







背景
传统批量优化算法假设所有数据预先可用,但实际机器人任务(如SLAM)中,数据是时序增量到达的,需要实时中间解。由于随着时间推移,优化问题规模指数增长,重复批量优化计算代价过高。所以,我们需要通过重用历史计算,避免全量更新,实现高效的增量优化。下面将分别从线性系统和非线性系统两方面展开。
线性系统的增量更新
又回到之前推倒过的线性化公式:
![]()
通过QR分解可以得到下式,这个已在前文推倒过,这里不重复介绍。
![]()
当检测到新的测量值时,我们这里不采用重新构造A’|b’的方法,避免全量更新。而是,通过扩展系统实现增量优化。设扩展系统:
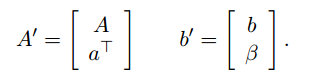
对其进行QR分解:
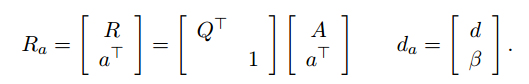
此时Ra尚未保持上三角形式,需通过Givens旋转消除新增行的非零元素。下面我们先介绍一下Givens旋转。
Givens旋转原理
HouseHolder是利用算子进行投影,一次将一个向量除第一个元素以外都转化成零。而有一种方法,可以每次将向量的一个元素转化成0,也可以最终达到正交化的目的,它就是Givens旋转。HouseHolder对于大量引进零元素是有用的,例如,消去一个向量中除第一个分量外的所有分量,然而,在许多计算中,必须有选择地消去一些元素。Givens旋转就是解决这些问题的工具。下面这个矩阵是单位矩阵的秩二矫正:
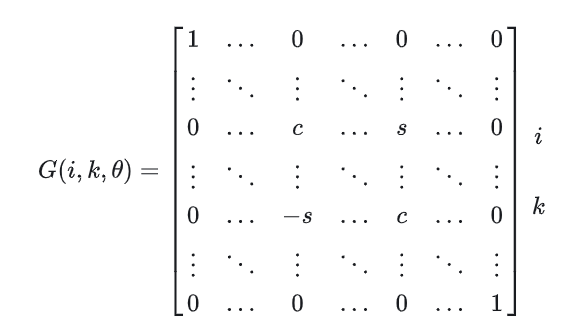
对于其中的某个 ,
显然Givens旋转是正交变换。
用 进行左乘产生一个在
坐标平面的
弧度的逆时针旋转。
其旋转后公式为:
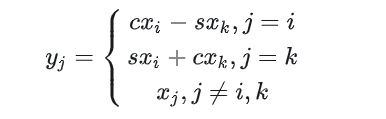
在这里,我们令
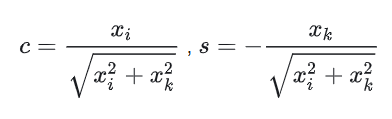
使得。因此,使用Givens旋转很容易就可以将一个向量的某个分量的某个指定分量化为0。
Givens旋转的构造
Givens旋转矩阵形式为:
其作用是消除矩阵中特定位置的元素。对于新增行,从最左侧非零元素
开始,选择旋转角度
使得:
旋转后,目标位置 的元素被归零。
于是,这里我们使用Givens变换的目的就很清楚了,就是将扩展矩阵Ra通过一系列Givens变换将对角线以下的元素全变为0,其数学表达式可以写为:
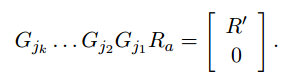
右侧向量da同步更新:
基于此,我们可以写出通过增量变换后的目标函数:
![]()
其中 为更新后的残差常数。
卡尔曼滤波与平滑
卡尔曼滤波器和平滑器是增量更新线性系统的特殊情况。为了与卡尔曼平滑器建立联系,我们首先描述因子图中边缘化的概念,然后讨论机器人技术中两种流行的基于边缘化的方法:固定滞后平滑和滤波。首先先介绍一下边缘化。
边缘化
即使使用增量更新,内存使用和计算在时间上仍然是无限的。一个解决方案是删除旧变量而不删除信息,这个过程称为边缘化。边缘化有三种处理方式,接下来将一一介绍。
1.若联合概率以协方差形式给出:
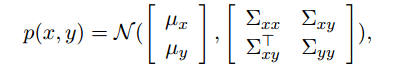
边缘化较为简单,协方差矩阵的块结构直接反映了边缘分布的协方差,直接取子块:
![]()
2.若联合概率以信息形式给出,边缘化后y的信息矩阵由Schur补给出。
具体应用中,选择协方差形式或信息形式取决于问题需求。信息形式更适合需要高效局部更新和稀疏性的场景,而协方差形式可能更直观用于直接概率解释。采用信息形式的主要原因是计算效率和算法设计的便利性,尤其在需要频繁边缘化、增量更新或处理稀疏结构的场景。
2.1 舒尔补
对于一个分块矩阵:
假设子矩阵 A 可逆,则舒尔补定义为:
由式子,我们可以直接理解为,用A将C消为0,D所在的位置保留着A的信息,将这个位置定义为S。
2.2 信息矩阵
将Σ分块为:
信息矩阵由其逆矩阵得到:
信息矩阵可以看作对变量空间的“拉伸”或“压缩”操作。交叉项Λxy表示x和y的联合“拉伸方向”,边缘化需要调整剩余空间以消除x的拉伸影响。
2.3 分块信息矩阵与协方差矩阵的关系
边缘化变量x后,保留变量y的分布为:
![]()
其中μy是y的均值。在信息形式中,需表达为:
其中:
设联合高斯分布的信息形式为:
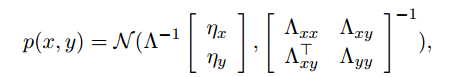
3.平方根信息矩阵的分解
若将信息矩阵分解为平方根形式 ,其中:
此时,边缘化后的信息矩阵为:
通过矩阵R的结构,边缘化可简化为直接截取 Ryy,避免显式计算Schur补,提升数值稳定性。
其联合概率可以表示为:
其中,
以上三种形式的适用条件以表格的形式给出:
| 形式 | 边缘化难易度 | 数学操作 | 依赖条件 | 适用场景 |
|---|---|---|---|---|
| 协方差形式 | 容易 | 直接选择协方差矩阵 | 无 | 直接概率解释 |
| 信息形式 | 困难 | Schur补计算 | 需要Schur补 | 需要增量更新,但未进行矩阵分解(如QR) |
| 平方根信息形式 | 有条件容易 | 若变量是连续块且被优先消除,则直接移除矩阵的前nx行/列(保留 Ryy) | 变量排序(需满足连续块消除条件) | 增量优化、稀疏结构、数值稳定性 |
下面,我们将来看看边缘化在固定滞后平滑和滤波中的作用。
固定滞后平滑和滤波
固定滞后平滑器是一种迭代算法,它交替测量更新步骤和边缘化步骤,以递归地保持最后n个状态的全密度。下面我将详细介绍书中所给例子(n=3)。
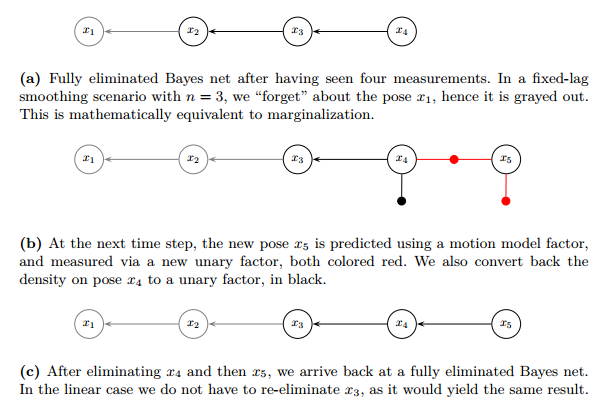
a.由于x₁没有依赖其他变量(无父节点)且不被其他变量依赖(无子节点),移除x₁后,剩余变量的联合分布仅保留与x₂、x₃等的相关性,无需调整其他变量的依赖关系。
b.添加新变量x₅,在这里引入了两个约束(红线):
二元因子:表示x₄与x₅之间的相对约束(如里程计或传感器测量)【f(x4,x5)】
一元因子:表示x₅的单目测量(如GPS或地标观测)。【f(x5)】
将x₅及其相关约束添加到因子图中,形成新的联合分布:
那么这里仅剩下f(x4)待处理:
将p(x₄)视为一个独立因子f(x₄),f(x4) 封装了历史数据对x4的所有影响(如之前的测量和边缘化结果)。通过将其显式表示为因子,新添加的约束直接与之结合,无需重新计算 x4的历史依赖。即:
c.边缘化x₂:移除与x₂相关的所有因子,并将x₂的影响通过Schur补(信息形式)或协方差截取(平方根信息形式)传递到剩余变量。
上面我们介绍了线性系统的处理方式,但实际上系统往往都是非线性的,接下来将介绍非线性系统的滤波和平滑。
非线性滤波与平滑
为了方便推理,这里引入了一种新的图结构:贝叶斯树。
贝叶斯树的构建
典型机器人问题的因子图包含许多循环,但我们仍然可以通过两步来构建树结构的图模型:
首先,对因子图进行变量消去,得到具有特殊性质(弦结构)的贝叶斯网;(在前面介绍过,将因子图转换为贝叶斯网时,会建立新的关系,这个过程很容易构建弦结构)
其次,利用该特殊性质在贝叶斯网中的团上找到树结构。
下面将介绍书中的例子,看看如何从贝叶斯网到贝叶斯树。
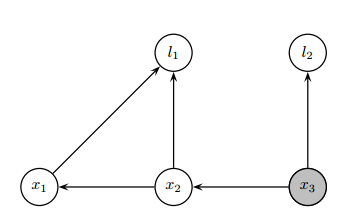
将弦图中的极大团作为节点,通过团之间的交集连接成树结构。每个团对应一个条件概率密度 p(Fk∣Sk),其中:Fk为当前团中首次被消除的变量。Sk为当前团与父团的交集变量,用于传递信息。于是,我们可以构造贝叶斯树如下所示。
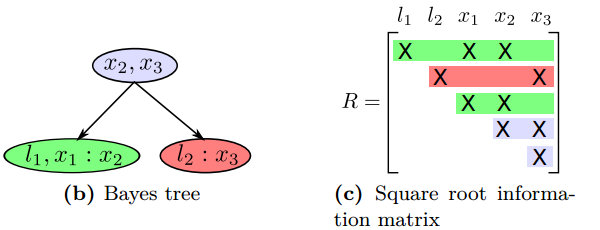
根节点对应最先消除的变量组成的团,子节点依次继承父节点的部分变量。根团C1={x2,x3}的子团C2={l1,x1,x2}和C3={l2,x3}通过分离变量x2和x3连接到根。
贝叶斯树更新机制
1. 定位受影响区域,此处是新增了变量x1和x3之间的关系,新增因子f(x2,x3)。
2.找到包含这些变量的所有团,并沿这些团到根节点的路径标记所有相关节点(红色虚线)。
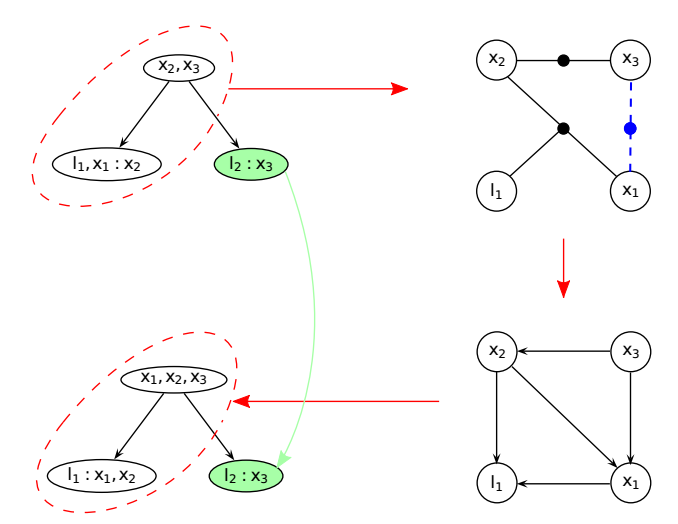
3.局部重构,将局部子图中的所有团条件概率 还原为原始因子(如二元约束或一元约束),将新增的测量因子f(x1,x3)加入因子图。通过变量消除生成新的弦图。
4.将新子树的根团与原树中最近的未受影响团连接。
综上,我们可知当机器人探索环境时,新的测量只影响树的一部分,并且只有这些部分被重新计算。
1、《Factor Graphs for Robot Perception》

















 4207
4207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









