










文章来源于我的个人公众号:KAU的云实验台,主要更新智能优化算法的原理、应用、改进
由于在工程实践和科学研究中,很多问题都是由多个相互影响、相互冲突的目标构成,而进化算法在解决这些多目标优化问题上具有独特优势,因此获得了广泛的研究。
其中,NSGA-II是较为经典的多目标进化算法,其具有鲁棒性好、搜索性能高的特点;而MOPSO算法作为新型的进化范例,具有收敛速度快、收敛精度高、搜索效率高的特点。两种算法具有不同的开发和探索过程,因此为充分利用两种经典算法的特点,本文提出一种双种群协同进化的混合改进NSGA-II和MOPSO的多目标算法
00 文章目录
1 MOPSO/NSGA-II算法原理
2 双种群协同进化的混合NSGA-II和MOPSO的多目标算法
3 代码目录
4 算法性能
5 源码获取
01 MOPSO/NSGA-II算法原理
这两个算法的原理及其代码实现在KAU前面的文章中以作介绍,这里不再赘述
02 双种群协同进化的混合改进NSGA-II和MOPSO多目标算法
NSGA-II与MOPSO的信息共享机制不同,NSGA-II通过遗传算子传递信息;MOPSO通过全局最优粒子引导其他粒子。这使得两个算法必然存在各自的优势,即NSGA-II搜索能力强而MOPSO收敛快。因此本文将两种算法结合以充分利用其各自的优势,并分别进行改进以进一步提升性能,具体改进策略如下:
2.1 双种群协同进化策略
双种群协同进化策略在NSGA-II的非支配排序的基础上进行,将经过初始化、非支配排序的种群分为两半。Pareto等级好的上半部分为精英种群,利用NSGA-II搜索能力强的特点探索区域中的其他Pareto解集,找出非支配解;Pareto等级较差的下半部分则采用MOPSO算法对精英种群进行学习,同时为避免MOPSO算法引起的早熟收敛,本文将通过轮盘赌选取精英种群中的个体作为MOPSO的“社会部分”学习样本。
2.2 改进NSGA-II —— 基于拥挤度的动态交叉与变异概率
NSGA-II中的交叉与变异操作是其种群个体探索空间的重要途径,但传统的交叉与变异操作具有盲目性,为合理的把握种群的交叉与变异范围,本文采用一种基于种群拥挤度和进化迭代数的动态交叉与变异概率,增加种群收敛性。具体改进如下:
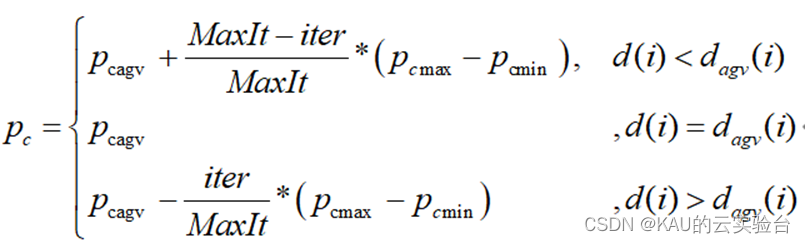

式中,pcagv、pcmax、pcmin、pmagv、pmmax、pmmin分别是交叉率pc和变异率pm的平均值、最大值和最小值;iter为当前迭代次数,MaxIt为最大迭代次数;d(i)为第i个个体的拥挤度,dagv(i)为第i个个体所在前沿的平均拥挤度。
公式根据个体拥挤度与种群平均拥挤度之间的关系,确定交叉和变异概率的进化方向,同时引入迭代因子,实现种群的自适应进化,加快收敛速度。
2.3 改进MOPSO —— 非线性学习因子
基本的粒子群算法采用固定的学习因子,这不利于全局搜索最优解。因此本文对其进行调整,在算法初期, 迭代次数小, 则c1较大, c2 较小, 便于局部寻优,增加种群多样性;算法后期, 迭代次数大, 则c1较小, c2 较大, 利于全局搜寻,加快收敛。改进后的迭代公式如下:
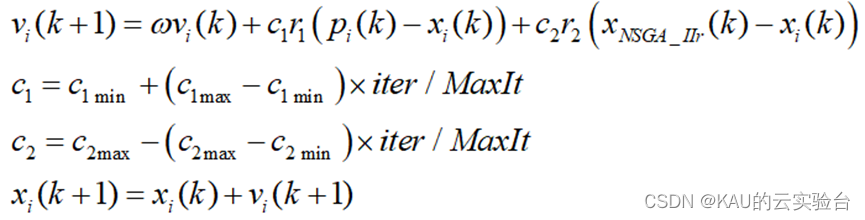
式中,w为固定的惯性权重;c1max、c1min、c2max、c2min分别为学习因子c1和c2的最大值和最小值;iter为当前迭代次数,MaxIt为最大迭代次数;xNSGA_IIr为随机从NSGA-II种群中选择的个体
2.4 基于世代距离GD的自适应变异策略[2]
对经过NSGA-II的遗传操作以及MOPSO的引导寻优后得到的个体进行非支配排序,其中非支配排序为1的个体包含当前最优的进化信息,然而,无论是NSGA-II还是MOPSO都存在容易陷入局部最优的问题,这可能使得若干代后出现大量相似的个体,使得算法无法找到最优前沿。因此本文对这部分解进行变异操作,提高种群跳出局部最优的能力。同时,非支配排序为1的群体变化的动态过程同样值得关注,本文采用世代距离衡量这种变化,并据此对变异规模进行动态调整。
变异方面,这里采用多项式变异[1],随机选择个体中的一维进行变异:
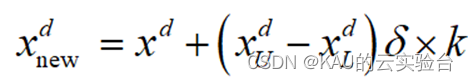
式中,xdU和xdL为个体第d维的上界和下界,𝛿为扰动项,k为扰动比例系数。扰动项𝛿由下式计算:
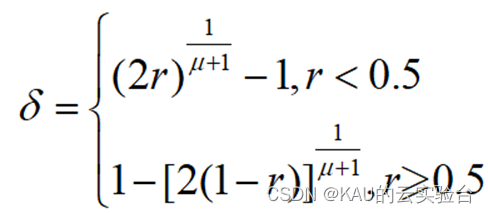
其中,r为(0,1)之间的随机数,u为变异分布指数。
世代距离GD可以表征待评价解集中的解与真实Pareto解之间的欧氏距离,但在本应用中,我们需要衡量非支配排序为1的群体的动态变化过程,因此取当前代的种群与前一代之间的世代距离记作GD*,相邻两代解集的GD差值记作ΔGD,则有
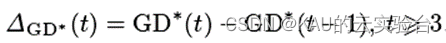
ΔGD可以表征算法的收敛速度,当ΔGD>0时,则算法收敛速度快,应减小变异规模,提升算法效率;而当ΔGD*<0时,则需增大变异规模,提升算法收敛性与多样性。变异规模的调整如下:
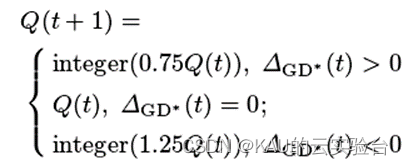
其中,integer()为取整,Q(t)为第t代的变异规模,且当t=1,2,3时,Q(t)等于当前的非支配排序为1的个体数量。
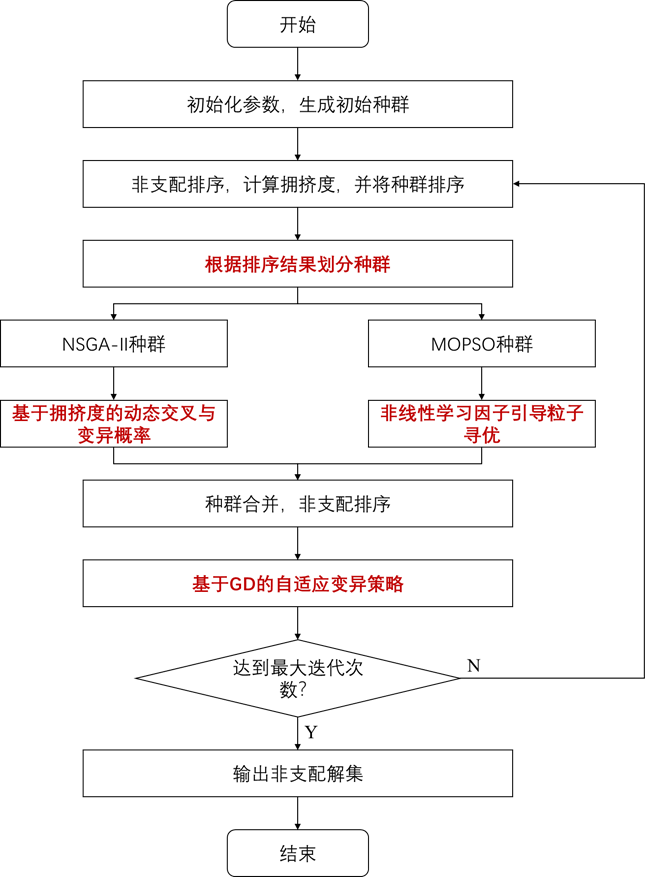
2.5 算法流程
双种群协同进化的混合改进NSGA-II和MOPSO的多目标算法流程图如下:
03 代码目录
MATLAB编写,包含双种群协同进化的NSGA-II与MOPSO混合算法、NSGA-II、MOPSO三种算法对比。代码逻辑清晰简单,KAU已将代码进行详细注释,方便学习。

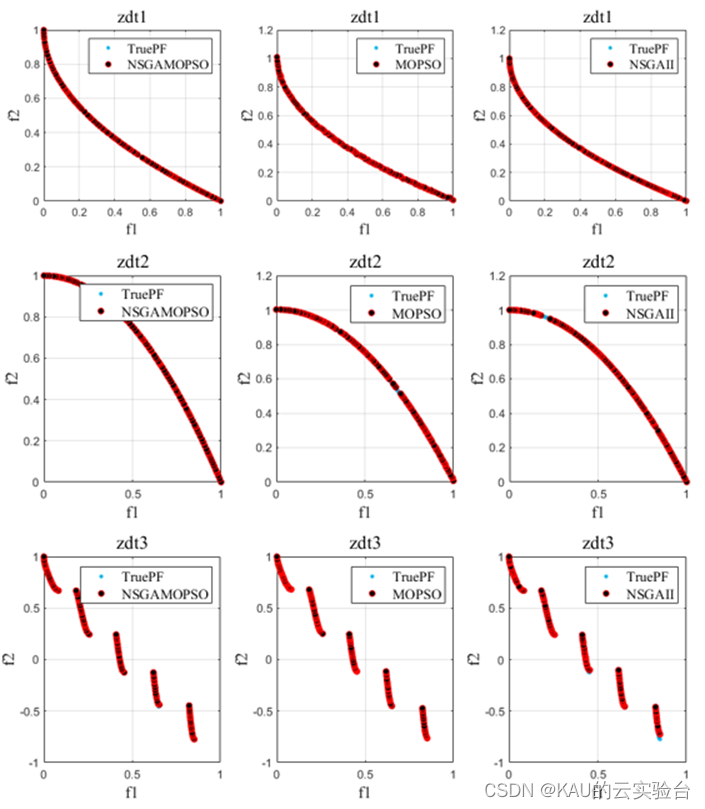
04 算法性能
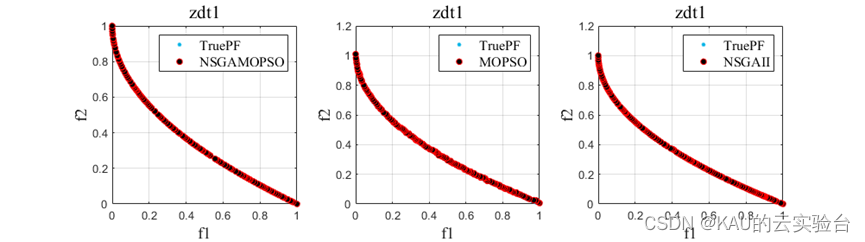
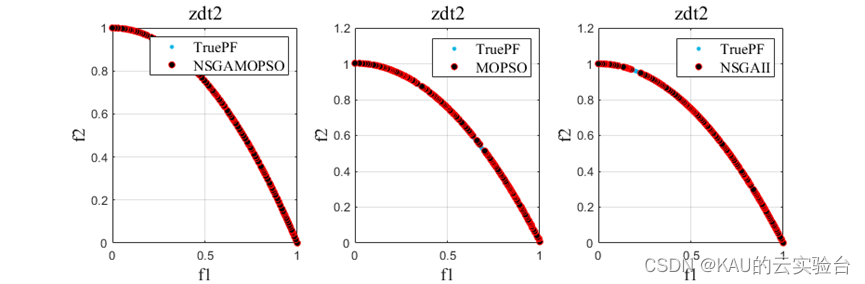
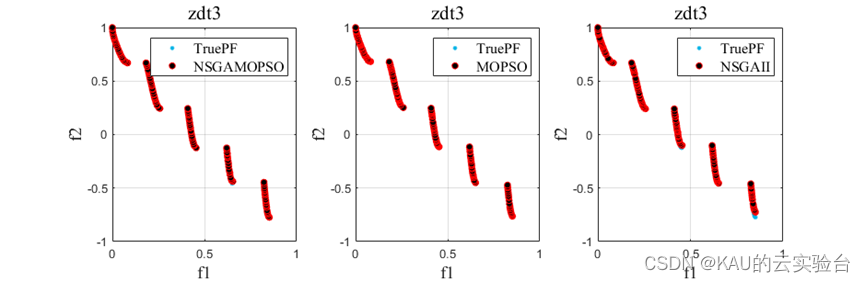
以ZDT1-6问题为例,运行程序,结果如下:
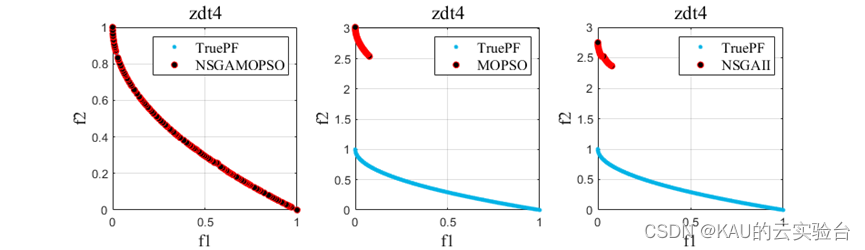
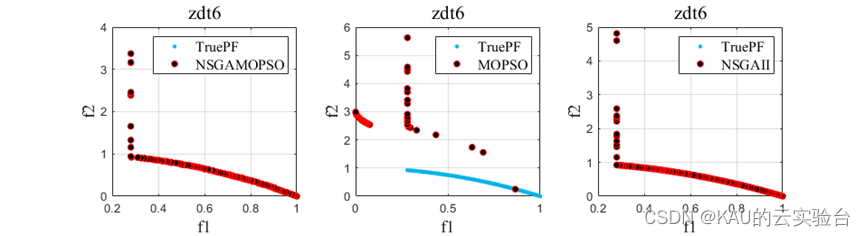
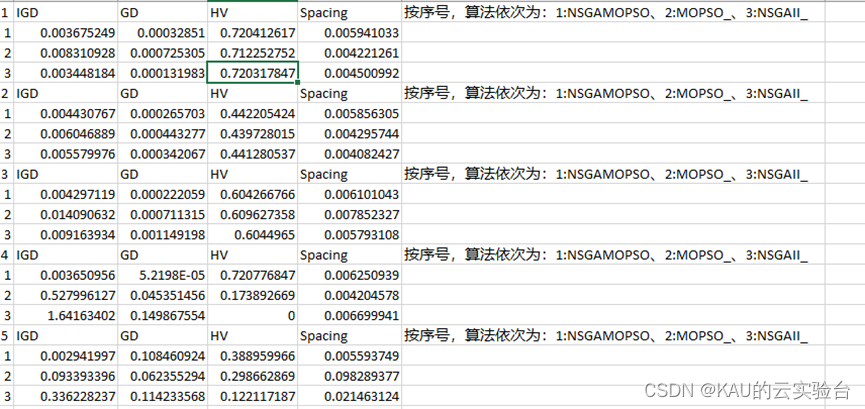
05 源码获取
公众号(KAU的云实验台)后台回复 INM
或
直接私信我关键词 INM
参考文献
[1] Deb K, Pratap A, Agarwal S, et al. A fast and elitist multi-objective genetic algorithm: NSGA-II[J]. IEEE Trans on Evolutionary Computation, 2002, 6(2): 182-197.
[2] 杨景明,马明明,车海军,等.多目标自适应混沌粒子群优化算法[J].控制与决策, 2015, 30(12):7.DOI:10.13195/j.kzyjc.2014.1869.
另:如果有伙伴有待解决的优化问题(各种领域都可),可以发我,我会选择性的更新利用优化算法解决这些问题的文章。
如果这篇文章对你有帮助或启发,可以点击右下角的赞/在看 (ง•̀_•́)ง(不点也行)

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









