







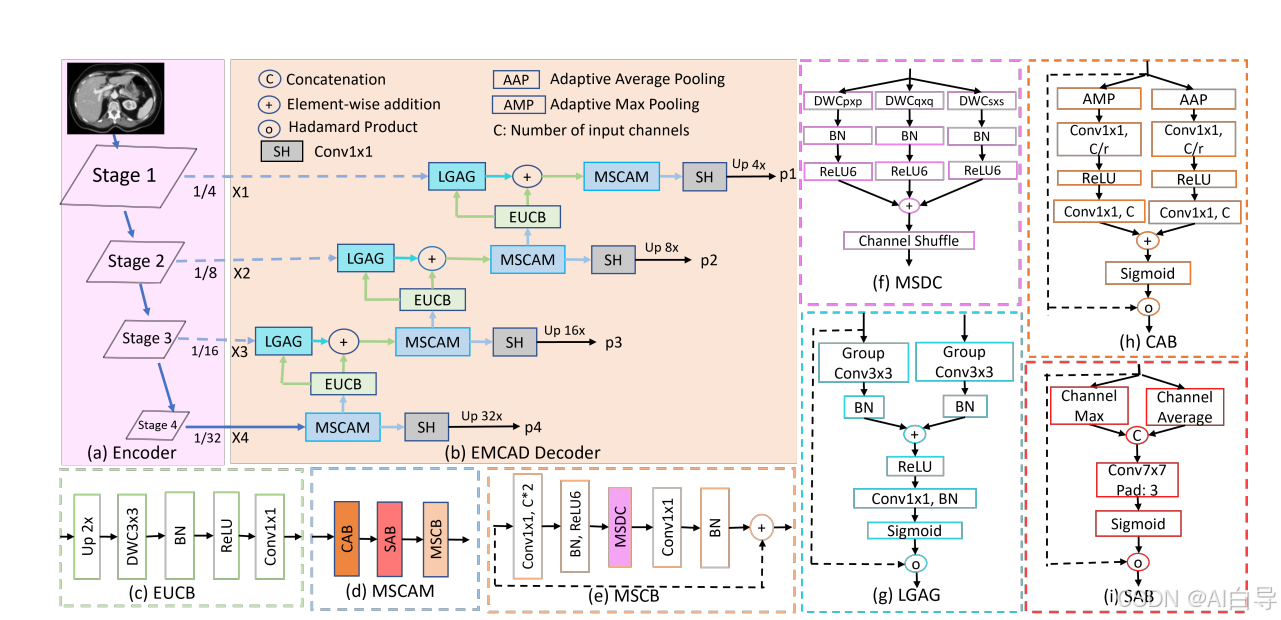
一种高效、有效的解码机制是医学图像分割的关键,特别是在计算资源有限的情况下。然而,这些解码机制通常会带有很高的计算成本。为了解决这个问题,我们引入了EMCAD,一种新的高效的多尺度卷积注意解码器,旨在优化性能和计算效率。EMCAD利用了一个独特的多尺度深度卷积块,通过多尺度卷积显著增强了特征映射。EMCAD还采用了通道、空间和分组(大核)门控注意机制,这些机制在关注显著区域的同时,能够非常有效地捕获复杂的空间关系。通过使用组和深度卷积,EMCAD非常高效,而且规模也很好(例如,当使用标准编码器时,只需要1.91M参数和0.381GFLOPs)。我们对属于6个医学图像分割任务的12个数据集进行的严格评估显示,发现EMCAD在#Params和#FLOPs方面分别实现了79.4%的最先进的(SOTA)性能和80.3%。
import torch
import torch.nn as nn
from functools import partial
import math
from timm.models.layers import trunc_normal_tf_
from timm.models.helpers import named_apply
def gcd(a, b):
while b:
a, b = b, a % b
return a
def _init_weights(module, name, scheme=''):
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Conv3d):
if scheme == 'normal':
nn.init.normal_(module.weight, std=.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif scheme == 'trunc_normal':
trunc_normal_tf_(module.weight, std=.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif scheme == 'xavier_normal':
nn.init.xavier_normal_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif scheme == 'kaiming_normal':
nn.init.kaiming_normal_(module.weight, mode='fan_out', nonlinearity='relu')
if module.bias is not None:
nn.init.zeros_(module.bias)
else:
fan_out = module.kernel_size[0] * module.kernel_size[1] * module.out_channels
fan_out //= module.groups
nn.init.normal_(module.weight, 0, math.sqrt(2.0 / fan_out))
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm3d):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.LayerNorm):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
def act_layer(act, inplace=False, neg_slope=0.2, n_prelu=1):
act = act.lower()
if act == 'relu':
layer = nn.ReLU(inplace)
elif act == 'relu6':
layer = nn.ReLU6(inplace)
elif act == 'leakyrelu':
layer = nn.LeakyReLU(neg_slope, inplace)
elif act == 'prelu':
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
elif act == 'gelu':
layer = nn.GELU()
elif act == 'hswish':
layer = nn.Hardswish(inplace)
else:
raise NotImplementedError('activation layer [%s] is not found' % act)
return layer
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batchsize, -1, height, width)
return x
class MSDC(nn.Module):
def __init__(self, in_channels, kernel_sizes=[1, 3, 5], stride=1, activation='relu6', dw_parallel=True):
super(MSDC, self).__init__()
self.in_channels = in_channels
self.kernel_sizes = kernel_sizes
self.activation = activation
self.dw_parallel = dw_parallel
self.dwconvs = nn.ModuleList([
nn.Sequential(
nn.Conv2d(self.in_channels, self.in_channels, kernel_size, stride, kernel_size // 2,
groups=self.in_channels, bias=False),
nn.BatchNorm2d(self.in_channels),
nn.ReLU6(inplace=True)
)
for kernel_size in self.kernel_sizes
])
self.init_weights('normal')
def init_weights(self, scheme=''):
named_apply(partial(_init_weights, scheme=scheme), self)
def forward(self, x):
outputs = []
for dwconv in self.dwconvs:
dw_out = dwconv(x)
outputs.append(dw_out)
if self.dw_parallel == False:
x = x + dw_out
# You can return outputs based on what you intend to do with them
return outputs
class MSCB(nn.Module):
def __init__(self, in_channels, out_channels, stride, kernel_sizes=[1, 3, 5], expansion_factor=2, dw_parallel=True,
add=True, activation='relu6'):
super(MSCB, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.stride = stride
self.kernel_sizes = kernel_sizes
self.expansion_factor = expansion_factor
self.dw_parallel = dw_parallel
self.add = add
self.activation = activation
self.n_scales = len(self.kernel_sizes)
# check stride value
assert self.stride in [1, 2]
# Skip connection if stride is 1
self.use_skip_connection = True if self.stride == 1 else False
# expansion factor
self.ex_channels = int(self.in_channels * self.expansion_factor)
self.pconv1 = nn.Sequential(
# pointwise convolution
nn.Conv2d(self.in_channels, self.ex_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(self.ex_channels),
act_layer(self.activation, inplace=True)
)
self.msdc = MSDC(self.ex_channels, self.kernel_sizes, self.stride, self.activation,
dw_parallel=self.dw_parallel)
if self.add == True:
self.combined_channels = self.ex_channels * 1
else:
self.combined_channels = self.ex_channels * self.n_scales
self.pconv2 = nn.Sequential(
# pointwise convolution
nn.Conv2d(self.combined_channels, self.out_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(self.out_channels),
)
if self.use_skip_connection and (self.in_channels != self.out_channels):
self.conv1x1 = nn.Conv2d(self.in_channels, self.out_channels, 1, 1, 0, bias=False)
self.init_weights('normal')
def init_weights(self, scheme=''):
named_apply(partial(_init_weights, scheme=scheme), self)
def forward(self, x):
pout1 = self.pconv1(x)
msdc_outs = self.msdc(pout1)
if self.add == True:
dout = 0
for dwout in msdc_outs:
dout = dout + dwout
else:
dout = torch.cat(msdc_outs, dim=1)
dout = channel_shuffle(dout, gcd(self.combined_channels, self.out_channels))
out = self.pconv2(dout)
if self.use_skip_connection:
if self.in_channels != self.out_channels:
x = self.conv1x1(x)
return x + out
else:
return out
def MSCBLayer(in_channels, out_channels, n=1, stride=1, kernel_sizes=[1, 3, 5], expansion_factor=2, dw_parallel=True,
add=True, activation='relu6'):
"""
create a series of multi-scale convolution blocks.
"""
convs = []
mscb = MSCB(in_channels, out_channels, stride, kernel_sizes=kernel_sizes, expansion_factor=expansion_factor,
dw_parallel=dw_parallel, add=add, activation=activation)
convs.append(mscb)
if n > 1:
for i in range(1, n):
mscb = MSCB(out_channels, out_channels, 1, kernel_sizes=kernel_sizes, expansion_factor=expansion_factor,
dw_parallel=dw_parallel, add=add, activation=activation)
convs.append(mscb)
conv = nn.Sequential(*convs)
return conv
class CAB(nn.Module):
def __init__(self, in_channels, out_channels=None, ratio=16, activation='relu'):
super(CAB, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if self.in_channels < ratio:
ratio = self.in_channels
self.reduced_channels = self.in_channels // ratio
if self.out_channels == None:
self.out_channels = in_channels
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.activation = act_layer(activation, inplace=True)
self.fc1 = nn.Conv2d(self.in_channels, self.reduced_channels, 1, bias=False)
self.fc2 = nn.Conv2d(self.reduced_channels, self.out_channels, 1, bias=False)
self.sigmoid = nn.Sigmoid()
self.init_weights('normal')
def init_weights(self, scheme=''):
named_apply(partial(_init_weights, scheme=scheme), self)
def forward(self, x):
avg_pool_out = self.avg_pool(x)
avg_out = self.fc2(self.activation(self.fc1(avg_pool_out)))
max_pool_out = self.max_pool(x)
max_out = self.fc2(self.activation(self.fc1(max_pool_out)))
out = avg_out + max_out
return self.sigmoid(out)
class SAB(nn.Module):
def __init__(self, kernel_size=7):
super(SAB, self).__init__()
assert kernel_size in (3, 7, 11), 'kernel must be 3 or 7 or 11'
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
self.init_weights('normal')
def init_weights(self, scheme=''):
named_apply(partial(_init_weights, scheme=scheme), self)
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class EMCAM(nn.Module):
def __init__(self, in_channels=1024, out_channels=1024, kernel_sizes=[1, 3, 5], expansion_factor=6, dw_parallel=True,
add=True, lgag_ks=3, activation='relu'):
super(EMCAM, self).__init__()
eucb_ks = 3 # kernel size for eucb
self.mscb1 = MSCBLayer(in_channels, out_channels, n=1, stride=1, kernel_sizes=kernel_sizes,
expansion_factor=expansion_factor, dw_parallel=dw_parallel, add=add,
activation=activation)
self.cab1 = CAB(out_channels)
self.sab = SAB()
def forward(self, x):
d1 = self.cab1(x) * x
d1 = self.sab(d1) * d1
d1 = self.mscb1(d1)
return d1
elif m is EMCAM:
c1 = ch[f]
c2 = args[0] if len(args) > 0 else c1
args = [c1, c2, *args[1:]] 

















 3466
3466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









