







Paper Title: DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
Project Website:https://github.com/IDEA-Research/DINO-X-API
该论文发布于2024年
该论文中提出的方法适用的场景如下:

开放世界的物体检测与分割
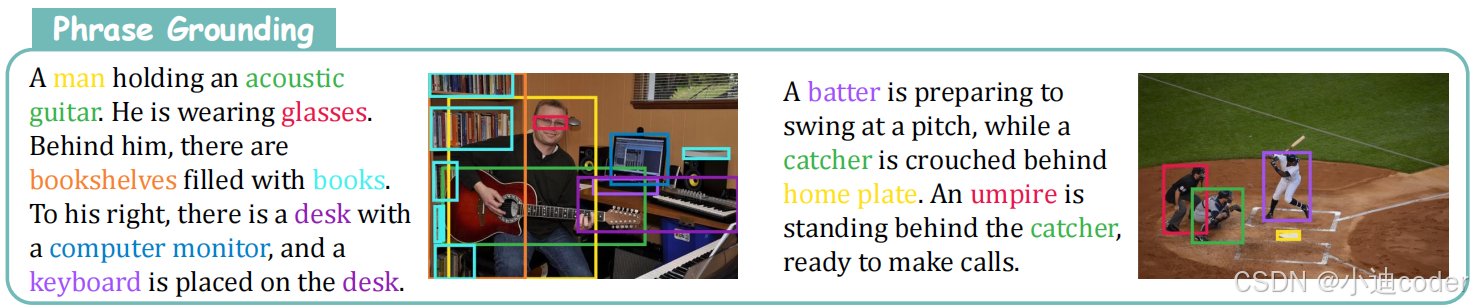
用描述性文本去定位

用视觉提示词来描述任务

姿态估计

无提示物体监测与识别

密集区域描述
DINO-X 是一个统一的以物体为中心的视觉模型,支持各种开放世界感知和物体级理解任务,包括开放世界物体检测与分割、短语定位、视觉提示计数、姿态估计、无提示物体检测与识别、密集区域描述等。
DINO-X采用与Grounding DINO 1.5 相同的基于Transformer的编码器-解码器架构,旨在实现开放世界物体理解的物体级表示。为了简化长尾物体检测,DINO-X扩展了输入选项,支持文本提示、视觉提示和自定义提示。
DINO-X包括两个模型:
Pro模型,提供增强的感知能力,适用于各种场景;
Edge模型,经过优化,具有更快的推理速度,更适合在边缘设备上部署。
DINO-X 通过构建 Grounding-100M 数据集(一个包含超过 1 亿个高质量定位样本的大规模数据集)来训练模型,从而增强了其对开放词汇物体的检测能力。
DINO-X 还支持多任务学习,能够同时执行多种感知任务,如物体检测、分割、姿势估计等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









