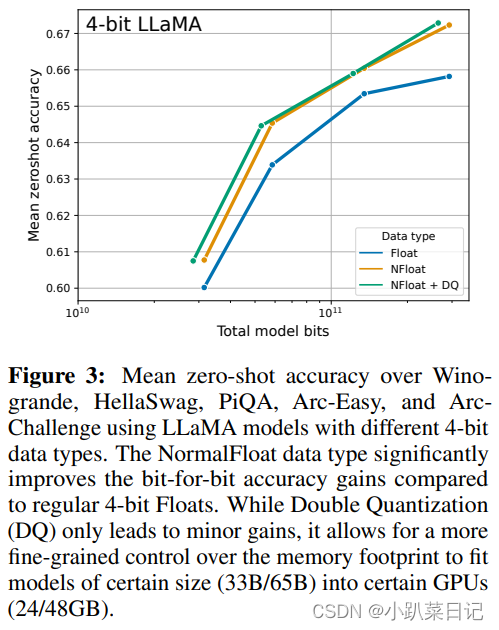
除此之外,论文中还对不同大小模型、不同数据类型、在 MMLU 数据集上的微调效果进行了对比。使用 QLoRA(NFloat4 + DQ)可以和 Lora(BFloat16)持平,同时, 使用 QLORA( FP4)的模型效果落后于前两者一个百分点。
指令调优虽然效果比较好,但只适用于指令相关的任务,在聊天机器人上效果并不佳,而聊天机器人更适合用 Open Assistant 数据集去进行微调。通过指令类数据集的调优更像是提升大模型的推理能力,并不是为聊天而生的。
三、补充

















 3892
3892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









