







2024年11月20号IDEA Research 开发的具有最佳开放世界物体检测性能的统一的以物体为中心的视觉模型。为了使长尾物体检测变得简单,DINO-X 扩展了其输入选项以支持文本提示、视觉提示和自定义提示。

文章地址:DINO-X:用于开放世界物体检测和理解的统一视觉模型
项目地址:https://github.com/IDEA-Research/DINO-X-API
体验地址:https://deepdataspace.com/playground/grounding_dino
主要内容
IDEA 开发了一个通用物体提示来支持无提示的开放世界检测,从而无需用户提供任何提示即可检测图像中的任何内容。构建了一个包含超过 1 亿个高质量基础样本的大规模数据集,称为 Grounding-100M,以提高模型的开放词汇检测性能。还扩展了 DINO-X 以集成多个感知头,从而同时支持多个物体感知和理解任务,包括检测、分割、姿势估计、物体字幕、基于物体的 QA 等。
DINO-X 包含两个模型:
- DINO-X Pro: 性能最强的型号,增强感知能力,适用于多种场
- DINO-X Edge: 高效模型针对更快的推理速度进行了优化,更适合部署在边缘设备上。
DINO-X 亮点
在DINO 1.5 的基础上,DINO-X 进行了多项改进,朝着更通用的以物体为中心的视觉模型迈进了一步。
DINO-X 的亮点如下:
- 最强的开放集检测性能:DINO-X Pro 在零样本转移检测基准上创下了新的 SOTA 结果:COCO 上的56.0 AP、LVIS-minival 上的59.8 AP和LVIS-val 上的52.4 AP。将之前的 SOTA 性能提高了 5.8 个AP 和5.0 个 AP。凸显了其识别长尾物体的能力显著提高。
- 多样化的输入提示和多层次的输出语义表示:DINO-X 可以接受文本提示、视觉提示和自定义提示作为输入,并通过多个感知头输出各种语义级别的表示,包括边界框、分割蒙版、姿势关键点和对象标题。
- 丰富实用的功能:DDINO-X可以同时支持许多实用性极强的任务,包括开放集物体检测与分割、短语基础、视觉提示计数、姿势估计和区域字幕。进一步开发了通用物体提示,以实现无提示的任何物体检测和识别。
DINO-X整体框架
DINO-X 可以接受文本提示、视觉提示和自定义提示作为输入,并且可以生成各个语义层面的表示,包括边界框、分割蒙版、姿势关键点和对象标题。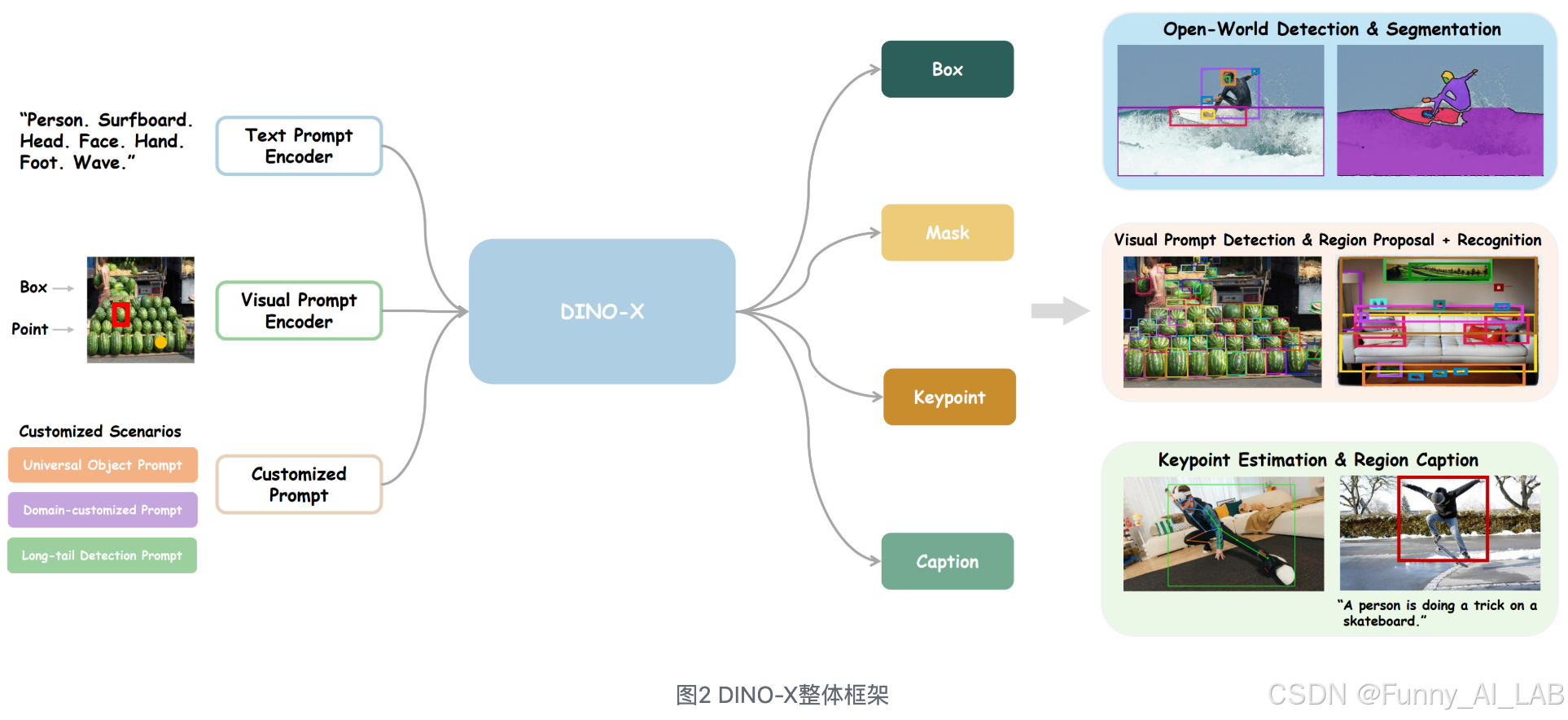
DINO-X Pro的核心架构,与Grounding DINO 1.5类似,利用预先训练好的 ViT 模型作为主要的视觉骨干,并在特征提取阶段采用了深度早期融合策略。
但不同的是,他们扩大了DINO-X Pro在输入阶段的提示支持,除了文本,还支持视觉提示和自定义提示,以满足包括长尾物体在内的各种检测需求。
而对于DINO-X Edge版本,他们利用 EfficientViT作为高效特征提取的骨干,并采用了类似Transformer编码器-解码器架构。
此外,为了提高 DINO-X Edge 模型的性能和计算效率,他们还对模型结构和训练技术做了几个方面的改进:
- 文本提示编码器:采用了与pro模型相同的 CLIP 文本编码器
- 知识提炼模型:利用基于特征的蒸馏和基于响应的蒸馏,分别调整Edge模型和Pro模型之间的特征和预测对数。
- 优化模型推理:改进FP16推理,采用浮点乘法归一化技术
应用场景
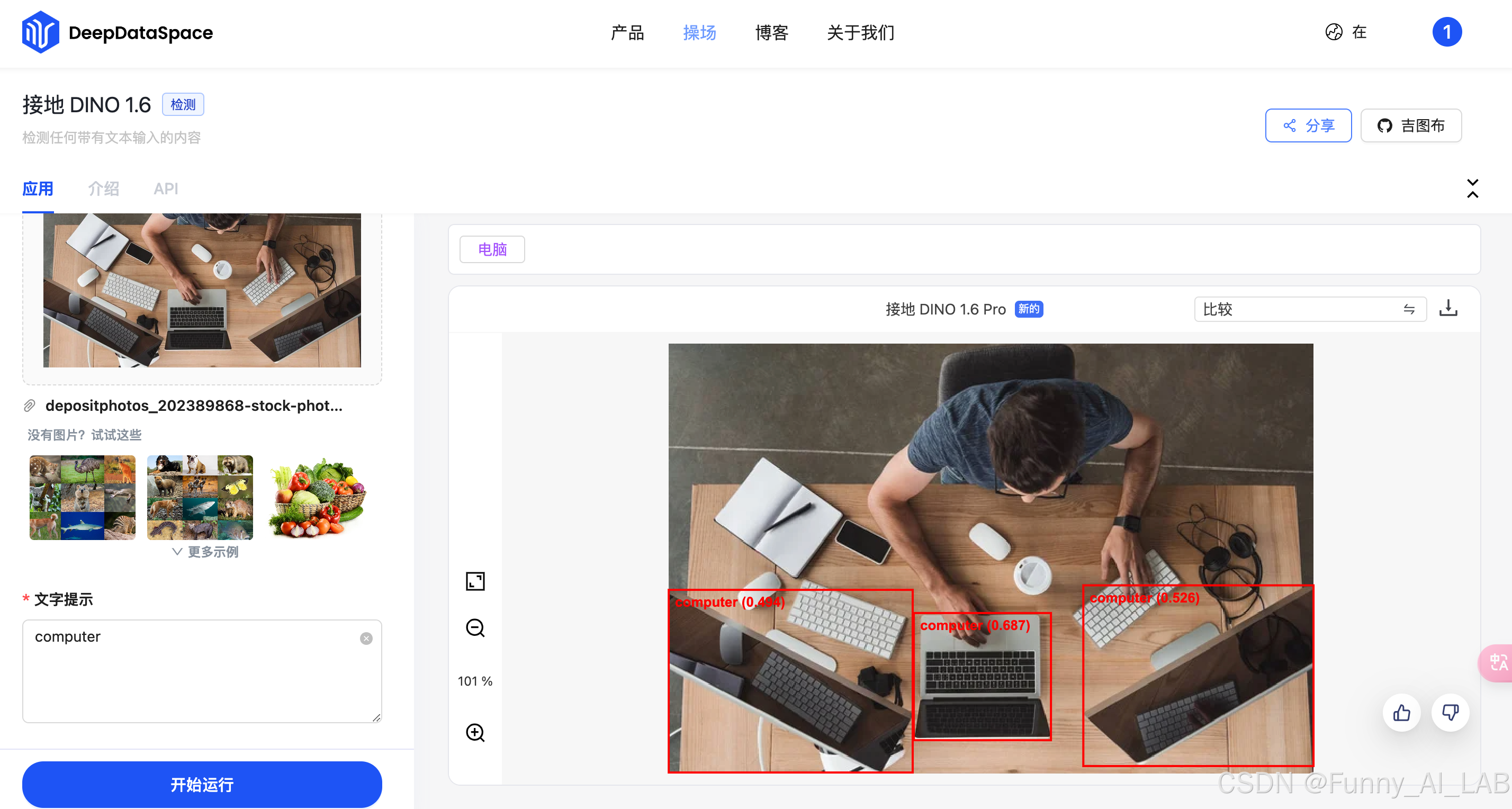
检测各种物体:DINO-X 展示了根据给定的文本提示检测任何物体的能力。它可以识别各种物体,从常见类别到长尾类别和密集物体场景,展示了其强大的开放世界物体检测能力。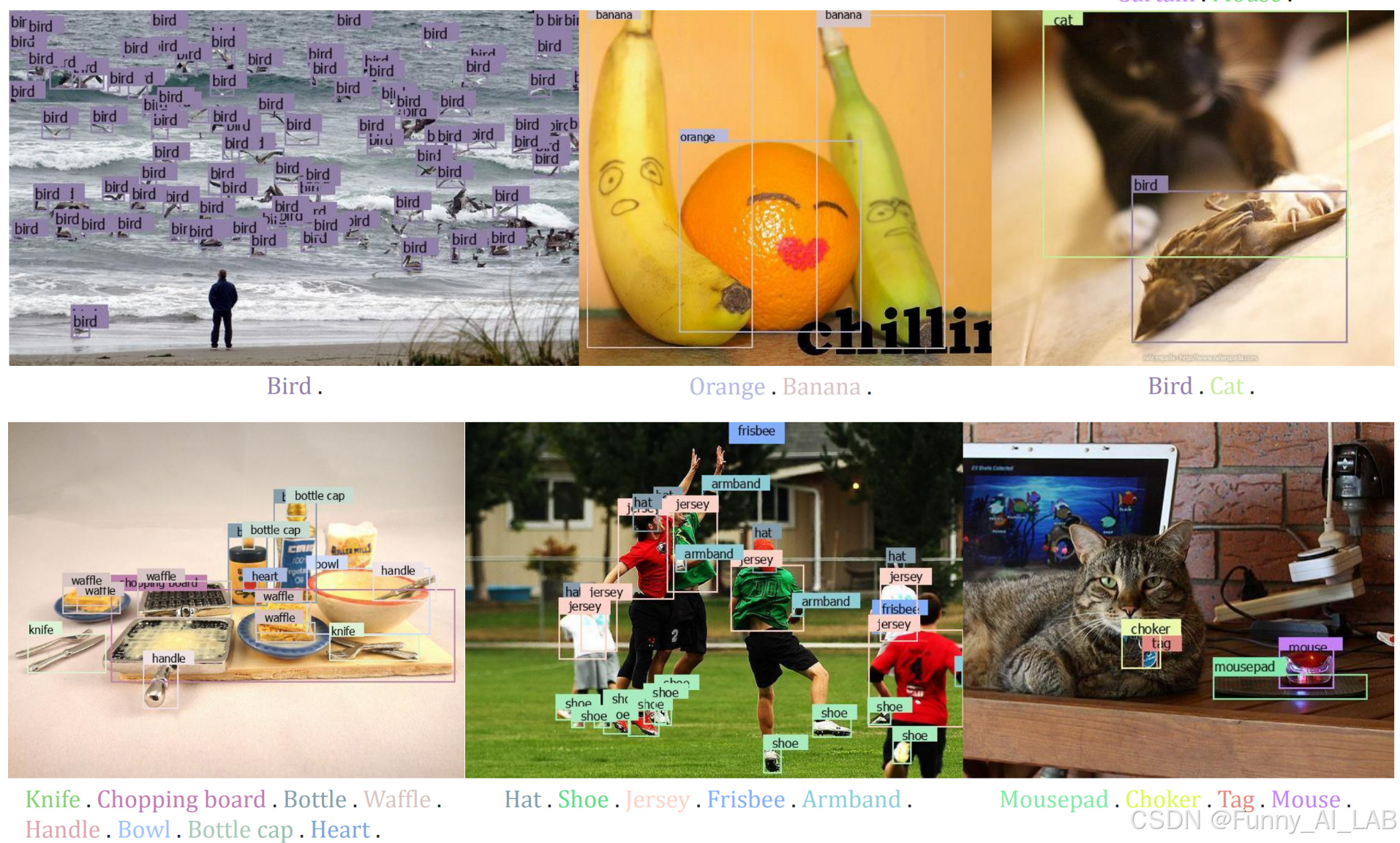
检测及分割结果:DINO-X 不仅能够基于文本提示进行开放世界物体检测,还能为每个物体生成相应的分割掩码,提供更丰富的语义输出。

无提示物体检测:该功能允许用户在不提供任何提示的情况下检测输入图像中的任何物体。
人体和手部关键点:DINO-X 在 COCO、CrowdHuman 和 Human-Art 数据集上进行训练,能够预测各种场景中的人体和手部关键点。
总结
DINO-X,是一种强大的以对象为中心的视觉模型,旨在推动开放集对象检测和理解领域的发展。旗舰模型 DINO-X Pro 在 COCO 和 LVIS 零样本基准测试中创下了新纪录,检测准确率和可靠性显著提高。为了使长尾对象检测变得简单,DINO-X 不仅支持基于文本提示的开放世界检测,还支持使用视觉提示和自定义提示进行对象检测,以适应定制场景。
此外,DINO-X 将其功能从检测扩展到更广泛的感知任务,包括分割、姿势估计和对象级理解任务。为了让更多边缘设备上的应用程序能够实时检测对象,还开发了 DINO-X Edge 模型,进一步扩展了 DINO-X 系列模型的实际效用。

















 3293
3293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









