







文章目录

模型简介
2025年4月5日,meta发布了llama系列模型的第四代,包括Scout、Maverick和Behemoth。
llama4支持多模态理解,工具调用,编程,多语种任务(暂不支持中文),知识截止到24年8月。多模态支持上,可输入文本和最多5张图片,输出文本;
主要亮点:Maverick和 Scout模型此次也是首次采用了MoE混合专家结构,并且主打的亮点是原生的多模态能力、1千万上下文窗口,目前已经发布权重可用。
Scout和Maverick都由Behemoth蒸馏得到,使用了一种新的蒸馏损失函数,通过训练动态加权软目标和硬目标。Llama 4 Behemoth模型还在训练中,尚未放出。
模型尺寸
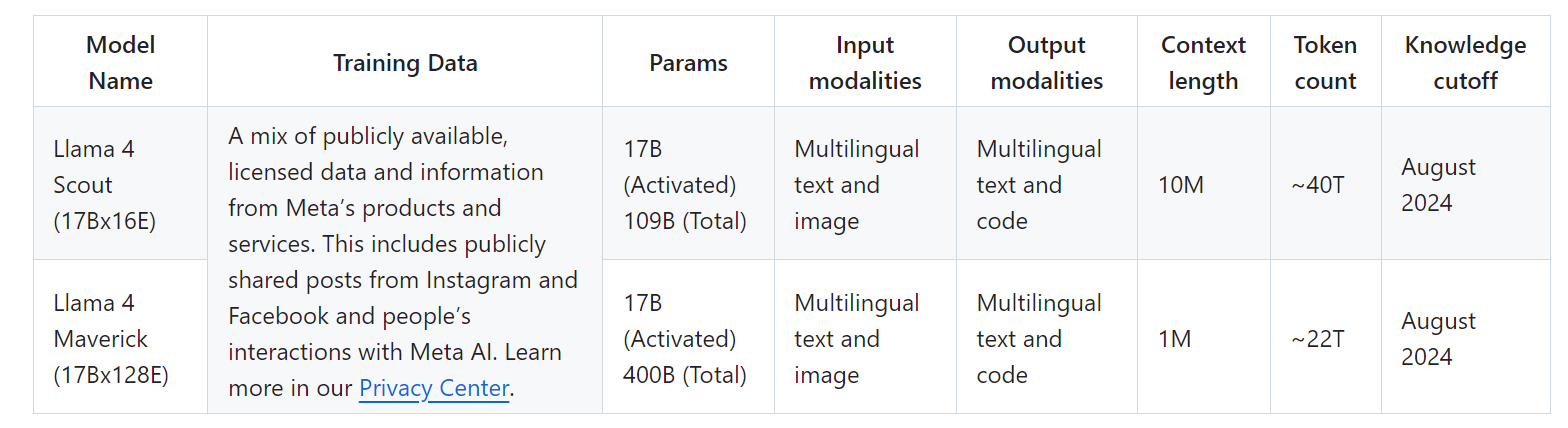
llama4系列模型包括三个尺寸:
- 小杯:Llama 4 Scout
16个专家,17B激活参数,支持10M上下文窗口,在一系列benckmark的测评结果优于Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1。 - 中杯: Llama 4 Maverick
128个专家,17B激活参数,在多模态任务benckmarks上优于GPT-4o和Gemini 2.0 Flash, reasoning和coding能力打平deepseek V3。 - 大杯:Llama 4 Behemoth
16个专家,228B激活参数,2万亿(2T)个总参数, 在STEM任务benckmarks上优于GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro。
训练数据
lama 4 Scout 在大约 40 万亿个token的数据上进行了预训练,而 Llama 4 Maverick 则在大约 22 万亿个多模态token的数据上进行了预训练。这些数据来自公开可用的、获得许可的数据,以及来自 Meta 的产品和服务的信息。这包括 Instagram 和 Facebook 上公开分享的帖子以及人们与 Meta AI 的互动。
微调数据:采用多管齐下的数据收集方法,将供应商(vendors)提供的人工生成数据与合成数据相结合,以降低潜在的安全风险。同时开发了许多基于大语言模型(LLM)的分类器,这些分类器能够帮助训练团队精心挑选高质量的提示和回答,从而加强数据质量控制。
训练能耗
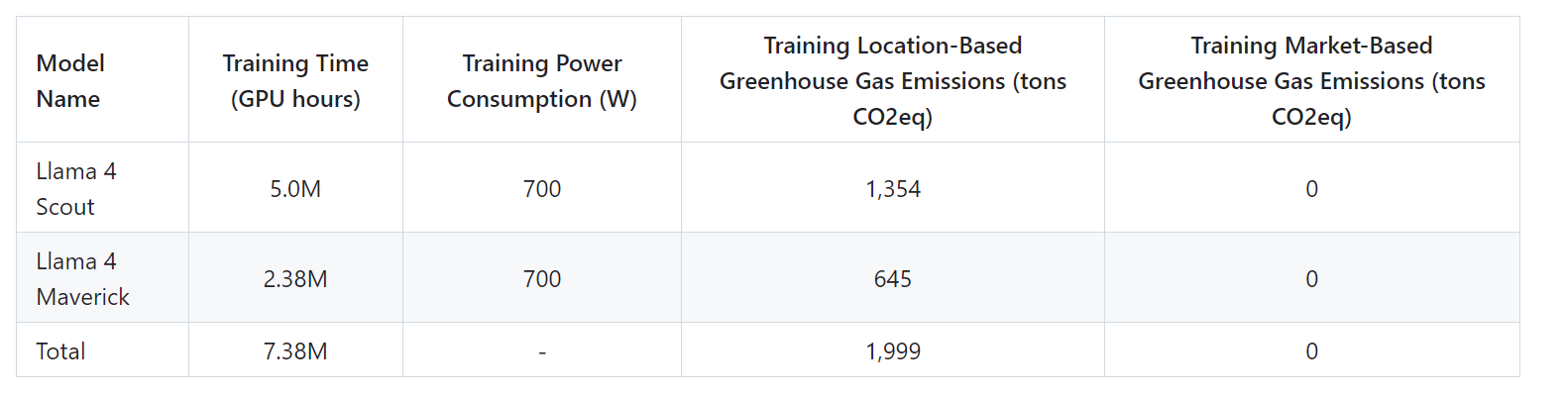
模型预训练累计使用了738万小时的H100-80GB(TDP为700瓦)型号硬件计算时间,具体如下表所示。训练时间是指训练每个模型所需的总GPU时间,功耗是指每个GPU设备使用的峰值功率容量,已根据功率使用效率进行了调整。
量化
Llama 4 Scout模型以BF16权重的形式发布,但可以通过即时int4量化在单个H100 GPU上运行;Llama 4 Maverick模型则以BF16和FP8量化权重的形式发布。FP8量化权重可以在单个H100 DGX主机上运行,同时保持质量。Meta还提供了即时int4量化的代码,以尽量减少性能下降。
预训练
MoE架构
llama4模型是llama系列中首次使用MoE架构的模型。在MoE模型中,单个token仅激活总参数的一部分。MoE架构在训练和推理方面更具计算效率,并且在固定的训练浮点运算预算下,与密集模型相比能够提供更高的质量。
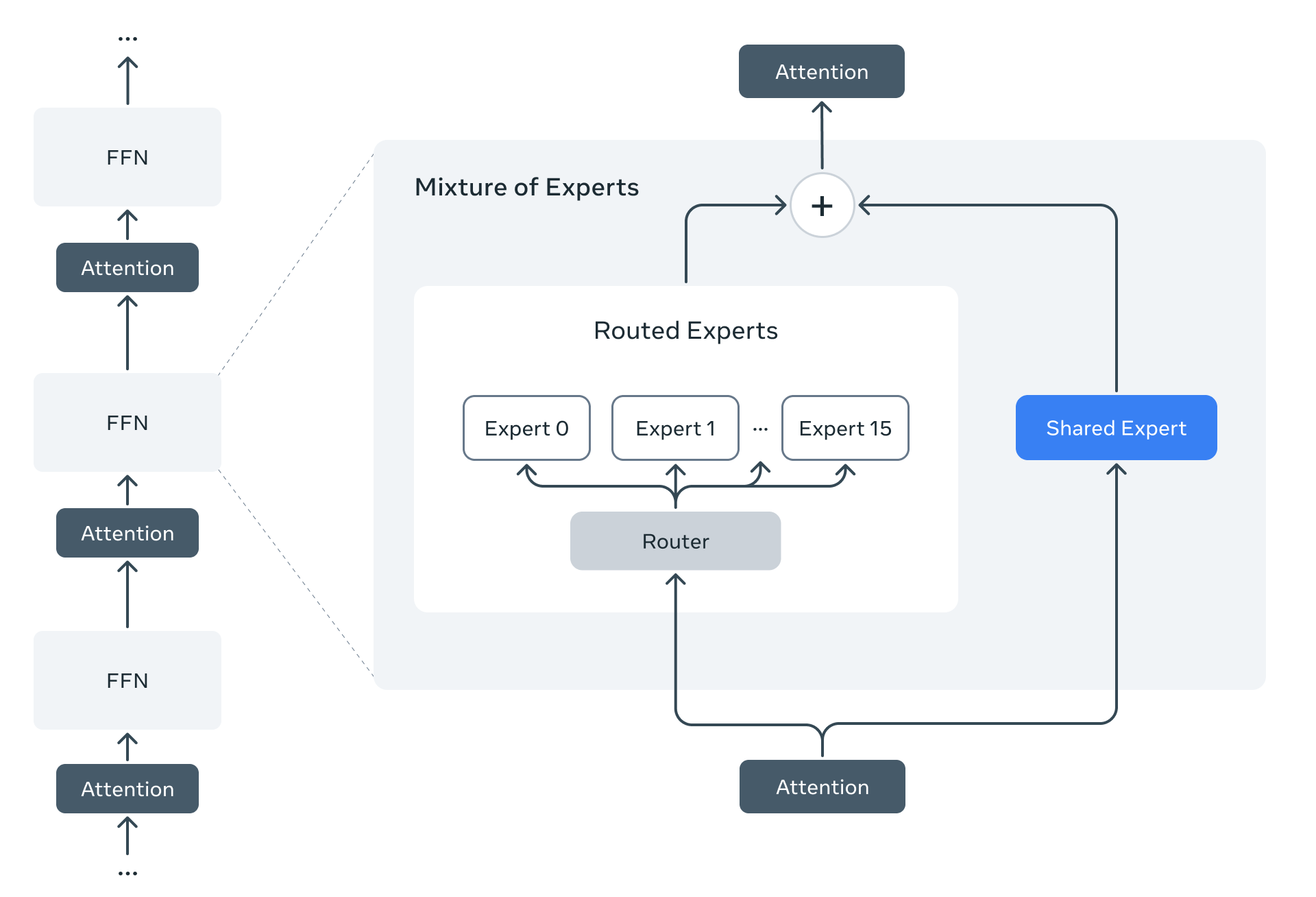
Llama4 MoE层采用多个路由专家和一个共享专家的结构。以Llama 4 Maverick模型为例,它拥有170亿活跃参数和4000亿总参数。采用交替的密集层和混合专家(MoE)层来提高推理效率。MoE层使用128个路由专家和一个共享专家。每个token都会被发送到共享专家以及128个路由专家中的一个。
因此,尽管所有参数都存储在内存中,但在使用这些模型时,只有总参数的一部分会被激活。这通过降低模型服务成本和延迟来提高推理效率——Llama 4 Maverick可以在单台NVIDIA H100 DGX主机上运行,便于部署,也可以通过分布式推理实现最高效率。
class Llama4TextMoe(nn.Module):
def __init__(self, config):
super().__init__()
self.top_k = config.num_experts_per_tok
self.hidden_dim = config.hidden_size
self.num_experts = config.num_local_experts
self.experts = Llama4TextExperts(config)
self.router = nn.Linear(config.hidden_size, config.num_local_experts, bias=False)
self.shared_expert = Llama4TextMLP(config)
def forward(self, hidden_states):
batch, seq_len, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, self.hidden_dim)
router_logits = self.router(hidden_states).transpose(0, 1)
tokens_per_expert = batch * seq_len
router_top_value, router_indices = torch.topk(router_logits.transpose(0, 1), self.top_k, dim=1)
router_scores = (
torch.full_like(router_logits.transpose(0, 1), float("-inf"))
.scatter_(1, router_indices, router_top_value)
.transpose(0, 1)
)
# We do this to make sure we have -inf for non topK tokens before going through the !
# Here we are just creating a tensor to index each and every single one of the hidden states. Let s maybe register a buffer for this!
router_indices = (
torch.arange(tokens_per_expert, device=hidden_states.device).view(1, -1).expand(router_scores.size(0), -1)
)
router_scores = torch.sigmoid(router_scores.float()).to(hidden_states.dtype)
router_indices = router_indices.reshape(-1, 1).expand(-1, hidden_dim)
routed_in = torch.gather(
input=hidden_states,
dim=0,
index=router_indices,
).to(hidden_states.device)
# we gather inputs corresponding to each expert based on the router indices
routed_in = routed_in * router_scores.reshape(-1, 1)
routed_out = self.experts(routed_in)
out = self.shared_expert(hidden_states)
# now that we finished expert computation -> we scatter add because we gathered previously
# we have to do this because we used all experts on all tokens. This is faster than the for loop, tho you are compute bound
# this scales a lot better if you do EP!
out.scatter_add_(dim=0, index=router_indices, src=routed_out.view(-1, hidden_dim))
return out, router_scores
原生多模态能力
early fusion
llama4的设计融入了原生多模态能力,通过早融合将文本和视觉标记无缝整合到一个统一的模型主干中,early fusion在数据输入阶段将多个模态的数据进行融合,使得能够用大量的未标记文本、图像和视频数据联合预训练模型。
基于MetaCLIP的视觉编码器改进
在Llama 4中改进了视觉编码器。该编码器基于MetaCLIP,但与冻结的Llama模型一起单独训练,以更好地使编码器适应LLM。
MetaCLIP在CLIP的基础上改进了数据策划方法(data curation),采用原始数据池和元数据,并生成一个在元数据分布上平衡的子集。
MetaCLIP论文地址:https://arxiv.org/abs/2309.16671
新训练技巧MetaP
llama4使用了一种新的训练技巧MetaP。MetaP能够可靠地设置关键模型超参数,例如每层的学习率和初始化规模。在实验中发现,选定的超参数在不同批量大小、模型宽度、深度和训练标记数量的值之间具有良好的迁移性。Llama 4通过在200种语言上进行预训练,其中包括超过100种每种超过10亿token的语言,以及总体上比Llama 3多10倍的多语言token从而支持开源微调工作。
高效模型训练
通过使用 FP8 精度,专注于高效模型训练,同时不牺牲质量并确保高模型浮点运算利用率——在使用 FP8 和 32,000 块 GPU 预训练Llama 4 Behemoth 模型时,实现了每块 GPU 390 万亿次浮点运算(TFLOPs)。用于训练的整体数据混合包含超过 30 万亿个token,这比 Llama 3 的预训练数据混合多出一倍以上,涵盖了多样化的文本、图像和视频数据集。
1000万输入上下文长度
在所谓的“中期训练”(mid-training)阶段对模型进行训练,通过引入新的训练方案(包括使用专门的数据集扩展长文本上下文)来提升模型的核心能力。这不仅提高了模型的质量,还为Llama 4 Scout解锁了行业内领先的1000万输入上下文长度。
后训练
课程策略
在对Llama 4 Maverick模型进行后训练时,最大的挑战是保持多种输入模态、推理能力和对话能力之间的平衡。为了混合模态,LLAMA4团队设计了一种精心策划的课程策略(curated curriculum strategy),该策略与单一模态专家模型相比,并不牺牲性能。
post-training pipeline
在Llama 4中,通过采用不同的方法彻底改进了我们的后训练流程:轻量级监督微调(SFT)→在线强化学习(RL)→轻量级直接偏好优化(DPO)。
- 一个关键的发现是,SFT和DPO可能会过度约束模型,限制其在在线RL阶段的探索能力,从而导致推理、编程和数学领域的准确率欠佳。为了解决这个问题,使用Llama模型作为评判工具,剔除了超过50%被标记为简单的数据,并对剩余的较难数据集进行轻量级SFT。
- 在随后的多模态在线强化学习阶段,通过精心挑选较难的prompts,成功实现了性能的跃升。
- 此外,实施了一种连续在线RL策略,即交替进行模型训练和利用模型持续筛选并保留中等到较难难度的提示。这种策略在计算资源和准确率的权衡方面被证明极为有益。
- 之后,进行了轻量级DPO,以处理与模型响应质量相关的边缘情况,有效地在模型的智能和对话能力之间取得了良好的平衡。
这种流程架构以及带有自适应数据筛选的连续在线RL策略,最终造就了一款行业领先的通用聊天模型,它在智能和图像理解能力方面都达到了顶尖水平。
iRoPE架构
Llama 4 架构中的一项关键创新是使用交错注意力层,而无需位置嵌入。采用注意力的推理时间温度缩放来增强长度泛化。称之为 iRoPE 架构,其中“i”代表“interleaved”注意力层,突出了支持“无限”上下文长度的长期目标,而“RoPE”是指大多数层中采用的旋转位置嵌入。
参考论文:
The Impact of Positional Encoding on Length Generalization in Transformers: https://arxiv.org/pdf/2501.19399
Scalable-Softmax Is Superior for Attention: https://arxiv.org/abs/2305.19466
class Llama4TextRotaryEmbedding(nn.Module):
def __init__(self, config: Llama4TextConfig, device=None):
super().__init__()
# BC: "rope_type" was originally "type"
self.rope_type = "llama3" if config.rope_scaling is not None else "default" # 动态RoPE模式选择
# 最大缓存序列长度(训练时设置的256K)
self.max_seq_len_cached = config.max_position_embeddings
self.original_max_seq_len = config.max_position_embeddings # 原始训练长度基准
self.config = config
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type] # 动态频率初始化函数
# 生成基础频率参数θ(公式θ_m=10000^(-2m/d))
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
self.register_buffer("inv_freq", inv_freq, persistent=False) # 注册为不可训练参数
self.original_inv_freq = self.inv_freq # 保存原始频率参数
def _dynamic_frequency_update(self, position_ids, device):
"""
动态频率更新机制(iRoPE核心技术)
两种情况触发更新:
1. 序列超过当前缓存长度(允许外推)
2. 序列回退到原始长度范围(恢复精度)
"""
seq_len = torch.max(position_ids) + 1 # 获取当前序列实际长度
# 处理超长序列(超过训练长度)
if seq_len > self.max_seq_len_cached:
# 重新计算动态缩放后的频率(公式θ'_m=θ_m*L_train/L_infer)
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, seq_len=seq_len)
self.register_buffer("inv_freq", inv_freq, persistent=False)
self.max_seq_len_cached = seq_len
# 处理短序列(恢复原始参数)
if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len:
self.original_inv_freq = self.original_inv_freq.to(device)
self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
self.max_seq_len_cached = self.original_max_seq_len
@torch.no_grad()
def forward(self, x, position_ids):
if "dynamic" in self.rope_type:
self._dynamic_frequency_update(position_ids, device=x.device) # 动态模式触发频率更新
# 核心RoPE计算(复数旋转编码)
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1) # [batch, dim//2, 1]
position_ids_expanded = position_ids[:, None, :].float() # [batch, 1, seq_len]
# 强制使用float32精度计算(避免MPS设备精度问题)
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
freqs = (inv_freq_expanded.to(x.device) @ position_ids_expanded).transpose(1, 2) # 矩阵乘法计算旋转角度
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # 转换为复数极坐标形式(欧拉公式)[1](@ref)
# 应用动态缩放因子(补偿超长序列的位置编码衰减)
freqs_cis = freqs_cis * self.attention_scaling
return freqs_cis
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""应用旋转位置编码到query/key向量(交错层策略核心)
参数:
xq: query向量 [batch, seq, heads, dim]
xk: key向量 [batch, seq, heads, dim]
freqs_cis: 预计算的旋转矩阵
"""
# 将向量转换为复数形式(二维平面旋转)
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)) # [..., dim//2]
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
# 复数乘法实现旋转(仅奇数层应用)
xq_out = torch.view_as_real(xq_ * freqs_cis[:, :, None, :]).flatten(3) # [batch, seq, heads, dim]
xk_out = torch.view_as_real(xk_ * freqs_cis[:, :, None, :]).flatten(3)
# 保持原始数据类型
return xq_out.type_as(xq), xk_out.type_as(xk)
长文本泛化能力
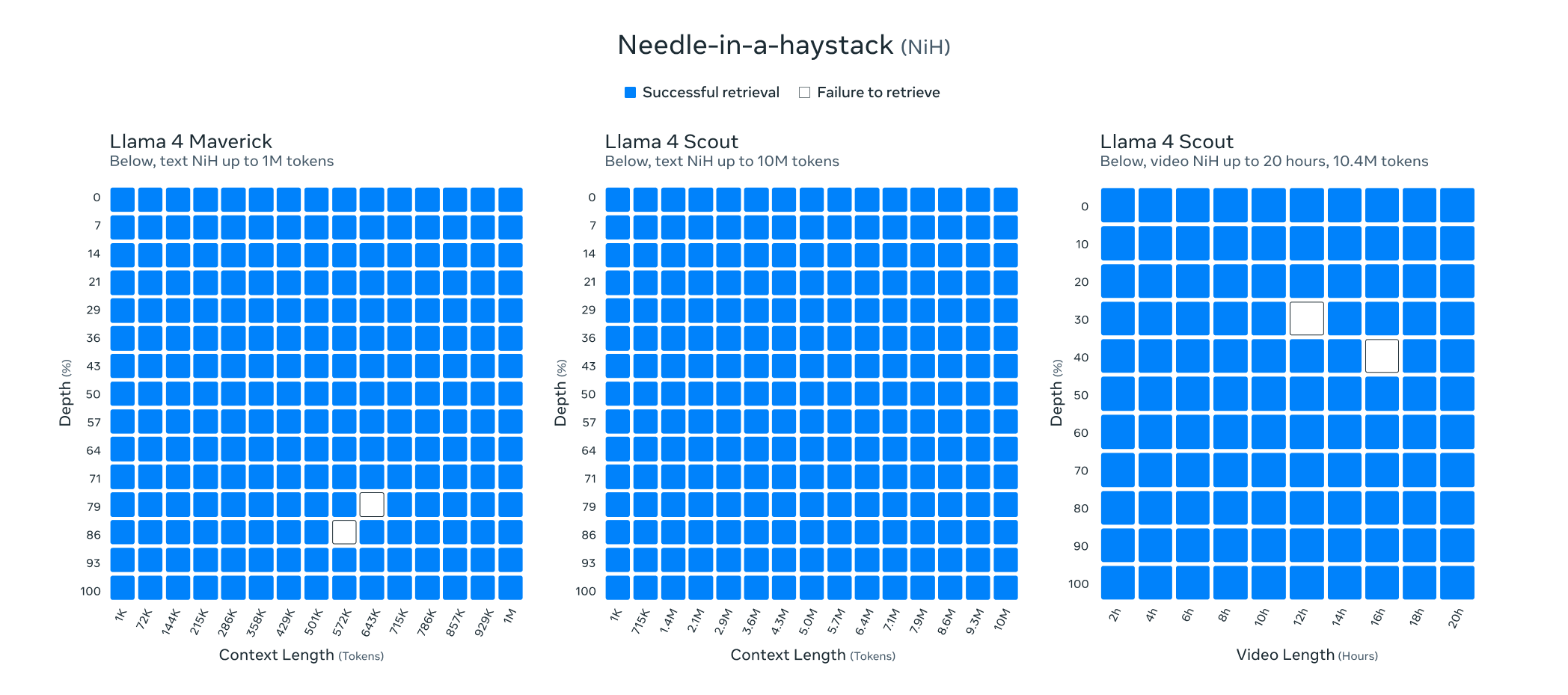
Llama 4 Scout 在预训练与后训练阶段均采用 256K 上下文长度进行优化,这一设计使基础模型具备卓越的长文本泛化能力。在以下任务中验证了其突破性表现:
-
文本检索测试
通过 “检索大海捞针”(retrieval needle in haystack) 实验,模型在超长文本中精准定位关键信息的能力达到行业标杆水平。
-
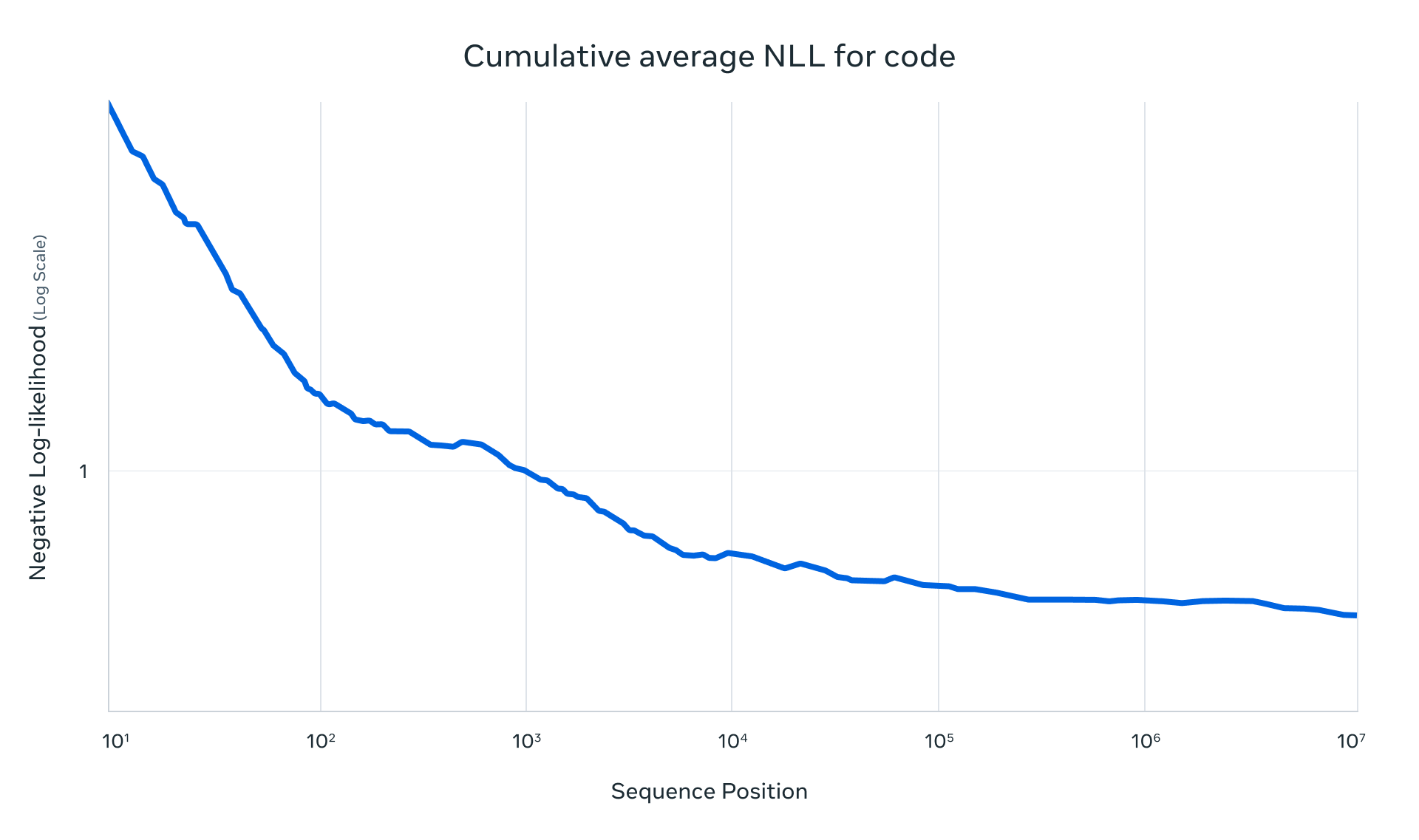
代码理解评估
基于 1000万 token 代码量 的累积负对数似然(NLLs)测试,模型展现出对超大规模代码库的连续推理与概率建模优势。
使用例子:基于图像理解的函数调用
通过transformers加载:
%pip install torch torchvision accelerate huggingface_hub hf_xet
%pip install -U transformers>=4.51.0
下载Llama-4-Scout-17B-16E-Instruct checkpoint:
import time
import torch
from transformers import AutoTokenizer, AutoProcessor, Llama4ForConditionalGeneration
model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id) # used for text-only inference
processor = AutoProcessor.from_pretrained(model_id) # used for multimodal inference
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
attn_implementation="sdpa",
device_map="auto",
torch_dtype=torch.bfloat16,
)
基于图像理解的函数调用:
可选择在functions_prompt或system prompt中传入函数定义这两种方式,让llama4理解输入的图片内容后,选择合适的函数调用,比如预定旅游票、查询天气。
functions_prompt = """
You have access to the following functions:
1. **Book Travel Tickets**: Use this function to assist users in booking travel tickets.
`{ "name": "book_travel_tickets", "description": "Books travel tickets for the user", "parameters": { "destination": {"description": "The destination of the travel", "param_type": "str", "required": true}, "travel_dates": {"description": "The dates of travel", "param_type": "str", "required": true}, "number_of_passengers": {"description": "The number of passengers", "param_type": "int", "required": true}, "travel_class": {"description": "The preferred travel class (e.g., economy, business)", "param_type": "str", "required": false} } }`
2. **Check Weather**: Use this function to provide current weather information for a specified location.
`{ "name": "check_weather", "description": "Checks the current weather for a specified location", "parameters": { "location": {"description": "The location to check the weather for", "param_type": "str", "required": true} } }`
Think very carefully before calling functions. If you choose to call a function, ONLY reply in the following format with no prefix or suffix:
<function=example\_function\_name>{"example\_name": "example\_value"}</function>
Reminder:
* Function calls MUST follow the specified format, start with <function= and end with </function>
* Required parameters MUST be specified
* Only call one function at a time
* Put the entire function call reply on one line"""
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": resized_imgs[0]},
{"type": "image", "url": resized_imgs[1]},
{"type": "text", "text": f"{functions_prompt}\n\nBook me tickets to go the place shown in these photos"}
]
}
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0]
print(response)
REF
https://ai.meta.com/blog/llama-4-multimodal-intelligence/
模型下载地址:https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164
getting started: https://github.com/meta-llama/llama-cookbook/blob/main/getting-started/build_with_llama_4.ipynb
llama4 model card: https://github.com/meta-llama/llama-models/blob/main/models/llama4/MODEL_CARD.md
提示词格式:https://www.llama.com/docs/model-cards-and-prompt-formats/llama4_omni/
Demystifying CLIP Data(MetaCLIP):https://github.com/facebookresearch/MetaCLIP
https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama4/modeling_llama4.py#L61

















 197
197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









