







Swin-UMamba
背景
医学图像分割的重要性:
- 医学图像分割在临床实践中扮演着至关重要的角色,例如辅助诊断、制定治疗方案和实施治疗。
- 传统的医学图像分割依赖于经验丰富的医生,这是一个劳动密集型和耗时的过程,并且容易受到主观解释和观察者间差异的影响。
- 自动化医学图像分割方法可以提高效率、准确性和一致性,从而帮助医生做出更准确、更快速的诊断。
现有方法的局限性:
- 卷积神经网络 (CNNs): CNNs 擅长提取局部特征,但在捕捉全局上下文和长距离依赖关系方面存在局限性,因为它们受限于局部感受野。
- 视觉Transformer (ViTs): ViTs 能够处理全局上下文和长距离依赖关系,但其注意力机制具有高二次复杂度,限制了它们在处理高分辨率图像时的效率。此外,ViTs 在处理有限数据集时容易过拟合,需要大量的训练数据。
Mamba 模型的潜力:
- Mamba 模型是一种基于结构化状态空间序列模型 (SSM) 的模型,能够以线性或近线性复杂度建模长序列,在自然语言处理和基因组分析等领域取得了优异的性能。
- Mamba 模型在视觉任务中也展现出潜力,能够以更高的精度、更低的计算负担和更少的内存消耗优于现有的视觉模型。
预训练的重要性:
- 预训练模型在医学图像分析中已被证明非常有效,可以帮助模型更好地泛化到新的数据集,并减少训练数据量的需求。
- 由于医学图像数据集通常规模较小且多样性有限,预训练模型对于数据高效的医学图像分析尤为重要。
挑战:
- 如何将通用的预训练模型有效地整合到医学图像分割任务中,并利用其迁移学习的能力。
- 如何设计高效且可扩展的 Mamba-based 模型,以便在实际应用中进行部署。
要解决的问题
1. 长距离依赖关系建模:
- 现有的 CNN 和 ViT 模型在捕捉图像中的长距离依赖关系方面存在局限性,这导致分割结果不够精确。
- Swin-UMamba 利用 Mamba 模型的长距离依赖建模能力,能够更好地捕捉图像中的全局上下文信息,从而提高分割精度。
2. 数据效率:
- 医学图像数据集通常规模较小且多样性有限,这使得模型容易过拟合,需要大量的训练数据才能取得良好的性能。
- Swin-UMamba 利用 ImageNet 预训练模型的优势,可以有效地减少训练数据量的需求,提高模型的数据效率。
3. 模型效率:
- 现有的 ViT 模型在处理高分辨率图像时计算量较大,限制了其在实际应用中的部署。
- Swin-UMamba 的编码器部分采用预训练模型,解码器部分采用轻量级结构,从而降低了模型的计算量和内存消耗,提高了模型效率。
4. 预训练模型的有效整合:
- 现有的 Mamba-based 模型大多从零开始训练,没有充分利用预训练模型的优势。
- Swin-UMamba 设计了一个与预训练模型兼容的编码器结构,能够有效地整合预训练模型的知识,提高模型的性能。
5. 模型的可扩展性:
- Swin-UMamba 提供了两种模型变体:Swin-UMamba 和 Swin-UMamba†。Swin-UMamba† 进一步降低了模型参数和计算量,使其更适合在资源受限的环境中部署。
要做的任务,输入输出
任务: Swin-UMamba 的主要任务是进行 2D 医学图像分割,即将图像中的不同组织或器官进行区分和标记。
- 输入: Swin-UMamba 的输入是 2D 医学图像,例如 MRI、CT 扫描或显微镜图像。
- 输出: Swin-UMamba 的输出是分割结果,即一个与输入图像大小相同的图像,其中每个像素都被标记为属于特定的类别,例如器官、组织或细胞。
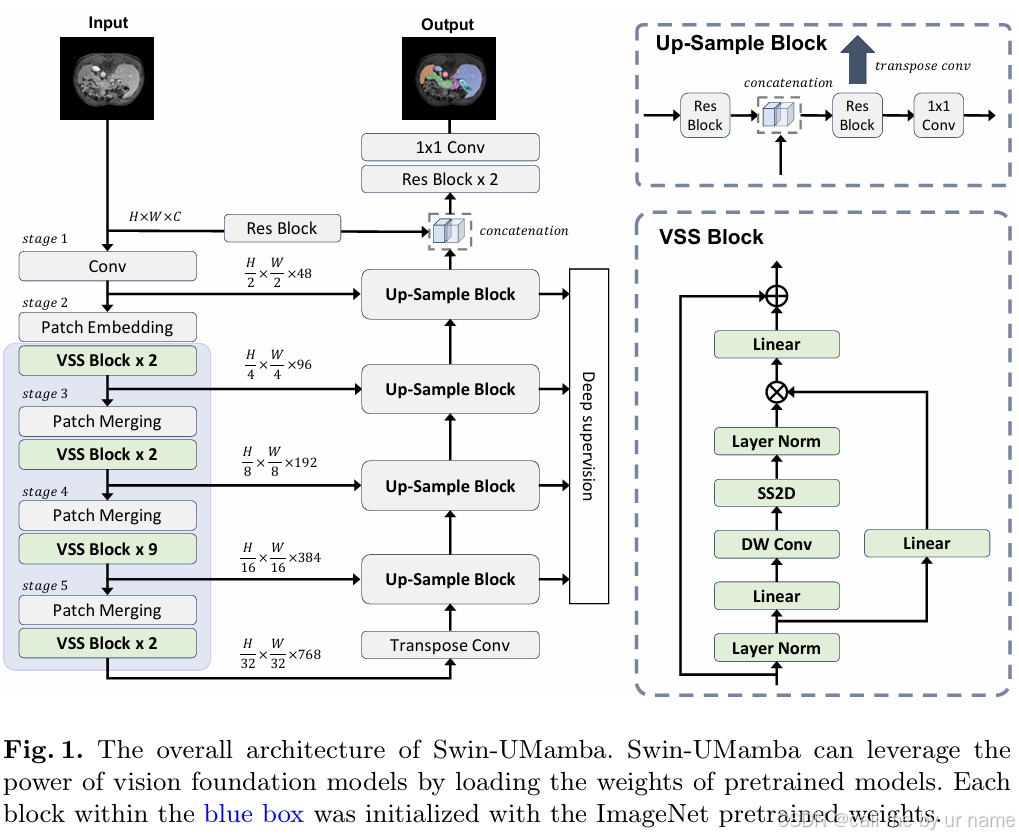
模型工作流程:
- 编码器: 编码器部分使用预训练的 VMamba-Tiny 模型提取图像的多尺度特征。VMamba-Tiny 模型采用视觉状态空间 (VSS) 块作为基本单元,能够有效地捕捉图像中的长距离依赖关系。
- 解码器: 解码器部分采用 U-Net 风格的结构,通过跳跃连接和深度监督机制恢复图像细节并预测分割结果。
- 深度监督: Swin-UMamba 在多个尺度上应用深度监督,即在每个解码器阶段都添加一个分割头,以帮助模型更好地学习不同尺度上的特征,从而提高分割精度。
- 最终输出: Swin-UMamba 的最终输出是通过 1x1 卷积层得到的分割结果图像。
详解框架
1. 编码器:
- 主干网络 (Stem): 采用一个 7x7 卷积层进行 2 倍下采样,并使用 2D 实例归一化。
- Patch Embedding 层: 将图像分割成 2x2 的大块,并使用线性层将每个 patch 映射到一个特征向量。
- VSS 块 (Visual State Space Block): VSS 块是 Swin-UMamba 的核心模块,它利用 2D 选择性扫描 (SS2D) 技术,将图像块沿着四个方向展开成四个序列,然后分别对每个序列进行 SSM 处理,最后将输出特征合并成一个完整的 2D 特征图。
- Patch Merging 层: 将特征图进行 2 倍下采样,并使用线性层和深度可分离卷积层增加特征维度。
- 编码器结构: 编码器由 5 个阶段组成,每个阶段都包含一个 Patch Merging 层和多个 VSS 块。随着阶段的增加,特征维度逐渐增加,感受野也逐渐扩大。
2. 解码器:
- 上采样块 (Up-Sample Block): 上采样块使用转置卷积进行 2 倍上采样,并使用卷积块和跳跃连接来恢复图像细节。
- 深度监督 (Deep Supervision): Swin-UMamba 在每个解码器阶段都添加了一个分割头,以帮助模型更好地学习不同尺度上的特征,从而提高分割精度。
- 解码器结构: 解码器采用 U-Net 风格的结构,通过跳跃连接将编码器中的低层特征与解码器中的高层特征融合,以恢复图像细节。
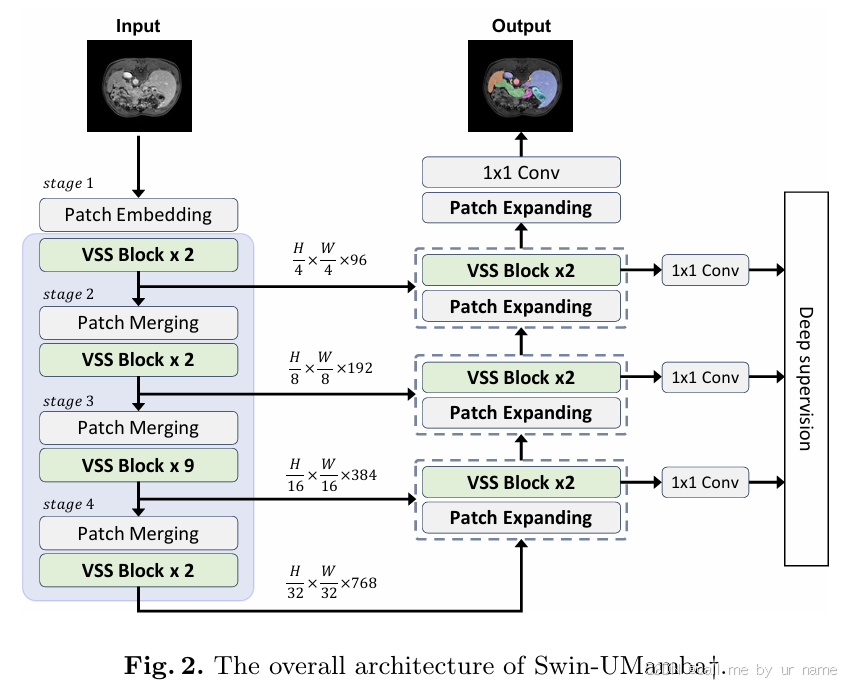
3. Swin-UMamba† 的特点:
- Mamba-based 解码器: Swin-UMamba† 的解码器也采用了 Mamba-based 结构,进一步减少了模型参数和计算量。
- Patch Expanding 层: Swin-UMamba† 使用 Patch Expanding 层进行上采样,而不是转置卷积。
- 更小的 Patch Embedding 层: Swin-UMamba† 使用 4x4 的 Patch Embedding 层,进一步降低了模型参数和计算量。
- 更深的模型: Swin-UMamba† 的编码器部分比 Swin-UMamba 更深,从而能够提取更丰富的特征。
4. 模型优势:
- 长距离依赖关系建模: VSS 块能够有效地捕捉图像中的长距离依赖关系,从而提高分割精度。
- 数据效率: 预训练模型能够有效地减少训练数据量的需求,提高模型的数据效率。
- 模型效率: Swin-UMamba† 的 Mamba-based 解码器进一步降低了模型参数和计算量,使其更适合在资源受限的环境中部署。
- 可扩展性: Swin-UMamba 和 Swin-UMamba† 提供了不同的模型结构,可以根据不同的应用需求进行选择。
实验
数据集:
Swin-UMamba 在三个不同的医学图像分割数据集上进行了评估,以验证其性能和可扩展性:
- 腹部 MRI 数据集 (AbdomenMRI): 该数据集包含 60 个 MRI 扫描图像,用于分割 13 个腹部器官。
- 内窥镜图像数据集 (Endoscopy): 该数据集包含 1800 个内窥镜图像,用于分割 7 种手术器械。
- 显微镜图像数据集 (Microscopy): 该数据集包含 1000 个显微镜图像,用于分割细胞。
基线方法:
Swin-UMamba 与以下几种基线方法进行了比较:
- CNN-based: nnU-Net, SegResNet
- Transformer-based: UNETR, Swin-UNETR, nnFormer
- Mamba-based: U-Mamba_Bot, U-Mamba_Enc
评价指标: - 腹部 MRI 和内窥镜数据集: Dice 相似系数 (DSC) 和归一化表面距离 (NSD)
- 显微镜数据集: F1 分数
- 模型复杂度: 模型参数数量 (#param) 和浮点运算次数 (FLOPs)
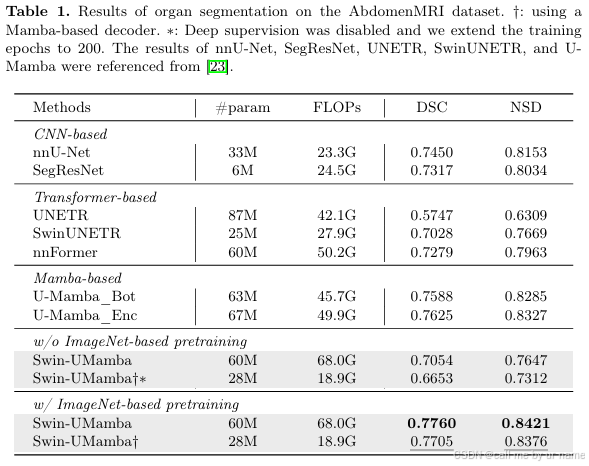
w/o imagenet-based pre-training——without ……
w/ imagenet-based pre-training——with……
SegMamba
背景
这篇论文的背景聚焦于3D医学图像分割,它是计算机辅助诊断中的关键技术。
-
传统方法的局限性:
- 卷积神经网络(CNN):尽管大核卷积(如 7×7×7)可以扩展感受野,但CNN的局限在于其难以建模全局关系,更多关注局部特征。
- Transformer架构:近年来,Transformer通过自注意力机制在全局建模方面展现了强大能力,例如UNETR和SwinUNETR。然而,自注意力的计算复杂度是序列长度的平方,这对于高维医学图像(如3D CT扫描)来说计算负担过重。
-
Mamba模型的引入:
- Mamba是基于**状态空间模型(SSM)**的一种方法,因其卓越的内存效率和计算速度在自然语言处理领域表现出色。
- 与Transformer相比,Mamba的计算复杂度更低,特别适合长序列建模。
-
研究动机:
- 在3D医学图像分割中,如何同时保持全局关系建模能力和计算效率是一个亟需解决的问题。
- 现有的Mamba模型主要应用于自然语言处理或2D图像建模,而在3D医学图像分割中的应用仍是空白。
-
论文的贡献:
- 提出了SegMamba,一种基于Mamba的新型3D医学图像分割框架,能够高效地建模全局特征并处理长序列输入。
- 设计了新的模块(如三向Mamba模块、门控空间卷积模块等),提升了分割性能。
- 构建了一个大规模的数据集CRC-500,包含500例3D结直肠癌CT扫描,为相关研究提供了宝贵资源。
现有方法:
- 基于 CNN 的方法:
- 使用大核卷积层来扩大感受野,例如 3D UX-Net。
- 缺乏全局建模能力,难以处理复杂场景。
- 基于 Transformer 的方法:
- 使用自注意力机制提取全局信息,例如 UNETR 和 SwinUNETR。
- 计算复杂度高,难以处理高分辨率图像。
要解决的问题
论文中要解决的核心问题是如何在3D医学图像分割任务中高效建模长距离依赖关系,同时保持计算效率和准确性。具体问题包括:
1. 长序列建模的计算负担
- 传统方法(如基于Transformer的UNETR和SwinUNETR)虽然能够通过自注意力机制建模全局特征,但其计算复杂度为序列长度的平方。在处理高分辨率3D医学图像(如分辨率为64×64×64的体积)时,这种复杂度会导致巨大的计算负担和内存开销。
2. 局部与全局信息的结合
- 卷积神经网络(CNN)由于卷积核的局限性,主要捕捉局部特征,难以有效建模全局关系。
- 在3D图像中,既需要提取多尺度的局部特征,又需要捕捉体积整体的全局依赖关系,这是一个技术难点。
3. 多尺度特征的有效利用
- 在3D医学图像中,不同结构(如肿瘤、背景等)可能具有多种尺度和形状特性。现有方法在处理多尺度特征时,容易丢失细粒度信息,导致分割精度降低。
4. 数据标注不足的问题
- 现有的公开3D医学图像分割数据集(尤其是结直肠癌相关数据集)规模较小,限制了模型在实际场景中的泛化能力和性能评估的公平性。
5. 模块的通用性和效率
- 如何设计高效、通用的模块,既能适应医学图像分割的特定需求,又能在多种数据集(如结直肠癌CT扫描和脑部MRI)中表现出色。
通过提出SegMamba,论文试图在这些方面提供解决方案:
- 使用Mamba模型的长序列建模能力,降低全局建模的计算复杂度;
- 设计三向Mamba模块(ToM)和门控空间卷积模块(GSC),平衡全局与局部特征的建模;
- 开发新的数据集(CRC-500),提供大规模高质量标注以支持算法开发和评估。
详解框架
框架组成
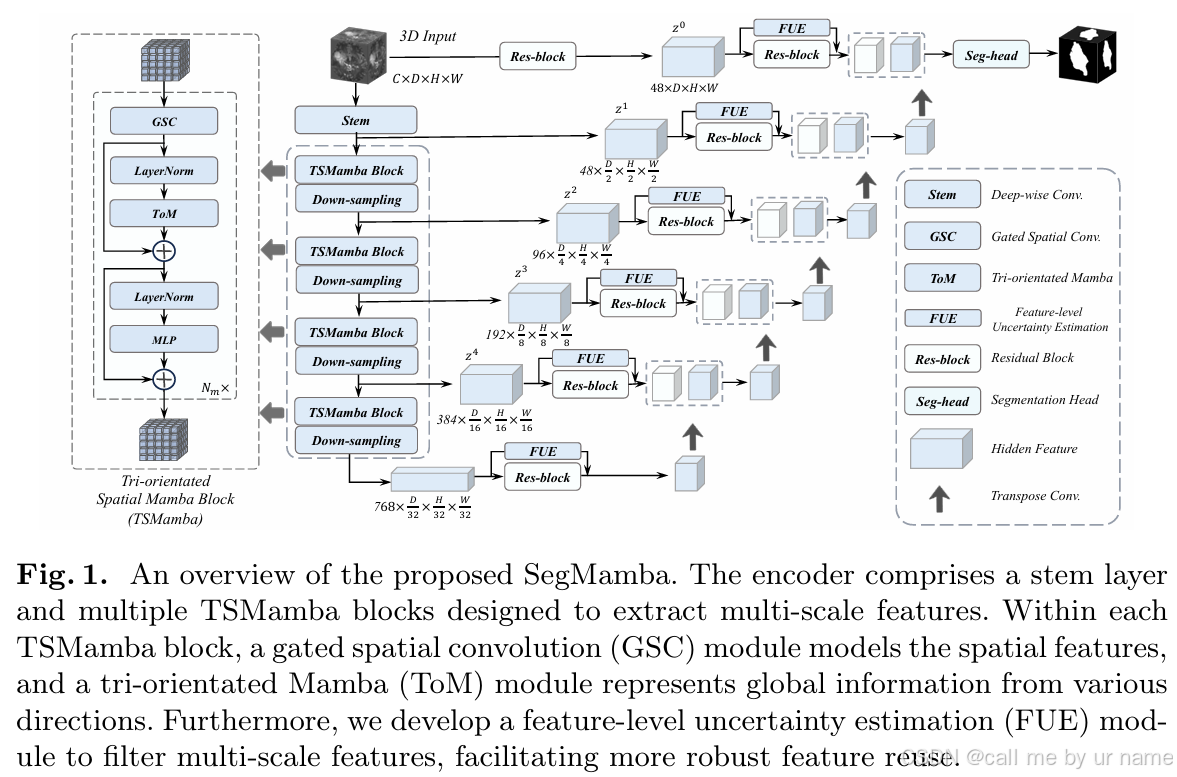
1. 编码器(Encoder)
编码器的主要任务是从输入的3D医学图像中提取多尺度特征。
-
Stem层:
- 深度卷积(7×7×7)用于初步特征提取,同时将图像下采样。
- 生成第一层特征图,分辨率为原输入的一半。
-
Tri-orientated Spatial Mamba (TSMamba)模块:
这是编码器的核心,用于全局和多尺度特征提取:- Gated Spatial Convolution (GSC):
- 在进入Mamba模块前,通过卷积捕获空间关系,提升局部特征建模。
- 公式: G S C ( z ) = z + C 3 × 3 × 3 ( C 3 × 3 × 3 ( z ) ⋅ C 1 × 1 × 1 ( z ) ) GSC(z) = z + C_{3\times3\times3}(C_{3\times3\times3}(z) \cdot C_{1\times1\times1}(z)) GSC(z)=z+C3×3×3(C3×3×3(z)⋅C1×1×1(z)),其中 C C C为卷积层。
- Tri-orientated Mamba (ToM):
- 执行三向全局建模(前向、反向、切片间)并融合特征。
- 公式: T o M ( z ) = M a m b a ( z f ) + M a m b a ( z r ) + M a m b a ( z s ) ToM(z) = Mamba(z_f) + Mamba(z_r) + Mamba(z_s) ToM(z)=Mamba(zf)+Mamba(zr)+Mamba(zs),其中 z f z_f zf, z r z_r zr, z s z_s zs分别为不同方向展开的序列。
- Gated Spatial Convolution (GSC):
-
多层次特征下采样:
- 每经过一个TSMamba模块,使用池化或步长卷积进一步下采样,获得更高语义但更低分辨率的特征。
2. 跳跃连接与特征增强
-
Feature-level Uncertainty Estimation (FUE)模块:
- 在跳跃连接中评估多尺度特征的可靠性,增强低不确定性特征:
-
计算通道均值: z ˉ i = σ ( 1 C ∑ c = 1 C z i c ) \bar{z}_i = \sigma\left(\frac{1}{C}\sum_{c=1}^{C}z_i^c\right) zˉi=σ(C1∑c=1Czic)
-
使用熵计算不确定性: u i = − z ˉ i log ( z ˉ i ) u_i = -\bar{z}_i \log(\bar{z}_i) ui=−zˉilog(zˉi)
-
增强特征: z i ′ = z i + z i ⋅ ( 1 − u i ) z_i' = z_i + z_i \cdot (1 - u_i) zi′=zi+zi⋅(1−ui)
-
- 在跳跃连接中评估多尺度特征的可靠性,增强低不确定性特征:
-
跳跃连接:
- 将不同尺度的特征从编码器传递到解码器,用于细粒度特征恢复。
3. 解码器(Decoder)
解码器的任务是逐步恢复图像分辨率,生成分割结果:
-
上采样模块:
- 使用反卷积(Transposed Convolution)或插值方法恢复图像分辨率。
- 在每一层与对应跳跃连接的特征融合。
-
Segmentation Head:
- 最后一层卷积生成与输入同分辨率的分割图,其中每个体素的值表示类别。
模型工作流程
-
输入:
- 接收一个三维医学图像体积(如CT或MRI),格式为 C × D × H × W C \times D \times H \times W C×D×H×W。 C C C: 输入图像的通道数(通常为1或多模态数据)。 D , H , W D, H, W D,H,W: 分别为深度、高度和宽度
-
编码器阶段:
- 输入图像通过Stem层,提取初始特征并下采样。
- 多层TSMamba模块依次提取多尺度特征:
- GSC模块增强空间关系。
- ToM模块进行全局建模。
- 每层特征通过下采样缩小分辨率并传递到跳跃连接。
-
跳跃连接与特征增强:
- 编码器生成的多尺度特征通过FUE模块进行不确定性增强,并与解码器的上采样特征融合。
-
解码器阶段:
- 逐层上采样恢复分辨率。
- 融合跳跃连接的特征,进一步提升细节信息。
-
输出:
- 最终生成一个三维分割图,大小与输入一致,标注每个体素的类别。
流程图(伪代码形式)
# 输入预处理
input_volume = preprocess(input_image)
# 编码器阶段
features = []
x = stem(input_volume)
for tsmamba_block in encoder_blocks:
x = tsmamba_block(x)
features.append(x)
x = downsample(x)
# 跳跃连接与特征增强
enhanced_features = []
for feature in features:
enhanced_features.append(FUE(feature))
# 解码器阶段
x = initial_decoder_feature
for i in range(len(decoder_blocks)):
x = upsample(x)
x = concatenate(x, enhanced_features[i])
x = decoder_blocks[i](x)
# 输出
output_segmentation = segmentation_head(x)
实验
1. 数据集与任务
(1) CRC-500(结直肠癌数据集)
- 简介:研究团队新构建的500例3D结直肠癌CT扫描数据集,每个体积由专家标注。
- 目标:对结直肠癌区域进行分割。
- 特点:
- 数据规模:每个体积的分辨率为512×512×(94到238)。
- 注重小肿瘤区域的精确分割。
(2) BraTS2023(脑肿瘤分割数据集)
- 简介:1251例3D脑部MRI体积,包含四种模态(T1、T1Gd、T2、T2-FLAIR)。
- 目标:分割三类肿瘤区域:
- WT(Whole Tumor)
- TC(Tumor Core)
- ET(Enhancing Tumor)
(3) AIIB2023(气道分割数据集)
- 简介:120例高分辨率CT扫描,用于肺部纤维化疾病的气道分割。
- 目标:分割完整的气道树,包括细小分支。
2. 实验设置
-
实现细节:
- 框架:基于PyTorch和Monai实现。
- 数据处理:随机裁剪尺寸为128×128×128,批量大小为2。
- 优化器:SGD,初始学习率1e-2,使用多项式学习率调度。
- 训练:1000个epoch。
- 数据增强:亮度、旋转、缩放、镜像和弹性变形。
-
硬件配置:
- GPU:4个NVIDIA A100显卡。
- 数据分配:70%用于训练,10%用于验证,20%用于测试。
3. 评价指标
-
分割精度:
- Dice相似系数(Dice):衡量预测分割与真实标注的重叠度(越高越好)。
- 95% Hausdorff距离(HD95):评估分割边界的最大误差(越低越好)。
- IoU(交并比)、检测长度比(DLR)、检测分支比(DBR):用于气道分割任务。
-
计算效率:
- 训练内存(TM):训练时模型的内存需求。
- 推理内存(IM):推理时的内存占用。
- 推理时间(IT):处理一个样本的耗时。
4. 实验结果
(1) 性能比较
与六种主流分割方法比较,包括:
- CNN-based:SegresNet、UX-Net、MedNeXt。
- Transformer-based:UNETR、SwinUNETR、SwinUNETR-V2。
结果:
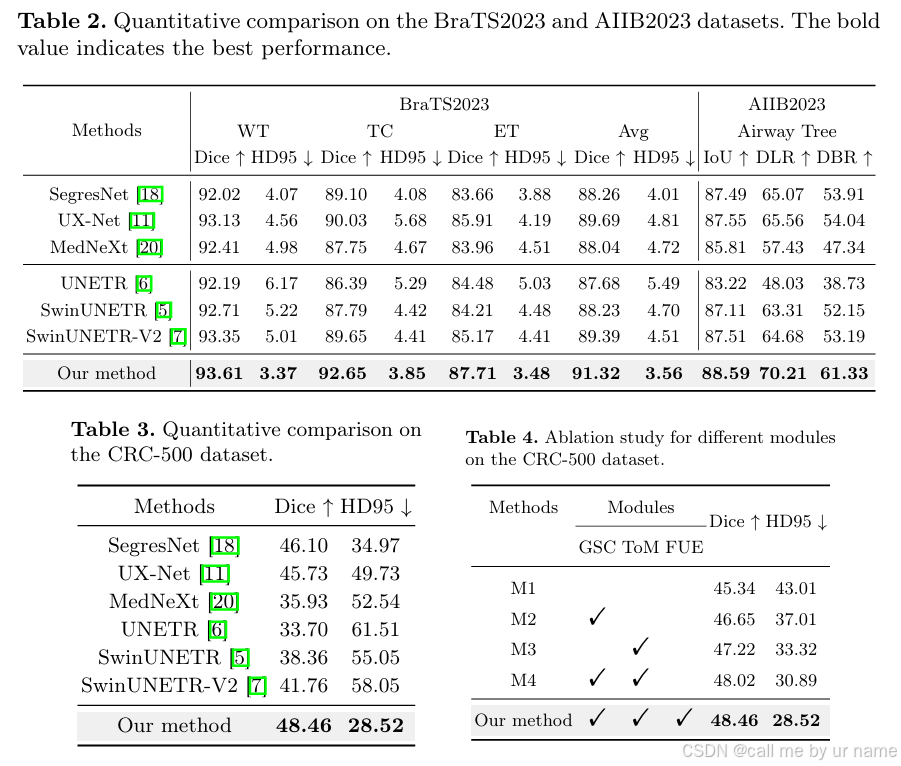
- 在BraTS2023、AIIB2023和CRC-500数据集上,SegMamba的Dice、HD95等指标均优于对比方法。
- 例如:
- 在BraTS2023数据集中,SegMamba的平均Dice达到91.32%,高于SwinUNETR-V2的89.39%。
- 在CRC-500数据集中,SegMamba的Dice为48.46%,远高于其他方法。
(2) 计算效率
- SegMamba在相同输入分辨率(128³,序列长度260k)的情况下,显著降低内存需求和推理时间:
- 训练内存:SegMamba为17.98 GB,优于SwinUNETR的34.00 GB。
- 推理时间:SegMamba为1.51 s/样本,快于其他全局建模方法。
(3) 视觉对比
- 在所有数据集的可视化结果中,SegMamba在分割边界细节上表现更加清晰,尤其在小肿瘤区域和复杂气道分割中具有更好的连续性。
5. 消融实验
(1) 模块有效性
通过逐步加入GSC、ToM、FUE模块,验证每个模块的贡献:
- 仅使用Mamba层(M1):
- Dice:45.34%,HD95:43.01。
- 加入GSC模块(M2):
- Dice提升至46.65%,HD95降低至37.01。
- 加入ToM模块(M3):
- Dice进一步提升至47.22%,HD95降低至33.32。
- 完整模型(M4,包含GSC、ToM和FUE模块):
- Dice最高为48.46%,HD95最低为28.52。
(2) 不同全局建模模块的比较
实验对比了SegMamba与其他核心模块(如大核卷积、Swin Transformer、自注意力)的性能:
- 自注意力由于计算负担过高导致“内存溢出(OOM)”。
- SegMamba在Dice、内存需求和推理时间上均表现优越。
代码

0_inference.pyThis script is used to test the model on a random input tensor1_rename_mri_data.pyThis script is used to rename the MRI data in the BraTS2023 dataset.2_preprocessing_mri.py对数据集进行预处理3_train.py训练4_predict.py预测5_compute_metrics.py计算指标


















 6736
6736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









