






在大型语言模型的后训练中,强化学习已成为实现推理能力跃升的关键技术,但现有方法面临跨领域奖励信号缺失的瓶颈——传统奖励模型难以覆盖开放域任务,且依赖人工规则或可验证问题的局限明显。
©️【深蓝AI】编译
本文由paper一作——Zijun Liu授权【深蓝AI】编译发布!
论文标题:Inference-Time Scaling for Generalist Reward Modeling
论文作者:Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, Yu Wu
论文地址:https://arxiv.org/pdf/2504.02495
DeepSeek团队针对这一挑战,提出两项突破性创新:
其一,采用生成式奖励建模(GRM)框架,通过动态生成原则与评估的"自我原则批判调优"(SPCT)方法,使奖励模型在在线RL训练中实现自适应原则生成与精准评判;
其二,首创"推理时算力扩展"范式,结合并行采样生成多样化反馈与元奖励模型投票机制,突破传统训练时算力投入的边际效应。实验表明,DeepSeek-GRM在多个基准测试中显著优于现有方法,且在复杂开放域任务中展现出抗偏置优势。这项研究不仅为LLMs的奖励系统提供了可扩展的新范式,更通过开源模型推动社区向可信、通用的人工智能对齐迈进,标志着从"训练算力堆砌"向"推理效能跃迁"的重要转折。
1.引入
随着大型语言模型(LLMs)的显著进展,人工智能研究正在发生深刻变革,使得模型能够执行理解、生成及复杂决策等任务。近年来,强化学习(RL)作为LLM后训练的一种方法被广泛采用,显著提升了模型在对齐人类价值观、长程推理能力以及环境适应性方面的表现。作为RL的重要组成部分,奖励建模(RM)对于生成准确的奖励信号至关重要。已有研究表明,只要在训练或推理阶段获得高质量和稳健的奖励,LLMs在特定领域内即可表现出强大的能力。
然而,这类高质量奖励通常来源于条件明确的人类设计环境或可验证问题的手工规则,例如部分数学问题或编程任务。对于更广泛的一般领域,奖励的生成面临更多挑战,因为奖励的标准更加多样和复杂,往往缺乏明确的参考或标准答案。因此,泛化的奖励建模对于提升LLMs在广泛应用中的表现至关重要,无论是在后训练阶段还是在推理阶段,例如基于RM引导的搜索。此外,RM的性能提升不仅依赖于训练时的算力,也需利用推理时的计算资源。
在实践中,使奖励模型在推理阶段既具泛化能力又具可扩展性仍然存在诸多挑战。泛化RM需要具备以下能力:(1) 适配不同类型输入的灵活性;(2) 在各种领域中生成准确奖励的能力。同时,有效的推理时可扩展性还要求:(3) 随着推理计算量的增加,生成更高质量的奖励信号;(4) 学会可扩展的行为,以实现更优的性能-算力扩展效率。
该研究分析了现有RM中的若干主流奖励生成范式,如标量式、半标量式及生成式,以及打分策略,如点对点评分和成对比较。这些方法天然决定了模型的输入灵活性和推理时的可扩展性。例如,成对式RM仅对两个响应之间的相对偏好进行比较,无法灵活地接受单个或多个响应作为输入;而标量式RM则难以针对同一响应生成多样的奖励,从而限制了基于采样的推理扩展方式的效果。同时,不同的学习方法虽然在一定程度上提高了奖励质量,但鲜有研究关注推理时的可扩展性以及奖励生成行为与推理可扩展性之间的关系,因此性能提升有限。
该研究探索了不同的RM方式,并发现点对点生成式奖励建模(GRM)可以通过语言表示统一单响应、成对响应以及多响应的评分,具备更强的输入灵活性。研究进一步发现,借助合适的原则可以引导GRM在一定标准下生成奖励,从而提升其质量。这启发研究者思考是否可以通过大规模生成高质量原则与评析内容,从而实现RM在推理阶段的可扩展性。
基于此,该研究提出了一种新的学习方法——自驱原则性评析调优(Self-Principled Critique Tuning, SPCT),旨在通过规则驱动的在线强化学习,使GRM能够根据输入查询和响应自适应地产出原则与评析内容,以支持泛化奖励生成。在此基础上,研究进一步构建了基于Gemma-2-27B模型后训练的DeepSeek-GRM-27B。为了实现推理时的计算扩展,该研究采用并行采样方式,使模型能够在不同的原则下生成多个评析内容并进行投票,提升奖励判断的准确性与细粒度。
此外,该研究还训练了一个元RM模型,用于在采样阶段辅助投票过程,进一步提升推理时的可扩展性能。实验结果表明,SPCT方法能显著提升GRM的质量与推理可扩展性,在多个奖励建模评测基准中优于现有方法与模型,且相较于训练时通过扩大模型规模的扩展方式,该研究提出的方法在某些条件下表现更佳。尽管DeepSeek-GRM在部分任务中仍存在挑战,但研究者认为,随着后续对泛化奖励系统的持续改进,相关挑战将有望被克服。
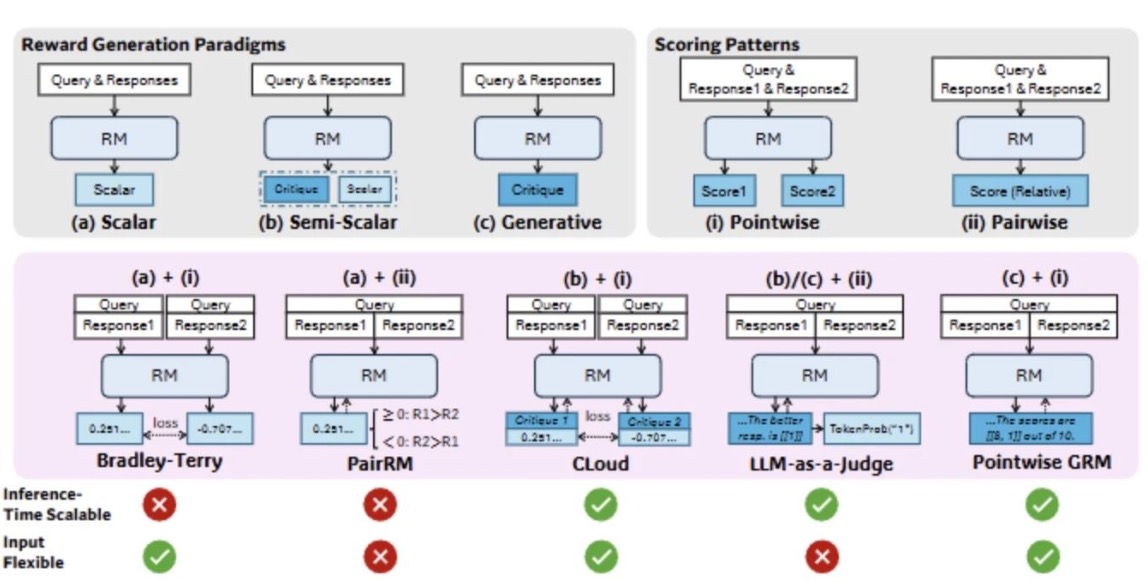
图1|奖励生成的不同范式包括:(a) 标量式、(b) 半标量式 和 (c) 生成式方法,以及不同的评分模式,包括:(i) 逐点式 和 (ii) 成对式 方法。我们列出了每种范式的代表性方法,并分别说明其推理时可扩展性(是否可以通过多次采样获得更好的奖励)和输入灵活性(是否支持对单个或多个响应进行评分)©️【深蓝AI】编译
2. 具体方法与实现
2.1 自驱原则性评析调优(Self-Principled Critique Tuning, SPCT)
受到前期实验的启发,该研究提出了一种新方法,旨在使点对点生成式奖励模型(GRMs)学会生成自适应且高质量的原则,以有效引导评析内容的生成。该方法被称为自驱原则性评析调优(SPCT)。如图3所示,SPCT包含两个阶段:拒斥微调(Rejective Fine-Tuning, RFT)作为冷启动过程,以及基于规则的在线强化学习,用于通过优化生成的原则和评析内容来增强泛化奖励生成能力。SPCT还能够促进GRMs在推理时的可扩展行为。
2.1.1 从理解到生成:原则的解耦
前期实验表明,合适的原则可以在特定标准下有效引导奖励生成,从而产出更高质量的奖励。然而,在大规模泛化奖励建模中,生成有效的原则仍具挑战性。为应对这一问题,该研究提出将原则从预设理解转变为可生成内容,即将原则视为奖励生成过程的一部分,而非前置的处理步骤。
形式上,原则用于指导奖励生成过程。在没有预定义原则的情况下,GRM可以首先生成原则,再基于这些原则生成评析内容。其流程为:
● 原则:由模型函数生成;
● 奖励(评析内容):由同一个模型根据输入问题、响应以及生成的原则生成。
这种转换使得原则的生成能够根据输入查询与响应自适应地调整,从而提高评析内容的质量与粒度。借助后训练技术,GRM能够进一步提升原则与评析内容的质量,并支持更大规模原则的生成,从而为推理时扩展奠定基础。
2.1.2 基于规则的强化学习
为同步优化GRM中原则与评析内容的生成能力,该研究将SPCT设计为融合拒斥微调(RFT)与基于规则的在线强化学习的训练框架。
拒斥微调(冷启动)
该阶段的核心目标是使GRM适应生成格式正确、面向多种输入类型的原则与评析内容。不同于以往将单响应、成对响应与多响应数据格式混合的方式,该研究统一采用点对点GRM结构,实现对任意数量响应的灵活处理。
在数据构造方面,研究除了使用通用指令数据外,还利用预训练GRM采样生成的轨迹数据,样本采样次数为。轨迹拒斥策略为:若模型预测的奖励结果与真实值不一致,则标记为“错误”;若所有采样都正确,则认为任务“过于简单”,一并剔除。
此外,研究还提出“提示采样”机制(hinted sampling):对每个任务样本,GRM仅采样一次,模型输入中加入真实最优响应的位置信息,以鼓励生成正确评析内容。然而研究发现,提示采样有时会导致模型对推理过程产生“捷径”,特别是在复杂任务中,表明有必要引入在线强化学习进一步优化评析过程。
基于规则的在线强化学习
在此阶段,GRM被进一步优化以生成更优的原则与评析内容。研究采用基于规则的奖励定义,并基于GRPO方法进行训练。具体地,GRM生成原则与评析内容,系统从中提取奖励值,并依据真实奖励判断其正确性,从而给予模型正负反馈。为避免格式错误,该研究未使用格式化奖励,而是通过加大KL散度惩罚系数的方式进行约束。
该奖励函数鼓励GRM根据输入选择最佳响应,并通过优化生成的原则与评析内容实现更有效的推理时扩展。奖励信号可从任意偏好数据集中获得。
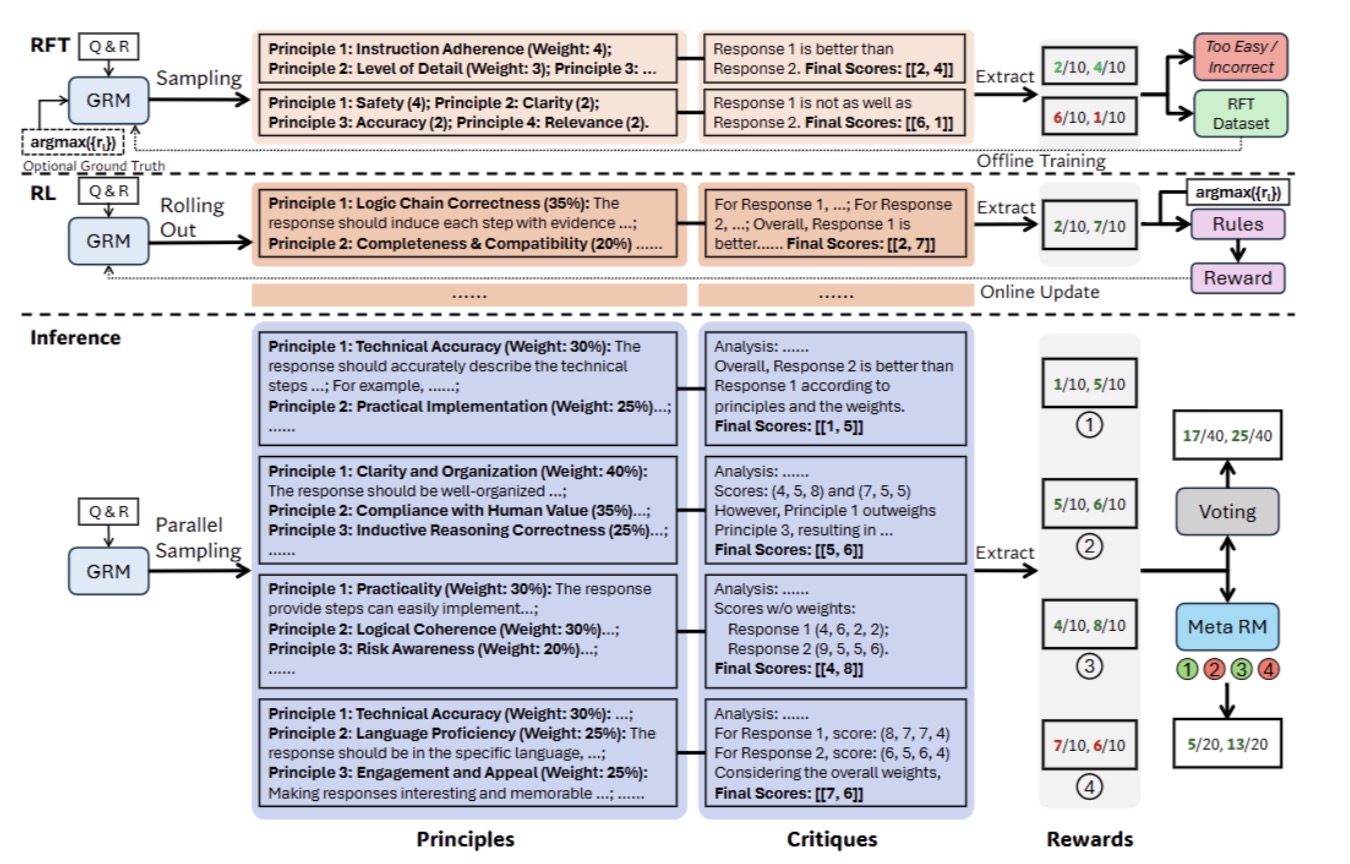
图2|SPCT流程示意图,包含拒绝式微调(rejective fine-tuning)、基于规则的强化学习(rule-based RL),以及推理阶段对应的可扩展行为。推理时扩展能力通过两种方式实现:基础投票机制(naive voting)或基于元奖励模型(meta RM)引导的规模化原则生成投票机制,从而在扩展的价值空间内生成更细粒度的结果奖励©️【深蓝AI】编译
2.2 借助SPCT实现推理时扩展(Inference-Time Scaling with SPCT)
为进一步提升DeepSeek-GRM在泛化奖励生成任务中的表现,该研究探索了基于采样的推理时扩展策略,以更充分地利用推理阶段的计算资源。该研究分析了现有方法的潜力与局限,并提出以下两种推理扩展方式:
投票机制(Voting with Generated Rewards)
如第二部分所述,在点对点评分机制下,GRM对每一组采样生成的评析内容给出一组奖励评分。投票过程将这些奖励累加,得到最终评分:
其中是第
个响应的最终得分,
是第
次采样对应的得分。每次采样中生成不同的原则与评析内容,增加了最终奖励的多样性与粒度。
从直观上理解,每条原则可以视为一种评判维度,原则数量的增加有助于模拟出更贴近真实的评判分布,从而提升扩展效果。此外,为避免位置偏差,研究在采样前会对响应顺序进行打乱处理。
元RM引导的投票(Meta Reward Modeling Guided Voting)
由于采样中的一部分评析内容可能存在质量低或偏差的问题,该研究引入了一个元RM模型,以指导投票过程。该模型为点对点标量RM,训练目标为判断某条原则-评析对是否正确(使用二分类交叉熵损失)。训练数据来自RFT阶段中的非提示采样轨迹,以及DeepSeek-GRM自身采样的样本,从而同时包含正负样本,并减少训练与推理策略之间的差异。
在推理时,元RM会对每个采样样本输出“元奖励”评分,仅保留得分排名靠前的个样本参与最终投票。这一机制能有效过滤低质量轨迹,从而进一步提高推理时扩展效果。
3.实验
基准任务与评估指标
该研究在多个来自不同领域的奖励建模基准任务上评估方法性能,包括 Reward Bench、PPE、RMB 和 ReaLMistake。每个基准任务使用其标准评估指标:
● 在 Reward Bench、PPE 和 RMB 中,评估指标为从一组响应中选出最佳响应的准确率;
● 在 ReaLMistake 中,评估指标为 ROC-AUC 分数。
当多个响应的预测奖励分数出现相同情况时,该研究采用随机打乱响应顺序来确定最终选择的响应。对于提出的方法,该研究实现了 DeepSeek-GRM-27B-RFT(冷启动阶段版本),并在不同规模的语言模型上训练了 DeepSeek-GRM,包括 DeepSeek-V2-Lite(16B MoE)、Gemma-2-27B、DeepSeek-V2.5(236B MoE)以及 DeepSeek-V3(671B MoE)。元RM(meta RM)则基于 Gemma-2-27B 训练完成。
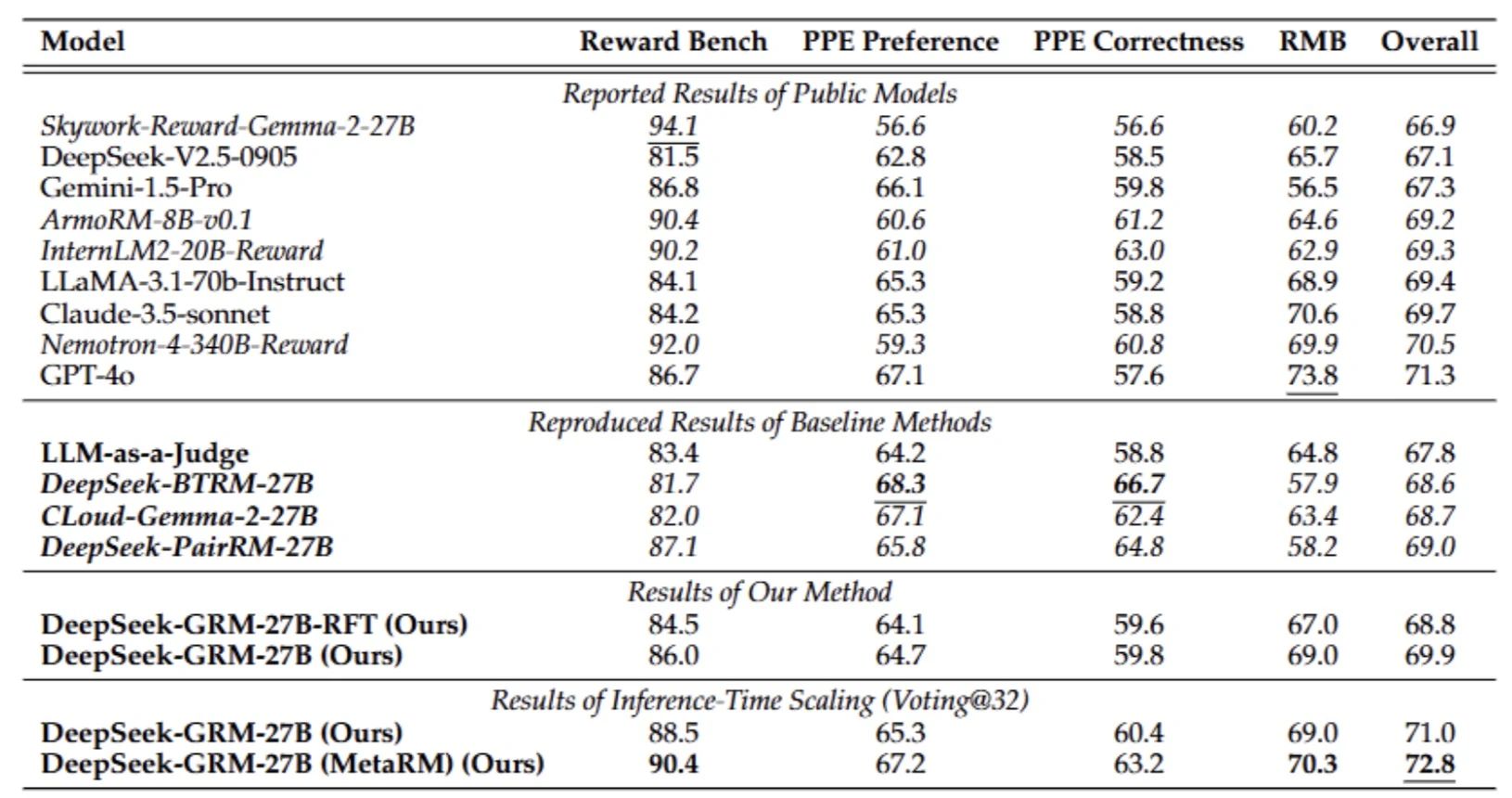
图3|不同方法与模型在奖励模型基准测试中的总体结果对比©️【深蓝AI】编译
整体评估结果如上图所示。该研究将 DeepSeek-GRM-27B 的表现与多个公开模型以及基线方法进行了比较。结果表明,DeepSeek-GRM-27B 在整体表现上超过了所有基线方法,并在多个任务中接近甚至优于 Nemotron-4-340B-Reward 和 GPT-4o 等强大公共奖励模型。在启用推理时扩展后,DeepSeek-GRM-27B 的表现进一步提升,取得最佳综合成绩。
具体来看,标量(如 DeepSeek-BTRM-27B 和 DeepSeek-PairRM-27B)与半标量(如 CLoud-Gemma-2-27B)奖励模型在可验证任务(如 PPE Correctness)上表现较好,但在其他基准任务中则存在明显欠缺,表现出强烈的领域偏差。相比之下,DeepSeek-GRM-27B 能够在多个任务上稳定输出较优结果,具有更强的泛化能力。
LLM-as-a-Judge 方法的趋势与 DeepSeek-GRM-27B 相似,但整体性能较低,可能是由于缺乏原则性引导机制。因此,该研究认为 SPCT 所引入的原则生成机制显著增强了 GRM 的泛化奖励生成能力,同时也降低了偏差程度。
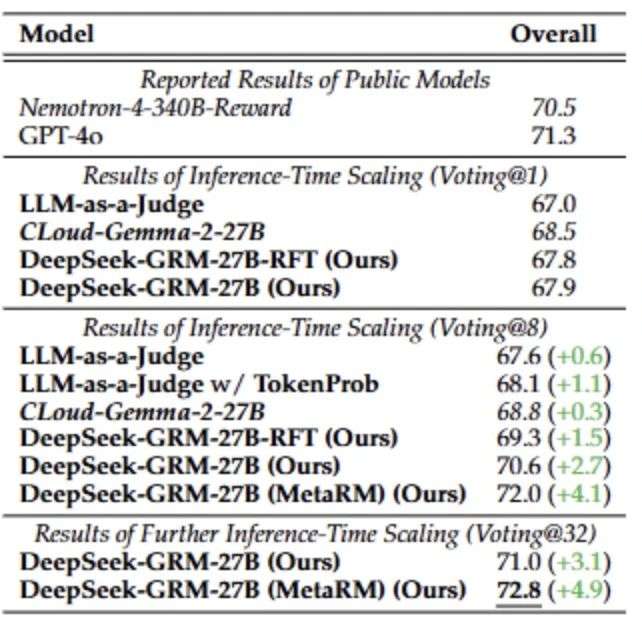
各方法在推理扩展下的表现如图4所示。该研究发现:
● 在最多8次采样的条件下,DeepSeek-GRM-27B 相比贪婪解码表现出最大提升;
● 随着采样次数增至32次,性能继续增长;
● 元RM(Meta RM)在多个基准测试中验证了其在过滤低质量样本方面的有效性。
此外,在投票过程中引入 token 概率作为权重(如 LLM-as-a-Judge + TokenProb),也显著提升了表现,说明概率信息对于提升投票可靠性是有益的。而对于标量奖励模型(如 CLoud-Gemma-2-27B),其生成的奖励本身变化不大,即使评析内容有所不同,性能提升仍受限。
综上,SPCT 有效增强了 GRM 的推理时可扩展性,而元RM进一步放大了这一能力。
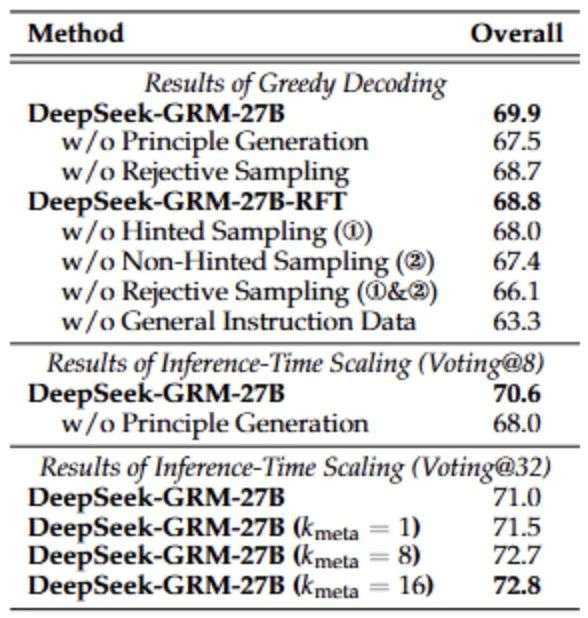
图5展示了关于 SPCT 不同组件的消融实验结果。研究发现:
● 即便未采用冷启动训练,仅使用通用指令数据并结合在线强化学习,也能显著提升性能(66.1 → 68.7);
● 非提示采样比提示采样效果更显著,说明提示采样可能存在“捷径”问题,尤其在推理任务中。
此外,该研究确认通用指令数据对GRM训练效果至关重要,而原则生成机制则是 DeepSeek-GRM-27B 在贪婪解码与推理扩展中性能提升的关键因素。对于推理扩展,元RM引导的投票机制在不同的设置下都表现出良好的鲁棒性。
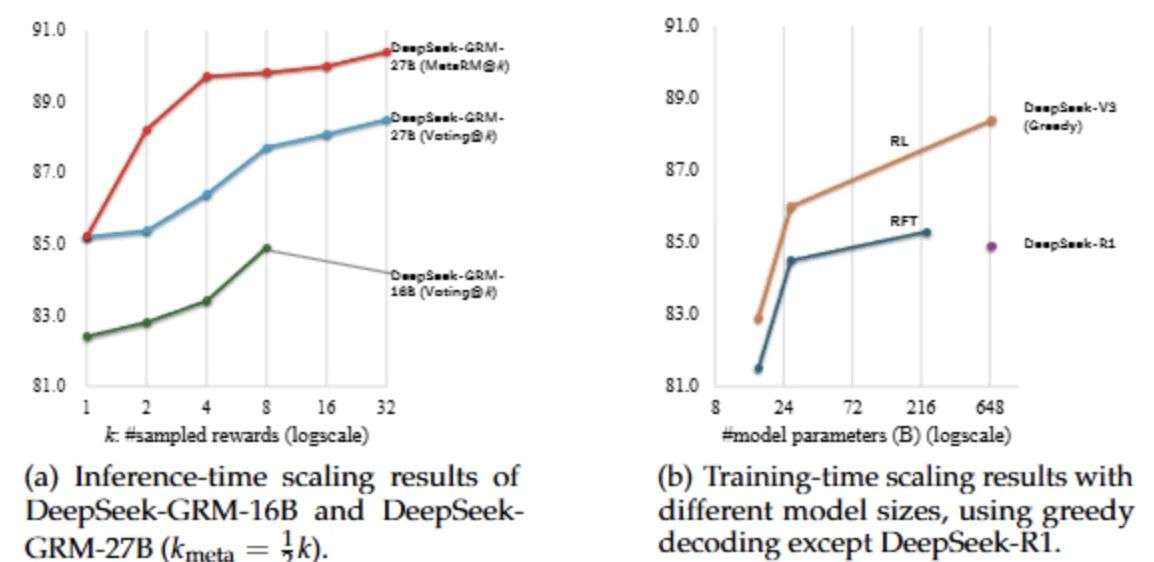
为进一步验证模型扩展能力,该研究对比了不同模型规模下的训练扩展性与推理时扩展能力。在 Reward Bench 基准任务上测试发现:
● 使用32次采样的 DeepSeek-GRM-27B,其表现可与671B参数量的 DeepSeek-V3 相媲美;
● 使用元RM指导的推理扩展在仅8次采样下即可达到最佳性能;
● 一个特化用于长链条推理任务(CoT)的DeepSeek-R1模型,在部分评测中表现甚至不如236B的后训练模型,表明简单增加推理深度未必能提高奖励建模性能。
总结
该研究提出了一种名为**自驱原则性评析调优(Self-Principled Critique Tuning, SPCT)的方法,用于提升泛化奖励建模(generalist reward modeling)**在推理阶段的可扩展性。借助基于规则的在线强化学习,SPCT 能够引导模型自适应地生成“原则”与“评析内容”,显著提升了奖励质量和在多领域任务中的推理时扩展能力。
实证结果表明,基于 SPCT 训练的 DeepSeek-GRM 模型在多个奖励建模基准任务中,超越了现有基线方法与部分强大的公开奖励模型。同时,在推理时增加计算资源(如并行采样、元RM辅助投票等)后,模型性能进一步提升,展现出出色的可扩展潜力。
展望未来,该研究认为泛化奖励模型可以进一步发展成为:
● 在线强化学习系统中的奖励接口,作为通用且灵活的奖励生成模块;
● 与策略模型协同扩展的联合推理系统,共同提升决策质量;
● 大模型评估任务中的稳健离线评价器,支持对基础模型的全面评估与诊断。
这些方向不仅有望扩展当前研究成果的应用边界,也将进一步推动语言模型在后训练与推理阶段的能力进化。

















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









