







David Silver《Reinforcement Learning》课程解读—— Lecture 1: Introduction to Reinforcement Learning
前段时间学习了UCL讲师、AlphaGo项目的主程序员David Silver的课程Reinforcement Learning,手写了30多页学习笔记,可以说学得很浅,整个知识网络掌握得不够有连贯性,为了将整个课程的体系做一个梳理,写下此篇博文。课程ppt和视频资料在网上很容易搜索,此处不再提供。
课程目录:
- Lecture 1: Introduction to Reinforcement Learning
- Lecture 2: Markov Decision Processes
- Lecture 3: Planning by Programming
- Lecture 4: Model-Free Prediction
- Lecture 5: Model-Free Control
- Lecture 6: Value Function Approximation
- Lecture 7: Policy Gradient
- Lecture 8: Integrating Learning and Planning
- Lecture 9: Exploration and Exploitation
- Lecture 10: Calssic Games
Lecture 1: Introduction to Reinforcement Learning
1. About Reinforcement Learning
- 不需要监督,有一个reward signal。
- 强化学习中没有监督学习中的有标记样本,即没有人直接告诉机器在什么状态下该做什么动作,只有等到最终结果揭晓,才能通过“反思”之前的动作是否正确来进行学习,因此强化学习可以看作具有“延迟标记信息”的监督学习问题。
- 智能体的行为会影响它随后收到的反馈。
- 学习的目的就是要找到能使得长期累积奖赏最大化的策略。
2. The Reinforcement Learning Problem
Rewards
- Rt是一个标量反馈信号。
- 反映了智能体在时刻t行为得好坏。
- 智能体的目的即最大化累积回报。
- RL式基于回报假设:所有目标都可以表示为最大化期望累计回报。
Sequential Decision Making 连续决策
- 目的:挑选动作行为来最大化将来的累计回报。
- 牺牲立即回报来获得更多的长期回报。
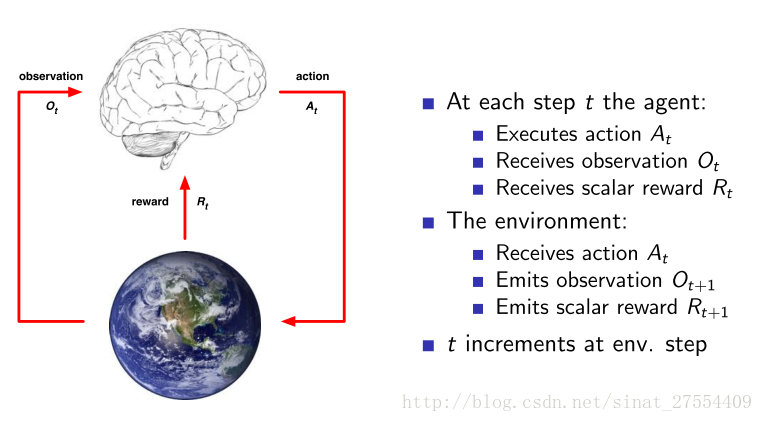
Environment 环境
如图所示,每一步,对于agent都有:
- 计算动作 At
- 接收观察 Ot
- 接收常量回报 Rt
对于environment都有:
- 接收行为 At
- 发出观察 Ot
- 发出常量回报 Rt
State 状态
history与state不同,前者式一系列观察值/行为/回报所构成的集合,后者是只用于决定下一刻发生事件的信息。
环境状态
- Set 用于挑选下一刻观察值和回值的信息,通常对智能体不可见。
智能体状态
- Sat 是智能体用于挑选下一个行为的所有信息。
Markov状态
- St 是Markov当且仅当 P[St+1|St]=P[St+1|S1,S2,S3,⋅⋅⋅,St] ,即随机过程的某事件只取决于它的上一事件,与初始状态无关。
Fully Obserable Environment
- 智能体直接观察环境状态: Ot=Sat=Set
- 这就是一个MDP
Partially Obserable Environment
- Agent间接观察环境: Ot≠Sat
- 这是一个Partially Observable Markov Decision Process POMDP
RL Agent
组成
- policy:智能体的行为选择函数
- value:评价每个状态/动作
- model:环境的代表
Policy
- 即agent的表现,是从状态到动作的一个对应关系
- 确定性策略: a=π(s) ,即根据这个策略,就能知道在状态s下要执行的动作 a=π(s) .
- 随机策略: π(a|s)=P[At=a|St=s] ,表示状态s下选择动作a的概率,因此有 ∑aπ(a|s)=1 .
Value Function
- 用于评价状态的好坏,是对将来回报的一个估计。
- Model
- 预测环境接下来要作出的反应,
P
预测下一刻状态,
R 预测下一刻的立即回报。
- 预测环境接下来要作出的反应,
P
预测下一刻状态,
RL Agent 分类
Value Based
- No Policy
- Value Function
Policy Based
- policy
- No Value Function
- Actor Critic
- Policy
- Value Function
Model Free
- Policy and/or Value Function
- No Model
Model Based
- Policy and/or Value Function
- Model















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









