







自从VIT横空出世以来,Transformer在CV界掀起了一场革新,各个上下游任务都得到了长足的进步,今天就带大家盘点一下基于Transformer的端到端目标检测算法!
一、原始Tranformer检测器
1、DETR(ECCV2020)
开山之作!DETR
论文链接:https://arxiv.org/abs/2005.12872
代码链接:https://github.com/facebookresearch/detr
论文提出了一种将目标检测视为直接集预测问题的新方法。DETR简化了检测流程,有效地消除了对许多人工设计组件的需求,如NMS或anchor生成。新框架的主要组成部分,称为DEtection TRansformer或DETR,是一种基于集合的全局损失,通过二分匹配强制进行一对一预测,以及一种transformer encoder-decoder架构。
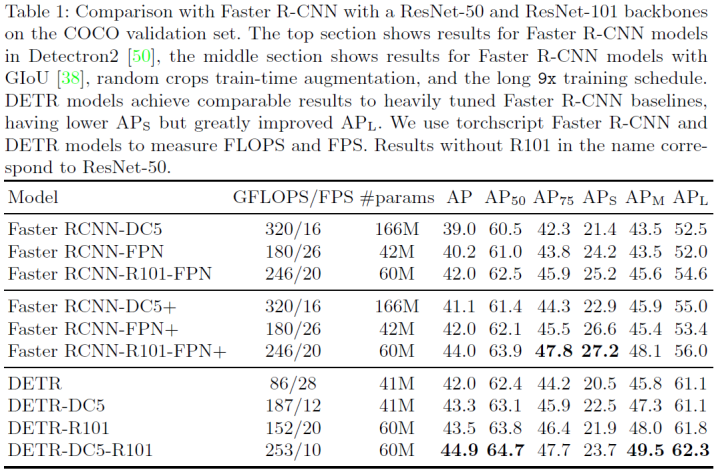
给定一组固定的学习目标查询,DETR分析了目标和全局图像上下文之间的关系,以直接并行输出最后一组预测。与许多其他检测器不同,新模型概念简单,不需要专门的库。
DETR在具有挑战性的COCO目标检测数据集上展示了与成熟且高度优化的Faster RCNN基线相当的准确性和运行时间。此外,DETR可以很容易地推广到以统一的方式输出全景分割。
DETR的网络结构如下图所示,从图中可以看出DETR由四个主要模块组成:backbone,编码器,解码器以及预测头。主干网络是经典的CNN,输出降采样32倍的feature。
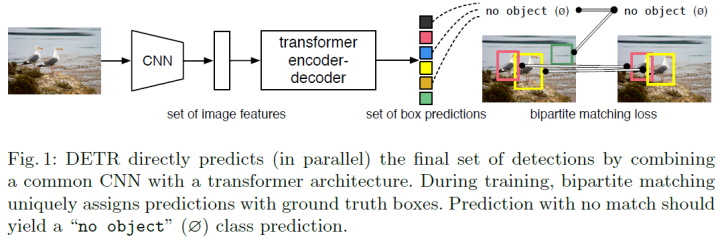
实验结果如下所示,性能上倒是还不错,就是训练太慢了,300 epochs。
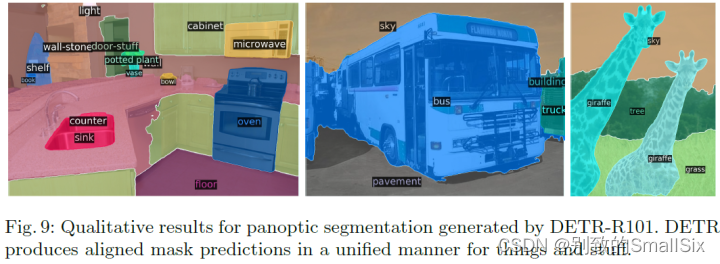
DETR还展示了COCO上的全景分割结果,可以看出实例区分能力还是比较有限。
2、c(谷歌Hinton)2022年
论文链接:
代码链接:https://github.com/google-research/pix2seq
一句话总结:一个简单而通用的目标检测新框架,其将目标检测转换为语言建模任务,大大简化了pipeline,性能可比肩Faster R-CNN和DETR!还可扩展到其他任务。
论文提出Pix2Seq,一个简单而通用的目标检测框架!!!与显式集成关于任务的先验知识的现有方法不同,Pix2seq将目标检测作为一个基于观察到的像素输入的语言建模任务。目标描述(例如,边界框和类标签)表示为离散token,训练神经网络来感知图像并生成所需序列。
Pix2seq主要基于这样一种直觉,即如果神经网络知道目标的位置和内容,我们只需要教它如何read them out。除了使用特定于任务的数据扩充,Pix2seq对任务的假设最少,但与高度专业化和优化的检测算法相比,它在具有挑战性的COCO数据集上取得了有竞争力的结果。
网络主要包含四个组件:
-
图像增强:正如在训练计算机视觉模型中常见的那样,论文使用图像增强来丰富一组固定的训练示例(例如,使用随机缩放和裁剪);
-
序列构造和扩充:由于图像的目标注释通常表示为一组边界框和类标签,论文将它们转换为一系列离散token;
-
架构:使用编码器-解码器模型,其中编码器感知像素输入,解码器生成目标序列(一次一个token);
-
目标/损失函数:对模型进行训练,以最大化基于图像和先前token的token的对数似然性(使用softmax cross-entropy loss)。
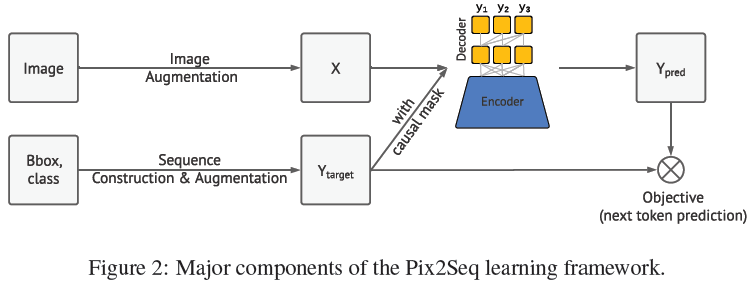
序列构造示意图:

训练300 epochs,实验结果:
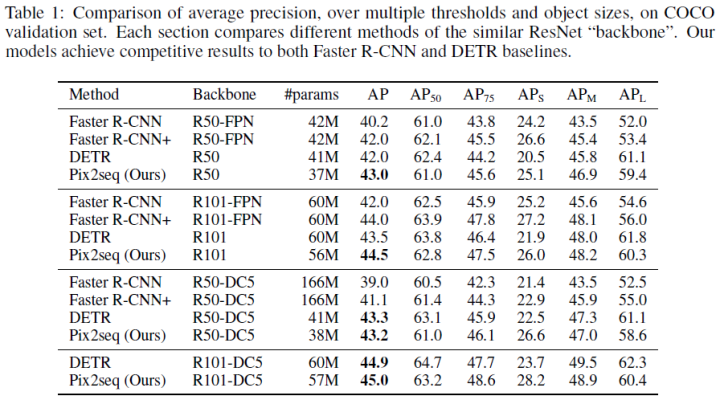
二、稀疏注意力
1、Deformable DETR(ICLR 2021)
论文链接:https://arxiv.org/abs/2010.04159
代码链接:https://github.com/fundamentalvision/Deformable-DETR
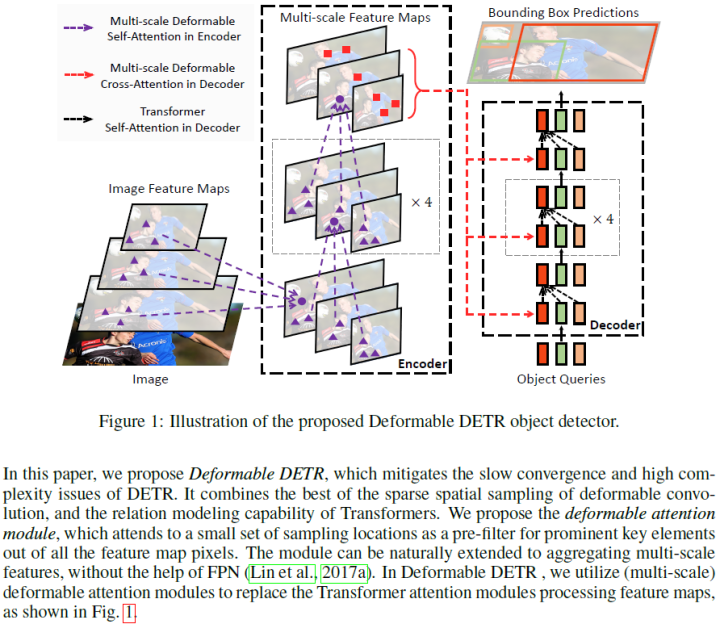
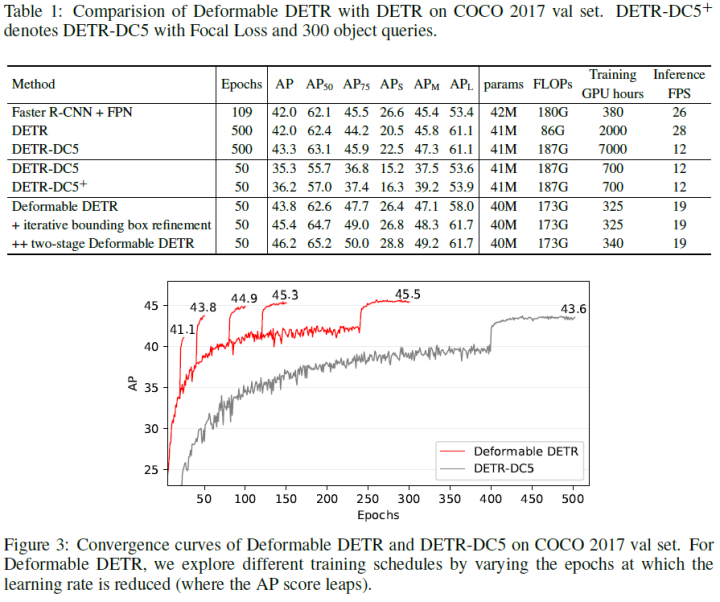
最近提出了DETR,以消除在物体检测中对许多手动设计部件的需要,同时证明了良好的性能。然而,由于Transformer注意力模块在处理图像特征图时的限制,它存在收敛速度慢和特征空间分辨率有限的问题。为了缓解这些问题,论文提出了Deformable DETR,其注意力模块只关注参考周围的一小组关键采样点。Deformable DETR可以实现比DETR更好的性能(特别是在小目标上),训练时间减少10倍。COCO基准的大量实验证明了算法的有效性。
- DETR存在的问题
-
训练周期长,相比faster rcnn慢10-20倍!
-
小目标性能差!通常用多尺度特征来解小目标,然而高分辨率的特征图大大提高DETR复杂度!
- 存在上述问题的原因
-
初始化时,attention model对于特征图上所有像素权重几乎是统一的(即一个query与所有的k相乘的贡献图比较均匀,理想状况是q与高度相关且稀疏的k相关性更强),因此需要长时间学习更好的attention map;
-
处理高分辨率特征存在计算量过大,存储复杂的特点;
- Motivation
-
让encoder初始化的权重不再是统一分布,即不再与所有key计算相似度,而是与更有意义的key计算相似度可变形卷积就是一种有效关注稀疏空间定位的方式;
-
提出deformable DETR,融合deformable conv的稀疏空间采样与transformer相关性建模能力在整体feature map像素中,模型关注小序列的采样位置作为预滤波,作为key。
实验结果
2、End-to-End Object Detection with Adaptive Clustering Transformer(北大&港中文)(2021年)
论文链接:https://arxiv.org/abs/2005.12872
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









