







Trade-off between Robustness and Accuracy of Vision Transformers

本文 “Trade-off between Robustness and Accuracy of Vision Transformers” 提出了 TORA-ViTs(Trade-off between Robustness and Accuracy of Vision Transformers),旨在解决视觉 Transformer 在自然精度和对抗鲁棒性之间的权衡问题。通过添加精度和鲁棒性适配器分别提取预测性和鲁棒性特征,利用基于注意力的门控融合模块进行特征融合,并采用两阶段训练策略。在 ImageNet 数据集上的实验表明,TORA-ViTs 能有效提升自然预训练 ViT 的鲁棒性,同时保持有竞争力的自然精度,例如在最平衡设置下,干净 ImageNet 上准确率为 83.7% ,FGSM 和 PGD 白盒攻击下分别达到 54.7% 和 38.0% 的准确率。
摘要-Abstract
Although deep neural networks (DNNs) have shown great successes in computer vision tasks, they are vulnerable to perturbations on inputs, and there exists a trade-off between the natural accuracy and robustness to such perturbations, which is mainly caused by the existence of robust non-predictive features and non-robust predictive features. Recent empirical analyses find Vision Transformers (ViTs) are inherently robust to various kinds of perturbations, but the aforementioned trade-off still exists for them. In this work, we propose Trade-off between Robustness and Accuracy of Vision Transformers (TORA-ViTs), which aims to efficiently transfer ViT models pretrained on natural tasks for both accuracy and robustness. TORA-ViTs consist of two major components, including a pair of accuracy and robustness adapters to extract predictive and robust features, respectively, and a gated fusion module to adjust the trade-off. The gated fusion module takes outputs of a pretrained ViT block as queries and outputs of our adapters as keys and values, and tokens from different adapters at different spatial locations are compared with each other to generate attention scores for a balanced mixing of predictive and robust features. Experiments on ImageNet with various robust benchmarks show that our TORA-ViTs can efficiently improve the robustness of naturally pretrained ViTs while maintaining competitive natural accuracy. Our most balanced setting (TORA-ViTs with (\lambda=0.5) ) can maintain 83.7% accuracy on clean ImageNet and reach 54.7% and 38.0% accuracy under FGSM and PGD white-box attacks, respectively. In terms of various ImageNet variants, it can reach 39.2% and 56.3% accuracy on ImageNet-A and ImageNet-R and reach 34.4% mCE on ImageNet-C.
尽管深度神经网络(DNNs)在计算机视觉任务中取得了巨大成功,但它们容易受到输入扰动的影响,并且在自然精度和对这类扰动的鲁棒性之间存在权衡,这主要是由于存在鲁棒但非预测性的特征以及非鲁棒但具有预测性的特征。最近的实证分析发现,视觉Transformer(ViTs)对各种扰动具有内在的鲁棒性,但上述权衡对它们来说仍然存在。在这项工作中,我们提出了视觉Transformer的鲁棒性与准确性权衡(TORA-ViTs)方法,旨在有效地将在自然任务上预训练的ViT模型转移应用,以兼顾准确性和鲁棒性。TORA-ViTs由两个主要组件构成,包括一对分别用于提取预测性特征和鲁棒性特征的精度适配器和鲁棒性适配器,以及一个用于调整权衡的门控融合模块。门控融合模块将预训练的ViT块的输出作为查询,将我们的适配器的输出作为键和值,不同空间位置的不同适配器的标记相互比较,以生成注意力分数,从而平衡混合预测性特征和鲁棒性特征。在ImageNet数据集上使用各种鲁棒性基准进行的实验表明,我们的TORA-ViTs可以有效地提高自然预训练ViT的鲁棒性,同时保持具有竞争力的自然精度。我们最平衡的设置( λ = 0.5 \lambda = 0.5 λ=0.5 的TORA-ViTs)在干净的ImageNet数据集上可以保持83.7%的准确率,在FGSM和PGD白盒攻击下的准确率分别达到54.7%和38.0%。在各种ImageNet变体上,它在ImageNet-A和ImageNet-R上的准确率分别可以达到39.2%和56.3%,在ImageNet-C上的平均腐蚀误差(mCE)为34.4%。
引言-Introduction
该部分主要介绍了研究背景和动机,指出深度神经网络(DNNs)和视觉Transformer(ViTs)在发展中存在的问题,引出了TORA-ViTs方法,具体内容如下:
- DNNs的问题:DNNs在计算机视觉任务中取得了显著成果,但存在易受输入扰动影响的致命缺陷,输入扰动会导致其精度大幅下降。此外,自然精度和对抗鲁棒性之间存在权衡,这主要是由于存在两种不同类型的特征:一种是与任务适度相关且对攻击具有鲁棒性,但对准确预测贡献有限的特征;另一种是与任务弱相关且非鲁棒,但对提高精度至关重要的特征。尽管有许多研究试图控制或改善这种权衡,但在大规模数据集上仍难以有效实现。
- ViTs的现状:ViTs在各种任务中表现优异,许多后续工作致力于改进其变体以提高性能,但主要集中在干净数据上的自然精度。虽然实证分析表明ViTs对各种扰动具有一定的鲁棒性,但关注提高其鲁棒性的研究较少,且现有方法忽略了如何增强自然预训练ViT的鲁棒性。此外,ViTs的微调计算成本较高,在大规模数据集上训练既准确又鲁棒的ViT模型成本更为高昂。
- 提出TORA-ViTs:为解决上述问题,本文提出了TORA-ViTs,旨在同时提高ViT模型的实用性和可靠性。TORA-ViTs通过在现有ViT块的MLP层后添加精度和鲁棒性适配器,分别提取预测性和鲁棒性特征,并使用门控融合模块以权衡感知的方式组合这些特征。实验表明,TORA-ViTs可以有效提高自然预训练ViT的鲁棒性,同时保持具有竞争力的自然精度。
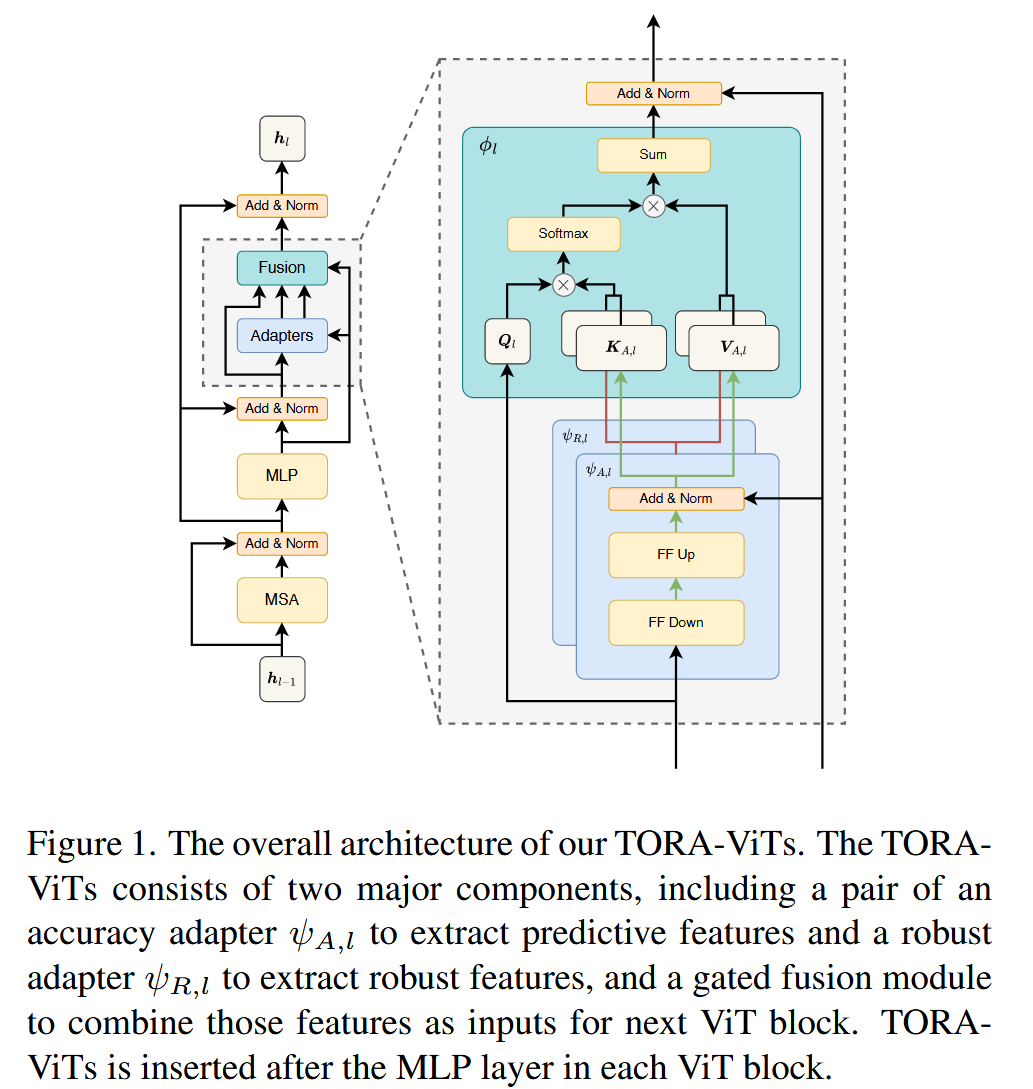
图1. 我们的TORA-ViTs整体架构。TORA-ViTs由两个主要组件构成,包括一对适配器(用于提取预测性特征的精度适配器
ψ
A
,
l
\psi_{A, l}
ψA,l 和用于提取鲁棒性特征的鲁棒性适配器
ψ
R
,
l
\psi_{R, l}
ψR,l),以及一个门控融合模块,该模块将这些特征进行组合,作为下一个ViT块的输入。TORA-ViTs被插入到每个ViT块的MLP层之后。
相关工作-Related Work
该部分主要介绍了与本文研究相关的工作,包括ViTs和适配器的发展,以及鲁棒视觉模型的研究现状,为后续提出的TORA-ViTs方法做铺垫,具体内容如下:
- ViTs和适配器
- ViTs发展:受自然语言处理中多头自注意力机制成功的启发,诸多研究尝试将Transformer应用于计算机视觉任务。如Image Transformer用于图像生成,Hu等人和Zhao等人设计局部多头点积自注意力块用于图像分类,Ramachandran等人扩展自注意力用于分类和目标检测。ViTs提出将图像分割为不重叠的补丁序列的嵌入方法,虽达到了最先进的准确率,但预训练成本高昂。DeiT通过蒸馏token改进训练,Naseer等人引入形状token,MAE提出基于ViTs的掩码自动编码器用于自监督学习。
- 适配器发展:在NLP领域,为降低Transformer训练和微调成本,适配器方法提出仅对预训练BERT添加和微调少量可训练参数,实现高效的文本分类任务迁移学习。AdapterFusion在此基础上,通过并行使用多个适配器并结合注意力机制进行知识组合,支持多任务学习。
- 鲁棒视觉模型
- CNNs的鲁棒性研究:对抗训练是增强CNNs对抗攻击能力的常用方法,如FGSM通过一步梯度上升生成对抗扰动,Madry等人提出更强的多步PGD方法。然而,TRADES揭示了自然精度和对抗鲁棒性之间的权衡,Kim等人利用信息瓶颈在中间特征空间提取鲁棒和非鲁棒特征,Yang等人提出解耦网络。
- 新的鲁棒性评估基准:除对抗攻击外,研究人员开始关注更多类型的扰动,如ImageNet-C考虑常见的视觉损坏,ImageNet-A考虑自然对抗示例,ImageNet-R考虑分布外数据。
- 基于架构的鲁棒性提升:研究发现神经网络的鲁棒性与其架构相关,一些研究通过神经架构搜索增强神经网络的对抗鲁棒性,如ConvNeXt通过手动微调架构展示了鲁棒性,Croce等人对传统ResNet-50架构的小修改也显著提高了对抗攻击的鲁棒性。
- ViTs的鲁棒性研究:有实证研究表明ViTs对各种扰动具有鲁棒性。为进一步提高其鲁棒性,RVT重新设计了ViTs的构建块,提出位置感知注意力缩放和补丁增强技术;PyramidAT通过金字塔攻击生成对抗示例;FAN研究了自注意力在学习鲁棒表示中的作用;Gu等人提出基于温度缩放的方法提高ViTs对对抗补丁的鲁棒性。
方法-Methodology
预备知识-Preliminary
该部分主要介绍了视觉Transformer在普通监督训练和对抗训练中的目标函数,为后续提出的方法提供理论基础,具体内容如下:
- 普通监督训练目标:对于训练集 D \mathcal{D} D 中的输入图像 x x x 及其相关标签 y y y,视觉Transformer的常见监督训练目标可表示为 L A C C ( f ; D ) = E ( x , y ) ∼ D [ ℓ C E ( f ( x ) , y ) ] \mathcal{L}_{ACC}(f ; \mathcal{D})=\mathbb{E}_{(x, y) \sim \mathcal{D}}\left[\ell_{CE}(f(x), y)\right] LACC(f;D)=E(x,y)∼D[ℓCE(f(x),y)] 。其中, ℓ C E \ell_{CE} ℓCE 是交叉熵函数,用于衡量模型预测结果 f ( x ) f(x) f(x) 与真实标签 y y y 之间的差异; f f f 代表视觉Transformer模型。该公式表明,普通监督训练旨在通过最小化交叉熵损失,使模型的预测尽可能接近真实标签,从而提高模型在正常数据上的分类准确性。
- 对抗训练目标:为提高模型对输入扰动的对抗鲁棒性,常用对抗训练方法。在对抗训练中,通过梯度上升生成扰动来攻击目标模型,并在这种攻击下优化目标模型。通常将带有扰动的对抗样本 x ′ x' x′ 限制在以自然样本 x x x 为中心的 l p l_{p} lp 球 B p ( x , ε ) = { x ′ : ∥ x − x ′ ∥ p ≤ ε } B_{p}(x, \varepsilon)=\{x':\left\|x - x'\right\|_{p} \leq \varepsilon\} Bp(x,ε)={x′:∥x−x′∥p≤ε} 内,其中 ε \varepsilon ε 定义了允许的扰动尺度, ∥ ⋅ ∥ p \|\cdot\|_{p} ∥⋅∥p 是 l p l_{p} lp 范数。对抗训练可形成一个极小极大问题,其目标函数定义为 L R O B ( f ; D ) = E ( x , y ) ∼ D [ max x ′ ∈ B p ( x , ε ) ℓ C E ( f ( x ′ ) , y ) ] \mathcal{L}_{ROB}(f ; \mathcal{D})=\mathbb{E}_{(x, y) \sim \mathcal{D}}\left[\max_{x' \in \mathcal{B}_{p}(x, \varepsilon)} \ell_{CE}\left(f\left(x'\right), y\right)\right] LROB(f;D)=E(x,y)∼D[maxx′∈Bp(x,ε)ℓCE(f(x′),y)]。该公式意味着在对抗训练时,模型需要在面对最大程度的扰动时,仍能尽可能准确地对样本进行分类,以此提升模型的对抗鲁棒性。
鲁棒性与准确性适配器-Robustness and Accuracy Adapters
该部分主要阐述了在现有ViT模型中插入鲁棒性和准确性适配器的原因、方法和架构,具体内容如下:
- 插入适配器的原因:现成的视觉Transformer通常通过追求自然精度的方式进行训练,但以对抗鲁棒性为新目标进行标准微调时,可能会导致模型权重偏离初始状态,进而降低自然精度。为兼顾自然精度和对抗鲁棒性,需要新的方法来增强模型的鲁棒性。
- 适配器的插入位置与功能:在现有 ViT 块的 MLP 层后插入两个适配器,分别是用于提取预测性特征的准确性适配器 ψ A , l \psi_{A, l} ψA,l 和用于提取鲁棒性特征的鲁棒性适配器 ψ R , l \psi_{R, l} ψR,l。对于MLP层输出的特征 z l ∈ R N × d m z_{l} \in \mathbb{R}^{N ×d_{m}} zl∈RN×dm( 1 ≤ l ≤ L 1 ≤l ≤L 1≤l≤L 表示第 l l l 个块, N N N 为token数量, d m d_{m} dm 为维度),准确性适配器的输出为 a l = ψ A , l ( z l ) a_{l}=\psi_{A, l}\left(z_{l}\right) al=ψA,l(zl),鲁棒性适配器的输出为 r l = ψ R , l ( z l ) r_{l}=\psi_{R, l}\left(z_{l}\right) rl=ψR,l(zl) , a l a_{l} al 和 r l r_{l} rl 分别代表预测性和鲁棒性特征,且都属于 R N × d m \mathbb{R}^{N ×d_{m}} RN×dm。
- 适配器的架构:采用Houlsby等人提出的架构,使用两个带瓶颈和残差连接的前馈层。选择在现有ViT块的MLP层后插入适配器,而不在多头注意力(MSA)后插入,这样的架构设计有助于实现提取不同类型特征的功能,且整体架构如图1所示(原文中对应图1展示了TORA-ViTs的整体架构)。
基于注意力的门控融合-Attention-based Gated Fusion
该部分主要介绍了基于注意力的门控融合模块,该模块用于以权衡感知的方式组合由精度和鲁棒性适配器提取的特征,具体内容如下:
- 融合原理:为了将精度和鲁棒性适配器提取的特征进行有效融合,提出基于注意力的门控融合模块。该模块先计算ViT块输出特征与适配器输出特征之间的点积注意力分数矩阵,再对分数矩阵按适配器维度应用softmax函数,将softmax结果作为加权门,以融合预测性和鲁棒性特征。
- 计算过程
- 计算注意力分数矩阵:以 ViT 块输出的特征 z t z_{t} zt 生成查询,适配器输出的特征 a l a_{l} al 和 r t r_{t} rt 生成键,计算两对Q-K之间的点积,得到注意力分数矩阵。具体公式为 s A , l = ( z l ⋅ w Q , l ) ⋅ ( a l ⋅ w K , l ) ⊤ s_{A, l}=(z_{l} \cdot w_{Q, l}) \cdot (a_{l} \cdot w_{K, l})^{\top} sA,l=(zl⋅wQ,l)⋅(al⋅wK,l)⊤ 和 s R , l = ( z l ⋅ w Q , l ) ⋅ ( r l ⋅ w K , l ) ⊤ s_{R, l}=(z_{l} \cdot w_{Q, l}) \cdot (r_{l} \cdot w_{K, l})^{\top} sR,l=(zl⋅wQ,l)⋅(rl⋅wK,l)⊤,其中 s A , l s_{A, l} sA,l、 s R , l ∈ R N × N s_{R, l} \in R^{N ×N} sR,l∈RN×N 分别是精度适配器和鲁棒性适配器的注意力分数矩阵, w Q , l w_{Q, l} wQ,l、 w K , l ∈ R d m × d q w_{K, l} \in \mathbb{R}^{d_{m} ×d_{q}} wK,l∈Rdm×dq 是查询和键矩阵的投影参数,且投影参数在适配器之间共享。
- 应用softmax函数:对注意力分数矩阵按适配器维度应用softmax函数,公式为 s A , l , m , n ′ = e x p ( s A , l , m , n ) ∑ k ∈ { A , R } e x p ( s k , l , m , n ) s_{A, l, m, n}'=\frac{exp (s_{A, l, m, n})}{\sum_{k \in\{A, R\}} exp (s_{k, l, m, n})} sA,l,m,n′=∑k∈{A,R}exp(sk,l,m,n)exp(sA,l,m,n) 和 s R , l , m , n ′ = e x p ( s R , l , m , n ) ∑ k ∈ { A , R } e x p ( s k , l , m , n ) s_{R, l, m, n}'=\frac{exp (s_{R, l, m, n})}{\sum_{k \in\{A, R\}} exp (s_{k, l, m, n})} sR,l,m,n′=∑k∈{A,R}exp(sk,l,m,n)exp(sR,l,m,n)。通过这种方式,如果一个适配器中的某个token对应的注意力分数比另一个大,它将被赋予更大的权重,反之亦然,从而起到选择特征的作用。
- 计算注意力模块输出:与键类似,值也由适配器的特征生成。应用权重后,计算每个适配器的注意力模块输出,公式为 o A , l = s A , l ′ ⊤ ⋅ ( a l ⋅ w V , l ) o_{A, l}=s_{A, l}^{\prime \top} \cdot (a_{l} \cdot w_{V, l}) oA,l=sA,l′⊤⋅(al⋅wV,l)和 o R , l = s R , l ′ ⊤ ⋅ ( r l ⋅ w V , l ) o_{R, l}=s_{R, l}^{\prime \top} \cdot (r_{l} \cdot w_{V, l}) oR,l=sR,l′⊤⋅(rl⋅wV,l),其中 o A , l o_{A, l} oA,l、 o R , l ∈ R N × d m o_{R, l} \in \mathbb{R}^{N ×d_{m}} oR,l∈RN×dm, w V , l ∈ R d m × d v w_{V, l} \in \mathbb{R}^{d_{m} ×d_{v}} wV,l∈Rdm×dv 是值矩阵的投影参数。
- 最终输出:直接将 O A , l O_{A, l} OA,l 和 o R , l o_{R, l} oR,l 按适配器维度相加,得到 o l = ∑ k ∈ { A , R } o k , l o_{l}=\sum_{k \in\{A, R\}} o_{k, l} ol=∑k∈{A,R}ok,l,确保 o l o_{l} ol 与 z t z_{t} zt 维度相同。最后,添加来自ViT块输出的残差连接,并进行层归一化,得到最终层输出 h l = z l + L N ( o l ) h_{l}=z_{l}+LN\left(o_{l}\right) hl=zl+LN(ol),其中 L N ( ⋅ ) LN(·) LN(⋅) 是层归一化操作。
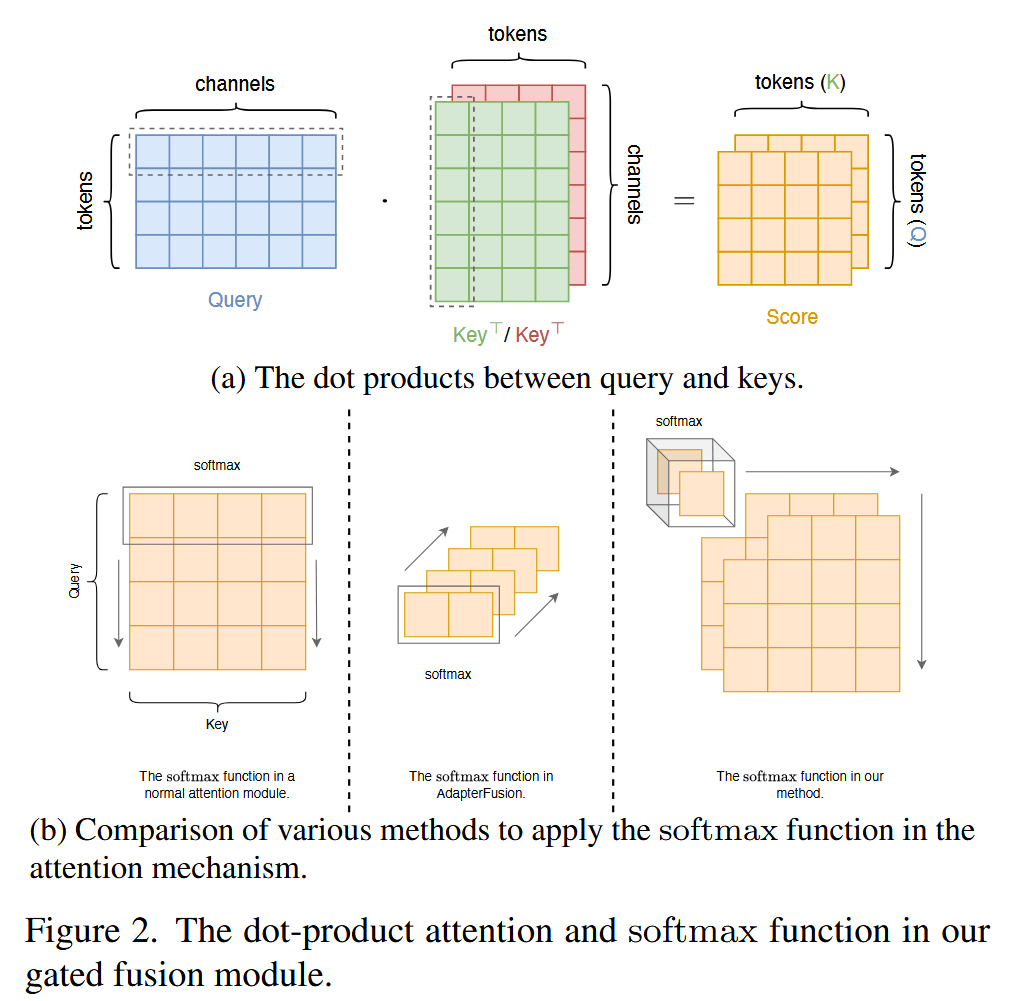
图2. 我们门控融合模块中的点积注意力机制和softmax函数。
Two-Phase Trade-off Training-两阶段权衡训练
该部分主要介绍了TORA-ViTs的两阶段权衡训练策略,包括训练过程、添加的特殊token以及不同阶段的优化目标,具体内容如下:
- 特殊token添加:借鉴ViTs中添加分类token
[CLS]的方式,为了进行权衡训练,在TORA-ViTs中添加了准确性token[ACC]和鲁棒性token[ROB]。具体操作是将原类token(位于输出的第一维,即 [ C L S ] : = z l , 1 , : [CLS] :=z_{l, 1,:} [CLS]:=zl,1,: )中的 z l , 1 , 2 z_{l, 1,2} zl,1,2 替换为准确性token [ A C C ] l − 1 [ACC]_{l - 1} [ACC]l−1 和鲁棒性token [ R O B ] l − 1 [ROB]_{l - 1} [ROB]l−1,以此作为适配器的输入。相应地,准确性适配器和鲁棒性适配器的输入公式变为 a l = ψ A , l ( C o n c a t ( [ A C C ] l − 1 , z l , 2 : , : ) ) a_{l}=\psi_{A, l}\left(Concat\left([ACC]_{l - 1}, z_{l, 2:,:}\right)\right) al=ψA,l(Concat([ACC]l−1,zl,2:,:))和 r l = ψ R , l ( C o n c a t ( [ R O B ] l − 1 , z l , 2 : , : ) ) r_{l}=\psi_{R, l}\left(Concat\left([ROB]_{l - 1}, z_{l, 2:,:}\right)\right) rl=ψR,l(Concat([ROB]l−1,zl,2:,:)) 。经过适配器处理后,可以得到 [ A C C ] l = a l , 1 , : [ACC]_{l}=a_{l, 1,:} [ACC]l=al,1,:和 [ R O B ] l = r l , 1 , : [ROB]_{l}=r_{l, 1,:} [ROB]l=rl,1,: 。为了完成最终分类,还添加了准确性分类头 f A C C f_{ACC} fACC和鲁棒性分类头 f R O B f_{ROB} fROB ,并将它们的预测结果进行平均作为最终预测。 - 两阶段训练策略
- 第一阶段:独立优化每个适配器及其特定目标,同时优化融合模块。在这个阶段,使用普通监督训练目标 L A C C ( f ; D ) \mathcal{L}_{ACC}(f ; \mathcal{D}) LACC(f;D) 和对抗训练目标 L R O B ( f ; D ) \mathcal{L}_{ROB}(f ; \mathcal{D}) LROB(f;D) 分别对相应的适配器进行交替优化,暂时忽略权衡比 λ \lambda λ 。这里 F = { f , Ψ R , Ψ A , Φ } F = \{f, \Psi_{R}, \Psi_{A}, \Phi\} F={f,ΨR,ΨA,Φ} 表示包含适配器和门控融合的TORA-ViT模型,其中 Ψ R = { ψ R , l ∣ 1 ≤ l ≤ L } \Psi_{R}=\{\psi_{R, l} | 1 ≤l ≤L\} ΨR={ψR,l∣1≤l≤L} 、 Ψ A = { ψ A , l ∣ 1 ≤ l ≤ L } \Psi_{A}=\{\psi_{A, l} | 1 ≤l ≤L\} ΨA={ψA,l∣1≤l≤L} 分别是所有层的鲁棒性适配器和准确性适配器集合, Φ = { ϕ l ∣ 1 ≤ l ≤ L } \Phi=\{\phi_{l} | 1 ≤l ≤L\} Φ={ϕl∣1≤l≤L} 是门控融合模块集合。
- 第二阶段:在第一阶段每个组件达到合适性能后,冻结两个适配器,使用联合的鲁棒性和准确性目标优化融合模块。在这个阶段引入权衡比 λ \lambda λ ,通过联合优化使融合模块 Φ \Phi Φ 更好地根据 λ \lambda λ 进行权衡调整,以平衡模型的准确性和鲁棒性。因为在第一阶段融合模块可能会偏向当前优化的目标,所以第二阶段的联合优化至关重要,它使得模型在不同任务需求下能够更合理地平衡两种特性。
实验-Experiments
该部分主要介绍了实验设置、与现有方法对比、分类头和权衡比分析、调优方法比较以及注意力图可视化,验证了TORA - ViTs的有效性,具体如下:
- 实验设置
- 模型选择:选用ViT - B/16架构,输入大小224×224,补丁大小16×16,嵌入维度768,12层,使用Steiner等人提供的预训练参数初始化。
- 训练细节:训练时冻结现有ViT块,用AdamW优化器,初始学习率0.0001,以0.97的速率进行步长衰减。采用单步FGSM( ε = 1 / 255 \varepsilon = 1/255 ε=1/255)生成对抗样本,共训练9个epoch,前6个epoch交替优化适配器和融合模块,后3个epoch进行联合优化。
- 评估指标:针对白盒攻击,使用单步FGSM和5步PGD(步长0.5/255)在ImageNet - 1K上测试;对于自然对抗样本、分布外数据和常见损坏,分别使用ImageNet - A、ImageNet - R和ImageNet - C进行评估。
- 与SOTA方法对比:将TORA - ViT与自然训练的CNNs、鲁棒CNNs、自然训练的ViTs和鲁棒ViTs这4类SOTA方法比较。在
λ
=
0.5
\lambda = 0.5
λ=0.5 的最平衡设置下,TORA - ViT在所有指标上优于先前工作,如比Swin - B的干净数据自然精度高0.3% ,比RVT - B在FGSM攻击下精度高1.7%等。
λ
=
0.1
\lambda = 0.1
λ=0.1 时侧重自然精度,比Swin - B自然精度高0.7% ,在鲁棒性上也有不错表现;
λ
=
0.9
\lambda = 0.9
λ=0.9 时侧重对抗鲁棒性,比RVT - B在FGSM和PGD攻击下精度分别提高21.2%和27.6% 。
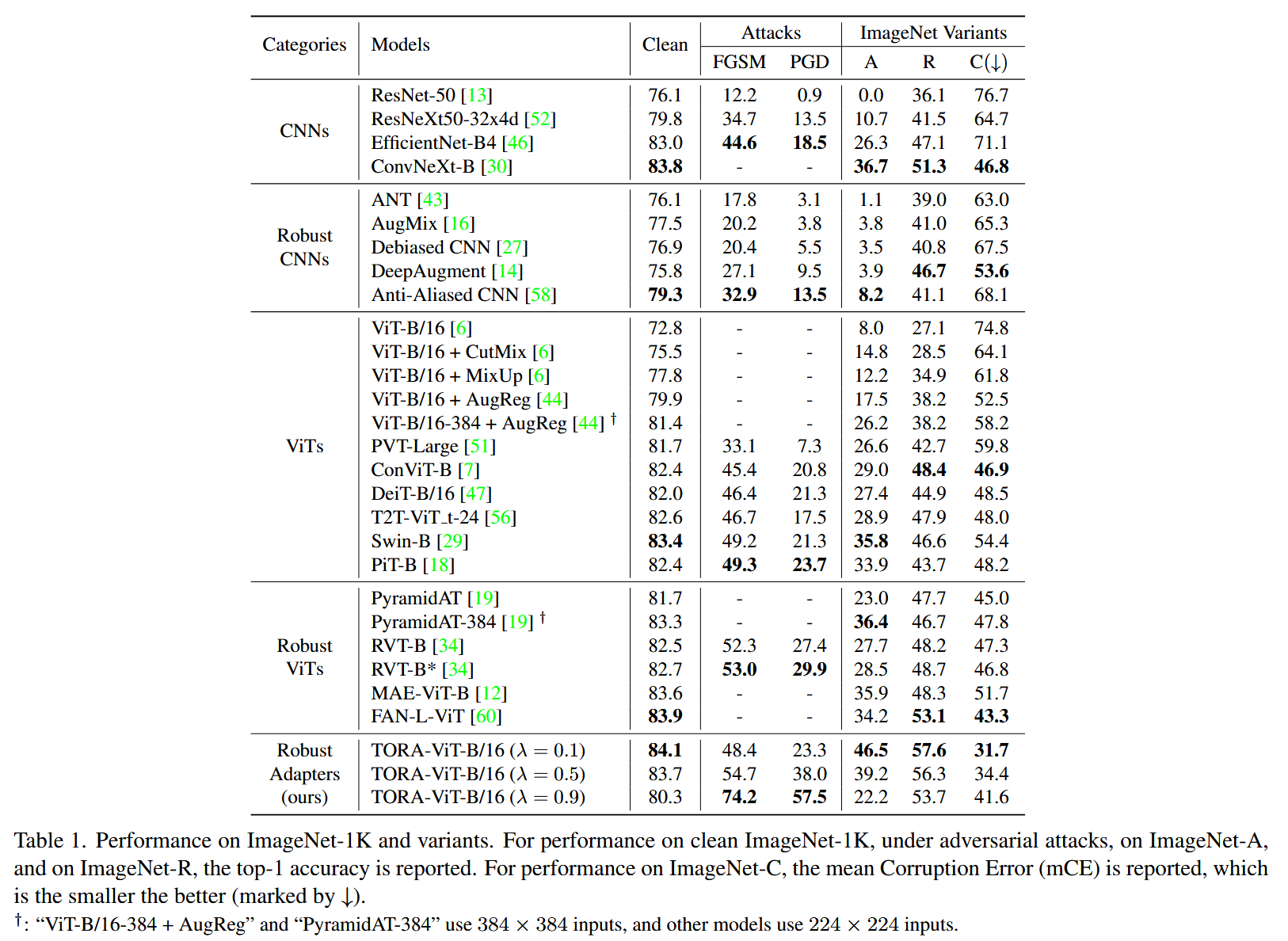
表1. 在ImageNet-1K及其变体上的性能表现。对于在干净的ImageNet-1K、对抗攻击下、ImageNet-A以及ImageNet-R上的性能,报告的是top-1准确率。对于在ImageNet-C上的性能,报告的是平均腐蚀误差(mCE),该值越小越好(用↓标记)。 - 分类头和权衡比分析:不同分类头在不同任务上表现不同。自然精度和对抗攻击鲁棒性与
λ
\lambda
λ 相关,
λ
\lambda
λ 增大时,对抗鲁棒性提升但自然精度下降。在其他扰动下,
λ
<
0.5
\lambda < 0.5
λ<0.5 时,鲁棒头表现更好;
λ
=
0.5
\lambda = 0.5
λ=0.5 时,精度头在ImageNet - A上表现更优;
λ
>
0.5
\lambda > 0.5
λ>0.5 时,精度头在ImageNet - A和ImageNet - R上表现更好,而鲁棒头在ImageNet - C上始终表现更好。
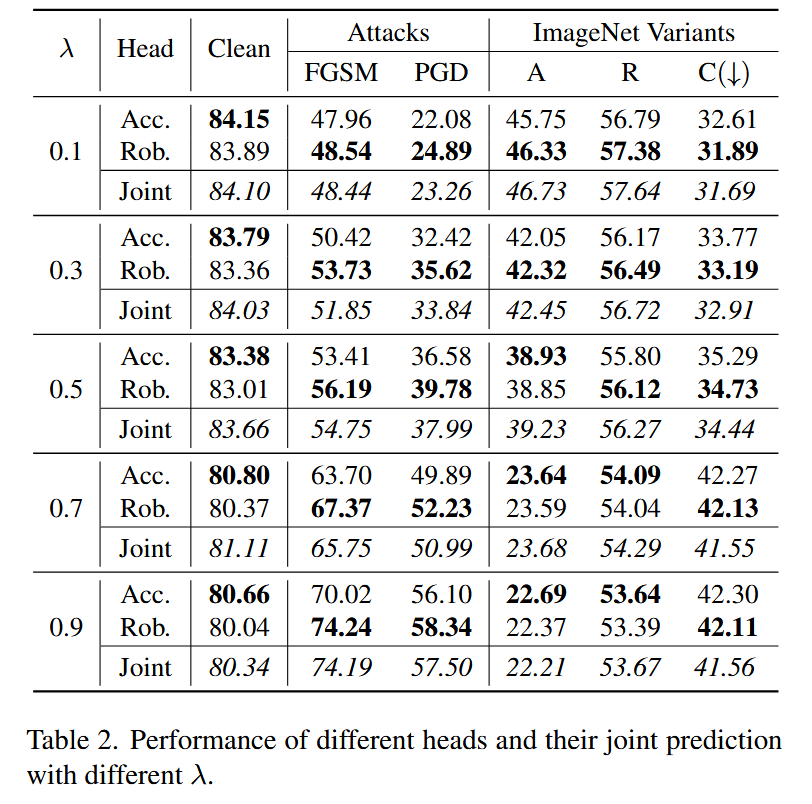
表2. 不同分类头以及不同 λ λ λ 值下它们的联合预测性能。 - 调优方法比较:将TORA - ViT与仅调整新分类头、调整单个新鲁棒性适配器和使用AdapterFusion调整两个新适配器这三种方法对比。TORA - ViT与AdapterFusion的FLOPs和参数数量相似,训练仅多需约10分钟(0.16 GPU小时)。仅调整新分类头难以提高鲁棒性,调整单个新适配器难以控制权衡,AdapterFusion虽强于前两者,但无法区分鲁棒和预测性特征,TORA - ViT凭借基于补丁级注意力区分特征,性能最优。
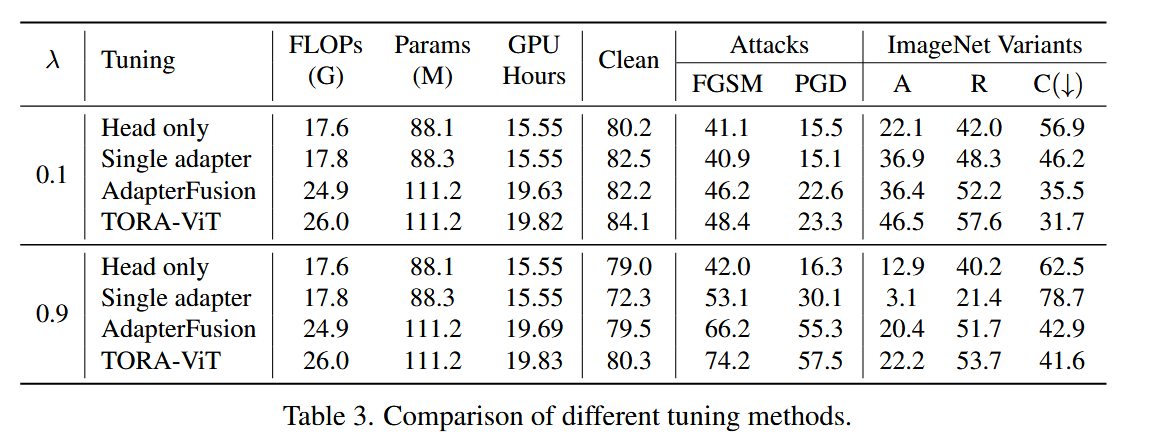
表3. 不同调优方法的比较。 - 注意力图可视化:可视化门控融合模块中不同适配器的注意力分数,发现精度适配器更关注上下文,鲁棒性适配器更关注分类对象。当
λ
=
0.1
\lambda = 0.1
λ=0.1 时,精度适配器特征注意力更高;
λ
=
0.9
\lambda = 0.9
λ=0.9 时,鲁棒性适配器特征注意力更高;
λ
=
0.5
\lambda = 0.5
λ=0.5 时,两者注意力分布不同区域且数量相似,验证了相关理论。

图3. 不同 λ λ λ 比例下门控融合模块中不同适配器的注意力可视化。使用蓝 - 白 - 红颜色映射,其中红色表示高注意力,蓝色表示低注意力。可以看出,精度适配器产生的特征更多地关注上下文,相比之下,鲁棒性适配器产生的特征更多地关注要分类的主要对象。这与鲁棒非预测性特征和预测性非鲁棒特征的理论一致。
结论-Conclusion
该部分主要总结了本文的研究成果,强调了TORA-ViTs的设计原理、优势及验证结果,具体内容如下:
- 方法概述与原理:本文提出了视觉Transformer的鲁棒性与准确性权衡(TORA-ViTs)方法。该方法受预测性非鲁棒和鲁棒性非预测性特征理论的启发,通过引入精度适配器和鲁棒性适配器,分别提取预测性和鲁棒性特征,进而全面捕捉图像特征。同时,基于注意力的门控融合模块以权衡感知的方式组合这两类特征,使得模型能根据不同任务需求灵活调整特征融合策略。
- 实验验证优势:在ImageNet数据集上,使用多种鲁棒性基准进行实验,结果表明TORA-ViTs能够有效提升自然预训练ViT的鲁棒性,并且在提升鲁棒性的同时,还能保持具有竞争力的自然精度。例如,在最平衡设置( λ = 0.5 \lambda = 0.5 λ=0.5)下,在干净的ImageNet数据集上准确率可达83.7%,在FGSM和PGD白盒攻击下,准确率分别能达到54.7%和38.0%,在ImageNet-A、ImageNet-R等变体数据集上也有出色表现 。
- 理论可视化验证:通过对门控融合模块中注意力图的可视化,从经验上证明了鲁棒非预测性特征和预测性非鲁棒性特征的理论。可视化结果清晰展示出精度适配器更关注上下文,而鲁棒性适配器更聚焦于分类对象,这与理论预期相符,为方法的设计提供了直观的证据支持。


















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











