







有时我们想在层的输出端放置一个阈值函数。这可能出于多种原因。其中之一是我们想将激活总结为二进制值。这种激活的二值化在自编码器中很有用。
然而,阈值化在反向传播过程中会带来问题:阈值函数的导数为零。这种梯度的缺乏导致我们的网络无法学习任何东西。为了解决这个问题,我们可以使用直通估计器 (STE:Straight Through Estimator)。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、什么是直通估计器?
假设我们想使用以下函数将层的激活二值化:
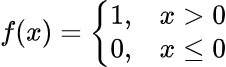
此函数将为每个大于 0 的值返回 1,否则将返回 0。
如前所述,此函数的问题在于其梯度为零。为了解决这个问题,我们将在反向传递中使用直通估计器。
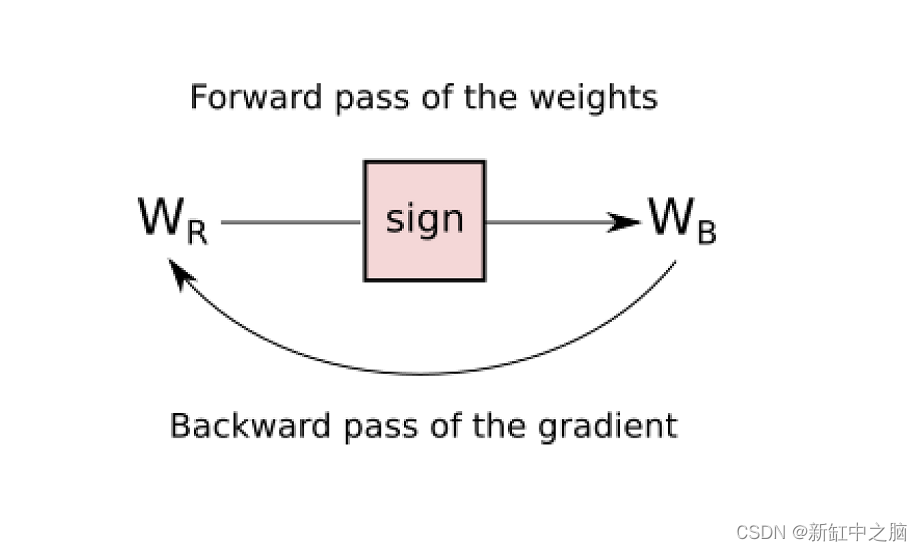
直通估计器顾名思义就是它估计函数的梯度。具体来说,它忽略阈值函数的导数,并将传入的梯度传递,就好像该函数是恒等函数一样。下图有助于更好地解释它:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









