









目录

一、什么是 Workflow?
1.1 简述
简单来说,**Workflow(工作流)**是对一系列“处理步骤”的抽象。在实际应用中,尤其是需要大模型参与的多阶段任务中,我们通常不能一步到位完成所有事情,而是需要分步骤、逐步处理。
例如:“用自然语言查询数据库”这个看似简单的任务,其背后涉及多个步骤:
-
分析用户意图
-
检索相关数据库表
-
构造 SQL 查询
-
执行 SQL
-
把结果转成自然语言回复
每一步都依赖上一步的结果,并可能引入大模型的能力。而 LlamaIndex 的 Workflow 就是为了把这种多步骤流程清晰、高效地组织起来。
1.2 与传统代码区别
| 方式 | 特点 | 场景适用性 |
|---|---|---|
| 普通顺序代码 | 步骤写死、耦合紧密 | 简单线性任务 |
| Workflow | 每步独立、事件驱动、可插拔 | 多阶段、异步、需要大模型参与的复杂任务 |
二、Workflow 的核心思想:事件驱动
LlamaIndex 的工作流是 事件驱动的:
-
一个 Workflow 由多个 Step(步骤) 组成
-
每个 Step 监听并处理某类 Event(事件)
-
每个 Step 处理完后,会生成下一个 Event
-
Event 会传递到下一个 Step,直到产生
StopEvent,流程结束
可以类比为“事件接力赛”:一个事件由一个步骤处理,然后传给下一个人继续处理,直到终点。
在 LlamaIndex 中,Workflow 的三大核心:
-
Step:每一个处理模块(如生成 SQL)
-
Event:步骤之间传递的“消息”或状态
-
流程图结构:明确知道下一步是谁、该干嘛
举个类比:
就像是“工厂流水线”:
每个工人(Step)负责一件事
完工后把“零件”(Event)交给下一个人
最后组装成成品(StopEvent)
所以,可以总结为:
Workflow = 一种结构化、事件驱动的运行流程图,让程序每一步都清晰、可控、易维护。
如果你想让程序“更像人一样有逻辑地思考和行动”,Workflow 是非常实用的利器。
三、用图看懂一个示例 Workflow
我们来看一个典型的例子 —— “用自然语言查询数据库”的流程图:
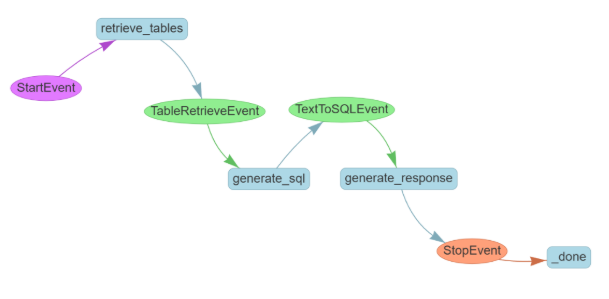
步骤拆解如下:
-
StartEvent
工作流开始,用户输入自然语言查询 -
retrieve_tables
-
Step:检索与问题相关的数据库表
-
产生事件:
TableRetrieveEvent
-
-
generate_sql
-
Step:调用大模型,根据表的结构生成 SQL
-
产生事件:
TextToSQLEvent
-
-
generate_response
-
Step:执行 SQL、生成查询结果的自然语言回复
-
产生事件:
StopEvent
-
-
StopEvent
工作流终点,返回_done
四、为什么要用 Workflow?
相比传统的“顺序代码”或“多函数调用”方式,使用 Workflow 有几个明显优势:
✅ 解耦合:每一步处理独立,便于维护和替换
✅ 可视化:流程可以像上面一样直观展示
✅ 灵活控制:可以动态插入、跳过或重试某些步骤
✅ 易于扩展:想新增“SQL 优化”或“用户上下文理解”等步骤?加个 Step 就行
| 功能 | 说明 |
|---|---|
| 结构化流程 | 把系统的执行逻辑分成清晰步骤,方便开发、调试和扩展。 |
| 解耦各模块 | Retriever、Reranker、LLM 可以单独替换,互不影响。 |
| 便于维护与优化 | 比如想提升检索质量,只需优化 retriever 相关步骤。 |
| 可视化执行路径 | 工作流图可以帮助你或他人快速理解系统运行原理。 |
总结一句话
Workflow 是组织复杂多步骤任务的利器,而 LlamaIndex 的事件驱动机制让你可以清晰、灵活地管理每一步处理。
特别适用于:智能问答、自然语言接口、数据分析自动化等多阶段任务场景。
六、构建问答系统的 Workflow 示例流程
从用户输入到返回回答,这个系统的 workflow 可以简要描述为:
-
用户输入问题
-
对话上下文压缩(多轮对话需要)
-
生成查询 Query
-
从 Qdrant 检索相似文段
-
用 Qwen rerank 模型重新排序片段
-
构造 Prompt
-
交给大语言模型生成回答
-
输出回答并等待下一轮提问
这些步骤构成了你的 RAG 多轮问答系统的 workflow。
七、在 AI 系统中,“workflow” 常见的例子
| 应用场景 | Workflow 举例 |
|---|---|
| 检索增强生成(RAG) | 用户提问 → 向量检索 → rerank → prompt 构造 → LLM回答 |
| 数据处理 | 文档上传 → 切分 → 嵌入 → 索引 → 检索 |
| Agent 调度 | 任务拆解 → 工具调用 → 汇总中间结果 → 最终回答 |
如果你使用的是像 LangChain、LlamaIndex、LangGraph,它们都支持构建、追踪或可视化 workflow。
八、实例应用场景
1. 文档预处理 Workflow(离线阶段)
documents = SimpleDirectoryReader("./data").load_data()
Settings.transformations = [SentenceSplitter(...)]
index = VectorStoreIndex.from_documents(documents, ...)
Workflow 步骤:
文档加载 → 文本切分 → 嵌入生成 → 存入 Qdrant 向量库
实际意义:
-
这是一条 数据索引工作流,确保文档结构化、分块、嵌入后可检索。
-
如果你换 Embedding 模型,只需要换掉其中一步。
2. 单轮/多轮问答 Workflow(在线阶段)
response = chat_engine.chat(question)
Workflow 步骤:
用户输入 → 多轮对话上下文压缩 → 生成 query →
向量检索(Qdrant)→ rerank(Qwen)→ 构造 prompt → LLM 回答
实际意义:
-
这是一条 RAG QA 工作流,自动串联了对话上下文压缩、查询生成、检索、rerank 与大模型生成。
-
如果你希望将 rerank 替换为另一个模型,只需替换那一阶段。
3. 文档增强检索(RAG Fusion)Workflow
fusion_retriever = QueryFusionRetriever(...)
Workflow 步骤:
生成多个查询 → 分别执行 top-k 检索 → 合并结果 → 排序
实际意义:
-
你实际用了一个 mini-workflow 来执行 多查询融合(Query Fusion),提高检索鲁棒性。
-
可独立替换为其他策略,如 HyDE 检索或 CoT-RAG。
4. 模块级组合式 Workflow
以下使用的是 LlamaIndex,每个组件(retriever、reranker、synthesizer)本质上都是一个 可组合的 Workflow 步骤,组合它们的方式如下:
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever,
node_postprocessors=[reranker],
response_synthesizer=get_response_synthesizer(...)
)
这个就是“Workflow”的组装方式之一(Composable Retrieval Pipeline)。
九、构建问答系统流程示例
| 节点 | 描述 |
|---|---|
| 用户输入 | 用户提出自然语言问题 |
| Condense Chat History | 多轮对话中,压缩历史上下文为精简 query |
| Query Fusion Retriever | 生成多个子查询,提高召回质量 |
| Qdrant 向量检索 | 对每个子查询进行向量召回,top-k |
| rerank(Qwen) | 利用 Qwen 模型对召回结果重排序 |
| 构造 Prompt | 将上下文 + 问题组合为模型输入 |
| DashScope LLM | 使用大模型生成回答 |
| 返回响应 | 展示回答并等待下一轮提问 |

十、衍生应用:扩展场景
| 扩展 | Workflow 变化 |
|---|---|
| 加入语音问答 | 语音识别 → 文本解析 → 问答工作流 → 语音合成 |
| 支持搜索+向量混合检索 | 结构化检索 → 向量检索 → rerank → 合并生成 |
| Agent 多工具系统 | 任务识别 → 工具规划 → 工具调用 → 汇总生成回答 |
总结一句话
项目就是由多个 workflow 构成的系统,不同模块执行不同“步骤”,这些组合起来让系统完成检索、理解、生成等复杂任务。Workflow 的作用就是 抽象流程、支持模块替换、简化逻辑编排。

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









