






导读
目前在工业界和学术界针对激光雷达和相机多模态融合的感知算法进行了广泛且深入的研究,并且取得了显著的成绩。相机可以捕获目标颜色和纹理等丰富的语义细节,激光雷达点云可以提供目标准确的深度和几何结构信息。利用图像和点云模态之间信息互补的优势,显著提升了3D目标检测任务的性能上限。
虽然多模态3D目标检测算法可以充分利用不同模态之间互补的信息,但是由于稀疏性和视角的差异,这些模态数据之间的内在差异性也会对多模态3D目标检测提出重大挑战。
此外,多模态的感知算法模型通常要优于使用单一模态的感知算法模型。但作者实验发现,与纯激光雷达的的3D目标检测算法相比,多模态的目标检测算法有时表现不佳。通过分析发现,由于固有的跨模态的差异性,来自不同模态的BEV特征在联合优化的过程中表现出来的收敛性是不同的,进而出现图像特征编码器比激光雷达特征编码器更慢地收敛到统一的BEV特征空间,导致欠拟合,最终影响多模态模型的3D感知性能,可视化中间结果如图1所示。
©️【深蓝AI】编译
论文标题:Efficient Multimodal 3D Object Detector via Instance-Level Contrastive Distillation
论文作者:Zhuoqun Su, Huimin Lu, Shuaifeng Jiao, Junhao Xiao, Yaonan Wang, Xieyuanli Chen
论文地址:https://arxiv.org/abs/2503.12914
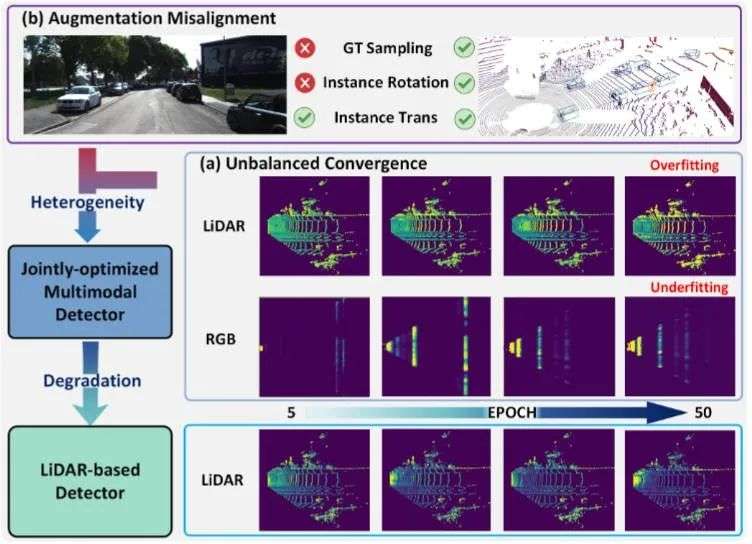
▲图1| 训练阶段不同模态特征之间的可视化结果对比©️【深蓝AI】编译
因此,针对上述发现的问题和多模态融合算法的固有挑战,本文提出了一个快速且有效的多模态3D目标检测算法框架。
本文的主要贡献如下:
-
本文提出了一种新颖的实例级对比蒸馏框架,用于3D目标检测。该框架实现了从单模态到多模态 3D检测器的高效知识蒸馏,并结合目标感知对比学习在统一的BEV空间中实现细粒度的模态对齐
-
引入了全新的交叉线性注意力融合模块,该模块有效地聚合了多模态的BEV特征,实现了线性复杂度的计算高效推理
-
在KITTI数据集上实现了SOTA的感知性能,同时运行速度比默认的LiDAR帧速率快14FPS
01 算法模型与实现细节

▲图2| 提出算法框架的整体流程图©️【深蓝AI】编译
本文提出的算法框架的整体流程如图2所示。具体而言,本文首先采用对齐的数据增强策略来保证输入的一致性。在训练过程中,通过双路的特征编码器,从图像和激光雷达数据中独立提取BEV特征。采用提出的实例级对比蒸馏框架,将预训练的激光雷达教师模型对相机学生模型进行对比蒸馏。此外,采用提出的交叉线性注意力融合模块高效处理两类不同模态的特征。
1.1. 实例级对比蒸馏
在模型训练过程中, 不同模态之间的收敛性不一致, 导致次优的检测结果。为了解决这个问题, 本文引入了一个知识蒸馏框架, 该框架增强了欠拟合模态的表示学习, 确保了平衡收敛并防止多模态 3D 目标检测器性能下降。
考虑到目标在 BEV 空间中所占像素比较少, 并且分布比较稀疏, 本文中将 3D 真值框映射到 BEV 空间的2D锚框用于完成后续的实例级的蒸馏任务。
再得到映射后的锚框后, 根据锚框位置对两个模态的 BEV 特征进行裁剪。同时为了并行计算, 裁剪后的特征被池化到了一个统一的尺寸大小。作者在实验过程中发现, 裁剪实例特征的大小不能进行任意的压缩或者回归为单个特征值或者向量, 否则会严重损坏 BEV 特征的上下文信息。
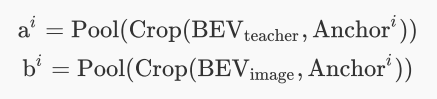
为了实现更精确的模态对齐并有效的完成实例级知识的蒸馏过程, 本文将结合了归一化温度的缩放交叉 熵损失引入到了知识蒸馏框架中。
其中, 代表实例在不同模态之间的相似性矩阵,
代表一个批次内的所有样本,
代表温度缩放参数, 在蒸馏的过程中自适应的进行学习,
和
代表正类和负类样本对。
1.2. 交叉线性注意力融合模块
在基于BEV特征的目标检测框架中,较大尺寸的BEV特征可以保留更为充足的空间上下文信息,但会限制计算密集型交叉注意力进行多模态融合过程。本文为了克服这一问题,提出了线性注意力融合模块,从而有效捕获具有线性复杂度的全局依赖关系,如图3所示。
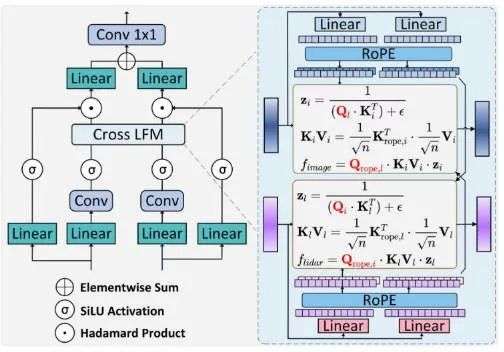
▲图3| 提出的交叉线性注意力融合模块网络架构图©️【深蓝AI】编译
具体而言,在两个融合并之前,首先分别经过线性层、3×3卷积层以及SiLU(激活函数)处理。在融合过程中,首先应用线性层获取Query、Key和Value矩阵。整个过程可以用如下的公式表示:
此外,两个额外的线性映射用于对特征进行通道变换,并且采用shortcut保留特征。
在本文中,作者采用激活函数和
来处理两个模态的query和key,用于在较大范围中引入遗忘效应。
本文提出的融合模块采用双向融合策略,集成图像到激光雷达到图像组建,实现有效且无偏的多模态融合。以图像到激光雷达融合为例,如下所示:
然后,激光雷达图像的融合也采用了类似的方法。为了将低级特征和高级特征进行融合,本文采用了图像与特征进行基于元素的相加,并经过一个卷积得到最终融合的DEVi特征。
02 实验
本文研究在nuScenes和KITTI两类自动驾驶数据集上进行了实验结果分析。图4和图5分别展示了提出的算法模型在KITTI和nuScenes数据集上与其他算法模型的实验结果对比,可以看出本文提出的算法模型实现了最佳的mAP性能指标。
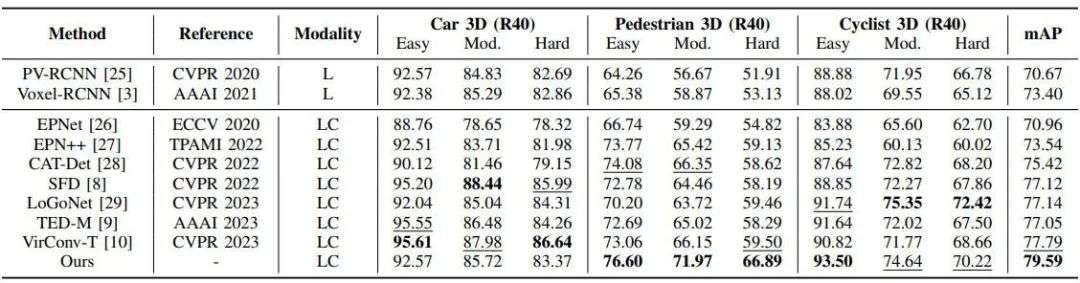
▲图4| 提出的算法模型与其他算法模型在KITTI数据集上的结果对比©️【深蓝AI】编译

▲图5| 提出的算法模型与其他算法模型在KITTI数据集上的结果对比©️【深蓝AI】编译
图6展示了本文提出的各类模块的消融对比实验,可以看出本文提出的各类模块均可以提升模型的检测性能表现。
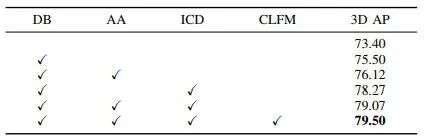
▲图6| 本文提出不同模块的消融对比实验©️【深蓝AI】编译
此外,为了更加直观的展示提出的算法模型的检测效果,本文对KITTI数据集的检测结果进行了可视化,其中绿色框代表真值,红色框代表检测结果。相关的可视化结果也可以验证本文提出的算法模型实现了最佳的表现性能。
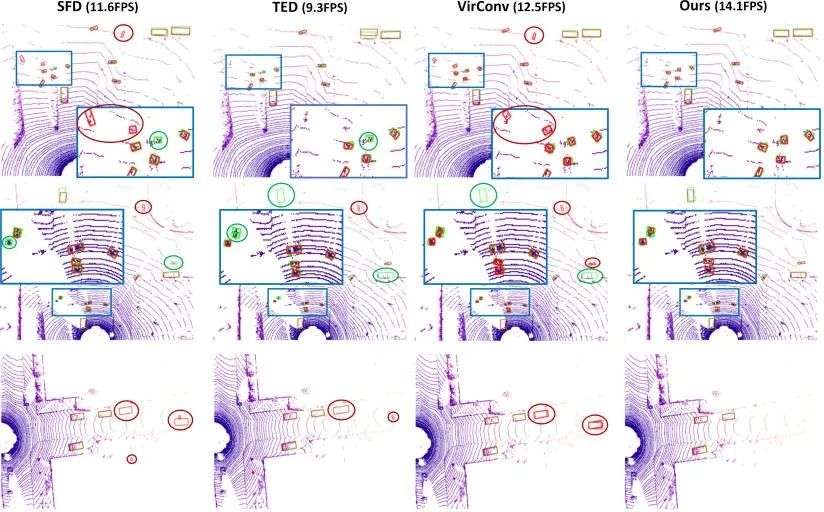
▲图7| 提出的算法模型与其他SOTA算法的检测结果可视化对比©️【深蓝AI】编译
03 结论
在本文中,作者提出了结合交叉线性注意力融合模块的实例级对比蒸馏框架,实现了一种快速、高性能的多模态3D目标检测器。相关的实验结果表明,提出的算法模型在KITTI数据集上超过了现有的算法模型,实现了SOTA的检测性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









