









FlexiDepth:动态层跳跃的创新之道
在大型语言模型(LLM)的优化领域,层剪枝与跳跃技术一直是研究的热点,旨在减少计算开销的同时保持模型性能。论文《Adaptive Layer-skipping in Pre-trained LLMs》提出了一种名为 FlexiDepth 的方法,通过动态调整Transformer层的使用数量,为预训练LLM提供了高效且灵活的层跳跃方案。以下从研究者的视角,剖析FlexiDepth的创新点及其对层剪枝领域的启发。
Paper:https://arxiv.org/pdf/2503.23798v2
FlexiDepth的核心设计
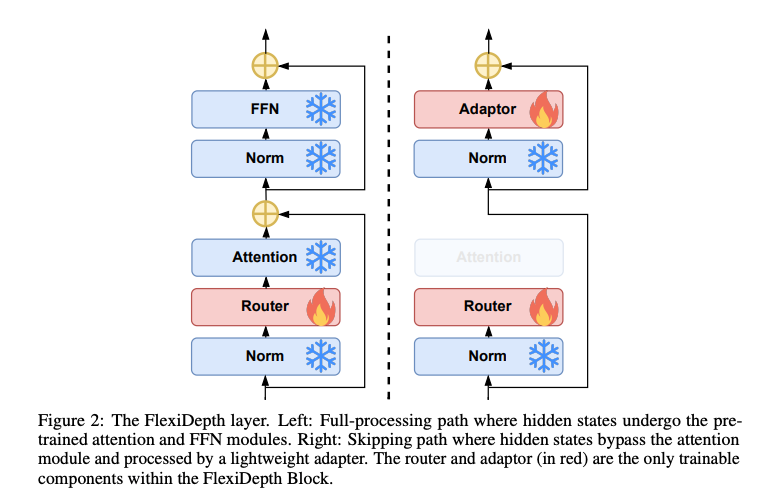
与传统的层跳跃方法(如LayerSkip、ShortGPT、LaCo等)不同,FlexiDepth无需从头训练LLM,而是通过在预训练模型中插入轻量级模块实现自适应层跳跃。其核心组件包括:
-
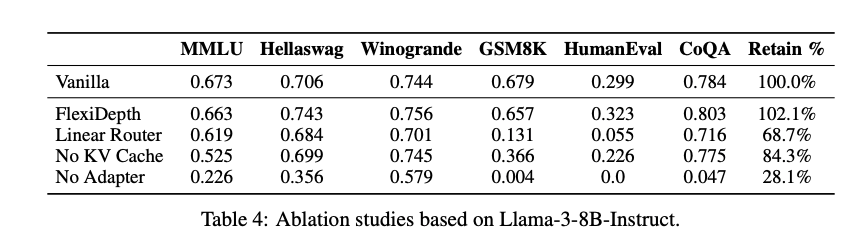
轻量级路由器(Router):在每个Transformer层,FlexiDepth引入一个基于瓶颈MLP的路由器,计算隐藏状态的门控分数(gating score),决定是否跳过当前层。相比MoD等方法使用的简单线性路由器,瓶颈MLP能够更细致地捕捉隐藏状态的特征,提升路由决策的精准性。消融实验表明,替换为线性路由器后,性能在数学推理任务(如GSM8K)上显著下降(从0.657降至0.131),凸显了该设计的必要性。
-
适配器(Adapter):为解决层跳跃导致的表示空间不一致问题,FlexiDepth在跳跃路径中引入轻量级适配器,结构与FFN相似但中间维度压缩16倍。适配器将跳跃的隐藏状态映射到与完整处理路径一致的表示空间,确保模型输出的一致性。消融实验显示,若移除适配器,性能仅保留28.1%,证明其在维持表示连贯性中的关键作用。
-
KV缓存完整性:为支持自回归生成,FlexiDepth为所有隐藏状态(包括跳跃的)计算键值(KV)缓存,避免后续token无法访问跳跃token的上下文信息。实验表明,移除KV缓存会导致性能下降至84.3%,强调了此设计的不可或缺。
- 层跳跃损失函数:FlexiDepth引入平方和形式的跳跃损失(skip loss),与语言建模损失联合优化,平衡计算效率与生成质量。平方损失对使用更多层的token施加更大惩罚,稳定训练并避免极端跳跃模式。
实验结果与洞见
FlexiDepth在Llama-3-8B-Instruct模型上进行了广泛测试,覆盖单token生成(MMLU、HellaSwag、Winogrande)和多token生成(GSM8K、HumanEval、CoQA)任务。关键结果包括:
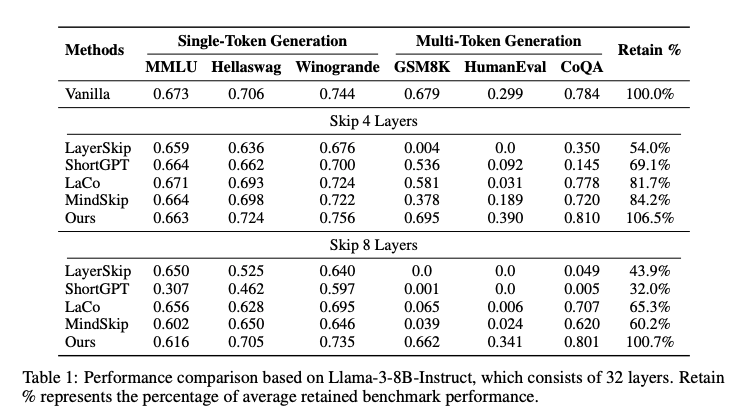
- 性能保留:在跳跃8层(总32层)的情况下,FlexiDepth保留了100.7%的基准性能,显著优于LayerSkip(43.9%)、ShortGPT(32.0%)、LaCo(65.3%)和MindSkip(60.2%)。尤其在需要长程推理的GSM8K和HumanEval任务中,基线方法几乎失效,而FlexiDepth保持了0.662和0.341的得分。
-
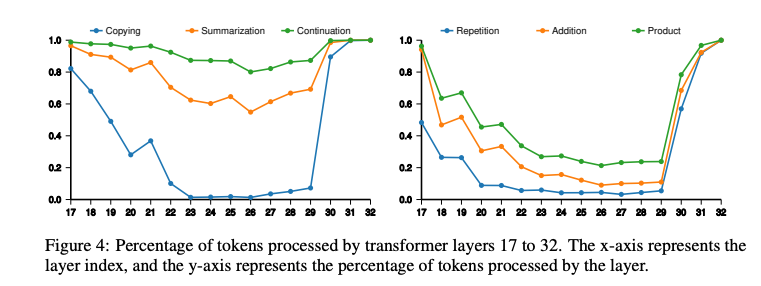
任务自适应性:通过“DepthMap”可视化,FlexiDepth揭示了不同token的计算需求差异。例如,数学任务中,等式右侧的计算结果token需要更多层,而左侧的输入复制token需要较少层。语言任务中,摘要(summarization,28.65层)和续写(continuation,30.27层)比复制(copying,21.95层)需要更多层,反映了任务复杂性与层分配的直观对应。
-
层使用模式:FlexiDepth的层使用呈现“碗状”分布,早期和末期层使用率高,中间层使用率低,表明早期层负责输入解析,末期层聚焦输出解码,而中间层在简单任务中常被跳跃。这一发现为理解Transformer层的功能分工提供了新视角。
与现有方法的对比
与LayerSkip、ShortGPT等基于统计信息或固定跳跃的策略相比,FlexiDepth的动态路由和适配器设计使其在多token任务中表现更稳健。相比MoD等需从头训练的方案,FlexiDepth仅微调路由器和适配器,保留预训练参数,降低了适配成本。FlexiExit扩展进一步允许token在中间层提前退出,平均跳跃1.61至4.68层,依然保持102.1%的性能,展示了其灵活性。
局限性与未来方向
尽管FlexiDepth在理论上降低了FLOPs,但当前实现因控制流管理和不规则内存访问,在GPU上未显著提升吞吐量。未来可结合token分组、专家分片等硬件优化技术,进一步释放其效率潜力。此外,FlexiDepth在更大模型(如DeepSeek-V3)上的应用潜力值得探索,尤其是在MoE架构中减少跨服务器通信开销。
开放资源与研究启发
FlexiDepth开源了其模型和层分配数据集,为研究者提供了分析层使用模式的宝贵资源。数据集涵盖语言理解和数学推理任务,揭示了任务复杂性与层需求的关联,为进一步研究Transformer层功能和优化提供了数据支持。
总结
FlexiDepth通过动态层跳跃、轻量级路由器和适配器,为预训练LLM提供了高效的优化方案。其在性能保留、任务自适应性和层使用洞见方面的突破,使其在层剪枝领域独树一帜。对于研究大模型优化的学者,FlexiDepth不仅提供了一个实用的技术框架,还通过DepthMap和数据集为探索Transformer层功能和任务复杂性关联开辟了新方向。
KV cache在这里的解释
什么是KV缓存及其在Transformer中的作用?
在Transformer的解码器(decoder-only模型,如Llama-3-8B-Instruct)中,自回归生成(autoregressive generation)是逐个生成token的过程。每个token的生成需要通过注意力机制(attention) 来参考之前的上下文。注意力机制依赖于查询(Query, Q)、键(Key, K)和值(Value, V) 向量:
- Q:当前token的查询向量,用于与其他token的键向量计算注意力分数。
- K:所有token的键向量,用于表示上下文token的信息。
- V:所有token的值向量,注意力分数加权后用于生成当前token的表示。
在32层Transformer模型中,每一层都会计算Q、K、V向量,并通过注意力机制计算当前token与所有先前token的注意力分数(attention score),以捕捉上下文依赖关系。计算公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q K T QK^T QKT 就是token之间的注意力分数矩阵,用于决定每个token对当前输出的贡献。
KV缓存的作用:
- 在自回归生成中,每个token生成时都需要重新计算所有先前token的K和V向量。如果不缓存,每次生成新token时都需要从头计算所有层的K和V,计算量巨大。
- KV缓存将每一层的K和V向量存储下来,只需在生成新token时计算当前token的Q向量,并与缓存的K、V进行注意力计算,大幅降低计算成本。
因此,每一层的注意力模块都需要token之间的注意力分数,而KV缓存确保这些分数可以基于存储的K和V高效计算。
如果没有KV缓存会怎样?
如果不使用KV缓存,每次生成新token时,模型需要重新计算所有先前token在每一层的K和V向量。这会导致以下问题:
- 计算效率低下:对于长序列,重新计算K和V的开销会随序列长度线性增长,导致推理速度显著变慢。
- 上下文信息丢失(在FlexiDepth场景下):在FlexiDepth中,如果某些token跳跃了某层的注意力模块且不生成对应的K和V向量,后续token将无法通过注意力机制访问这些跳跃token的上下文信息。这会导致生成结果失去连贯性,甚至出现错误。
在FlexiDepth的论文中,消融实验表明,如果不计算跳跃层的KV缓存,模型性能下降至87.4%(相比FlexiDepth的100.7%)。这是因为跳跃层的token缺失了K和V,导致后续token无法正确“看到”这些token的上下文,破坏了自回归生成的完整性。
通过例子解释KV缓存的作用和缺失的影响
假设我们用一个4层Transformer模型(为简化起见,实际Llama-3-8B有32层)生成句子:“The cat is on the mat”。我们逐步生成6个token:The, cat, is, on, the, mat。
场景1:正常使用KV缓存
-
生成token
The:- 在第1层,模型处理输入(可能是提示词),计算所有输入token的Q、K、V向量,生成
The的表示。 - 存储第1层的K1、V1(对应
The)到KV缓存。 - 重复此过程直到第4层,存储每层的K1、V1。
- 在第1层,模型处理输入(可能是提示词),计算所有输入token的Q、K、V向量,生成
-
生成token
cat:- 输入包含
The和当前tokencat。 - 在第1层,模型从KV缓存中取出
The的K1、V1,计算cat的Q1,执行注意力计算:
Attention ( Q cat , [ K The , K cat ] , [ V The , V cat ] ) \text{Attention}(Q_{\text{cat}}, [K_{\text{The}}, K_{\text{cat}}], [V_{\text{The}}, V_{\text{cat}}]) Attention(Qcat,[KThe,Kcat],[VThe,Vcat]) - 存储
cat的K1、V1到第1层缓存,重复此过程直到第4层。
- 输入包含
-
后续token(
is,on,the,mat)类似处理,每一层都利用KV缓存中的先前token的K和V,高效计算注意力分数。
结果:生成的句子连贯,因为每个token都能通过注意力机制访问所有先前token的上下文信息。
场景2:FlexiDepth中跳跃层但保留KV缓存
假设在FlexiDepth中,生成cat时跳跃了第2层的注意力模块:
- 第1层:正常计算
cat的Q1、K1、V1,存储K1、V1到KV缓存。 - 第2层(跳跃):
- 不计算
cat的Q2(避免注意力计算),但仍计算K2、V2并存储到KV缓存。 - 使用适配器处理跳跃的隐藏状态,保持表示一致性。
- 不计算
- 第3、4层:正常处理,KV缓存包含所有层的K、V。
当生成下一个token is时:
- 在第2层,
is的Q2可以与KV缓存中的The和cat的K2、V2计算注意力分数,保持上下文完整。
结果:即使跳跃了第2层的注意力模块,cat的K2、V2仍存在,后续token仍能正确参考上下文,生成连贯的句子。
场景3:FlexiDepth中跳跃层且不保留KV缓存
假设生成cat时跳跃第2层且不计算K2、V2:
- 第1层:正常计算,存储K1、V1。
- 第2层(跳跃):
- 不计算Q2、K2、V2,KV缓存中缺少
cat在第2层的K2、V2。 - 使用适配器处理跳跃的隐藏状态。
- 不计算Q2、K2、V2,KV缓存中缺少
- 第3、4层:正常处理。
当生成is时:
- 在第2层,
is的Q2只能与The的K2、V2计算注意力分数,cat的K2、V2缺失,导致is无法“看到”cat的上下文信息。 - 这可能导致
is的生成偏离正确语义,例如模型可能生成不相关的词(如“dog”),破坏句子连贯性。
结果:生成的句子可能变为“The cat dog on the mat”或更糟,因为cat在第2层的上下文信息丢失,后续token无法正确依赖它。
FlexiDepth为何保留KV缓存?
FlexiDepth的目标是通过跳跃某些层的注意力模块和FFN来减少计算量,但仍需保持自回归生成的上下文完整性。如果不计算跳跃层的K和V,后续token将失去对跳跃token的注意力访问,导致生成质量下降。论文中的消融实验(表4)证实了这一点:移除KV缓存后,性能从100.7%降至84.3%,尤其在需要长程依赖的任务(如GSM8K)中影响显著。
通过保留KV缓存,FlexiDepth确保即使跳跃层的token也能为后续token提供完整的上下文信息,同时通过适配器维持表示一致性。这种设计在减少FLOPs的同时,最大程度保留了模型性能。
总结
- 每一层的注意力模块都需要token之间的注意力分数,以捕捉上下文依赖关系。
- KV缓存通过存储K和V向量,避免重复计算,提升效率并保持上下文完整。
- 在FlexiDepth中,即使跳跃层的注意力模块,也必须计算K和V并存储到KV缓存,否则后续token会丢失上下文,导致生成质量下降。
- 通过上述例子可以看到,KV缓存的缺失会导致句子连贯性丧失,尤其在需要长程依赖的任务中影响更大。
后记
2025年5月21日于上海,在grok 3大模型辅助下完成。

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









