






近年来,大型语言模型Large Language Models(LLM)的研究取得了显著的进展(例如GPT-3,LLaMa,ChatGPT,GPT-4),这些模型在各项自然语言处理(NLP)任务上展现了出色的性能。
通过在海量数据上预训练,LLM获得了丰富的知识以及强大的推理能力。只需要输入一些用户指令,这些模型就可以解析指令、进行推理并给出符合用户预期的回答。这些能力背后蕴含着众多关键思想和技术,包括指令微调(Instruction Tuning),上下文学习(In-Context Learning)和思维链(Chain of Thought)等,以及多模态。
一、什么是多模态
多模态人工智能利用来自多个不同模态(如文本、图像、声音、视频等)的数据进行学习和推理。多模态人工智能强调不同模态数据之间的互补性和融合性,通过整合多种模态的数据,利用表征学习、模态融合与对齐等技术,实现跨模态的感知、理解和生成,推动智能应用的全面发展。
接下来分三部分:_数据采集与表示、数据处理与融合、学习与推理,一起来科普下多模型的基本术语。
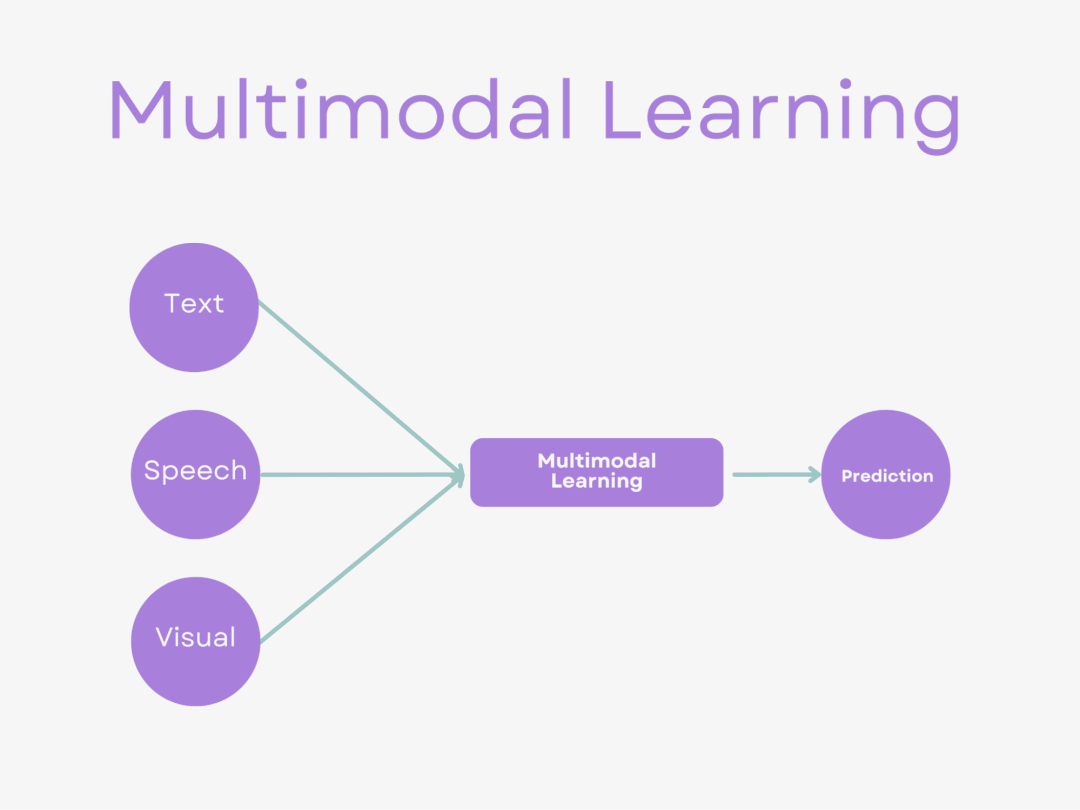
多模态学习(Multimodal Learning)是一种利用来自不同感官或交互方式的数据进行学习的方法,这些数据模态可能包括文本、图像、音频、视频等。多模态学习通过融合多种数据模态来训练模型,从而提高模型的感知与理解能力,实现跨模态的信息交互与融合。接下来分三部分:模态表示、多模态融合、跨模态对齐,一起来总结下多模型的核心。
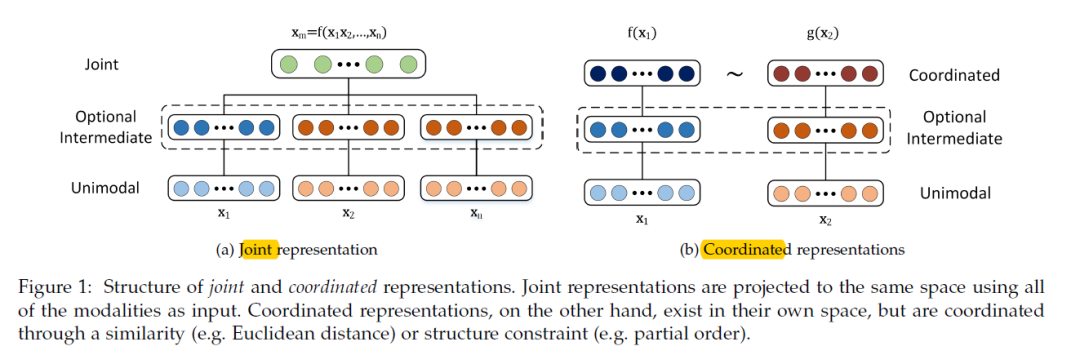
什么是多模态协同表示(Coordinated Representation)?多模态协同表示是一种将多个模态的信息分别映射到各自的表示空间,但映射后的向量或表示之间需要满足一定的相关性或约束条件的方法。这种方法的核心在于确保不同模态之间的信息在协同空间内能够相互协作,共同优化模型的性能。
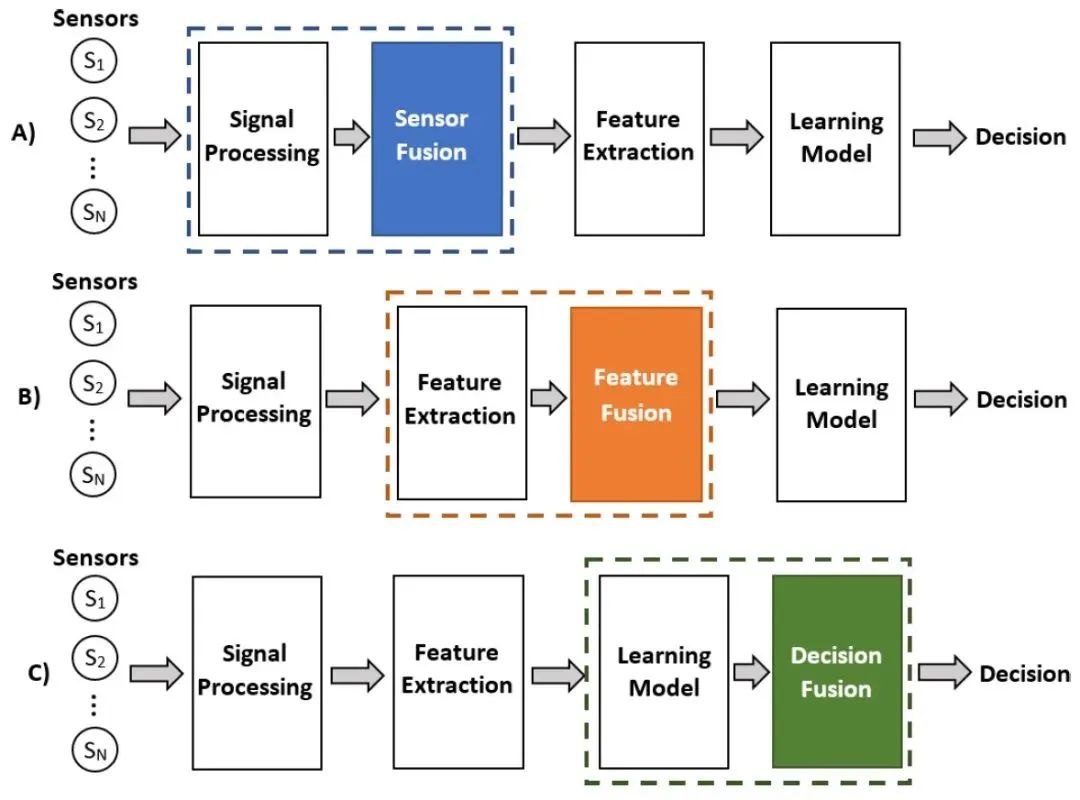
二、什么是多模态融合
什么是多模态融合(MultiModal Fusion)?多模态融合能够充分利用不同模态之间的互补性,它将抽取自不同模态的信息整合成一个稳定的多模态表征。从数据处理的层次角度将多模态融合分为数据级融合、特征级融合和目标级融合。
多模态融合
- 数据级融合(Data-Level Fusion):
-
数据级融合,也称为像素级融合或原始数据融合,是在最底层的数据级别上进行融合。这种融合方式通常发生在数据预处理阶段,即将来自不同模态的原始数据直接合并或叠加在一起,形成一个新的数据集。
-
应用场景:适用于那些原始数据之间具有高度相关性和互补性的情况,如图像和深度图的融合。
- 特征级融合(Feature-Level Fusion):
-
特征级融合是在特征提取之后、决策之前进行的融合。不同模态的数据首先被分别处理,提取出各自的特征表示,然后将这些特征表示在某一特征层上进行融合。
-
应用场景:广泛应用于图像分类、语音识别、情感分析等多模态任务中。
- 目标级融合(Decision-Level Fusion):
-
目标级融合,也称为决策级融合或后期融合,是在各个单模态模型分别做出决策之后进行的融合。每个模态的模型首先独立地处理数据并给出自己的预测结果(如分类标签、回归值等),然后将这些预测结果进行整合以得到最终的决策结果。
-
应用场景:适用于那些需要综合考虑多个独立模型预测结果的场景,如多传感器数据融合、多专家意见综合等。
三、什么是多模态对齐
什么是跨模态对齐(MultiModal Alignment)?跨模态对齐是通过各种技术手段,实现不同模态数据(如图像、文本、音频等)在特征、语义或表示层面上的匹配与对应。跨模态对齐主要分为两大类:显式对齐和隐式对齐。

什么是显示对齐(Explicit Alignment)?直接建立不同模态之间的对应关系,包括无监督对齐和监督对齐。
- 无监督对齐:利用数据本身的统计特性或结构信息,无需额外标签,自动发现不同模态间的对应关系。
-
CCA(典型相关分析):通过最大化两组变量之间的相关性来发现它们之间的线性关系,常用于图像和文本的无监督对齐。
-
自编码器:通过编码-解码结构学习数据的低维表示,有时结合循环一致性损失(Cycle Consistency Loss)来实现无监督的图像-文本对齐。
- 监督对齐:利用额外的标签或监督信息指导对齐过程,确保对齐的准确性。
-
多模态嵌入模型:如DeViSE(Deep Visual-Semantic Embeddings),通过最大化图像和对应文本标签在嵌入空间中的相似度来实现监督对齐。
-
多任务学习模型:同时学习图像分类和文本生成任务,利用共享层或联合损失函数来促进图像和文本之间的监督对齐。
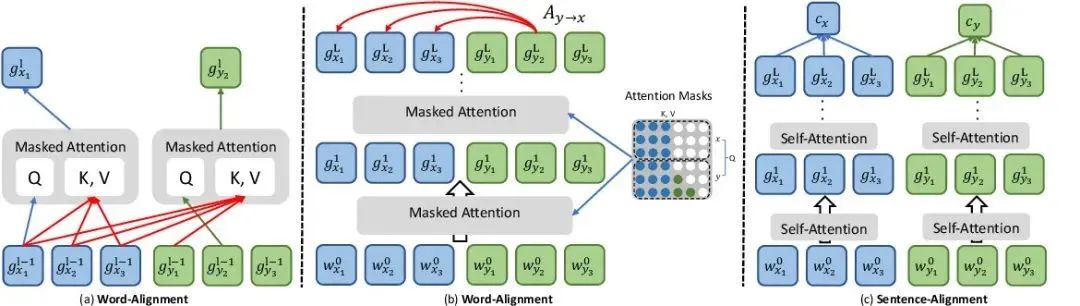
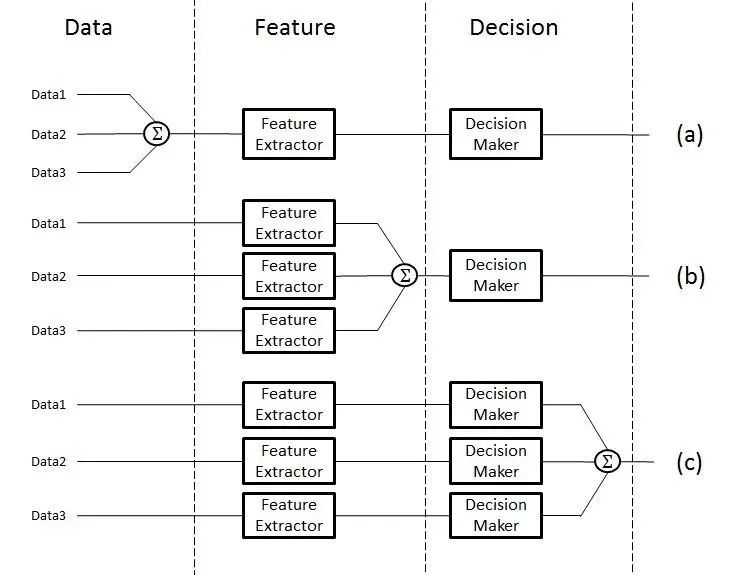
什么是隐式对齐(Implicit Alignment)?不直接建立对应关系,而是通过模型内部机制隐式地实现跨模态的对齐。这包括注意力对齐和语义对齐。
**注意力对齐:**通过注意力机制动态地生成不同模态之间的权重向量,实现跨模态信息的加权融合和对齐。Transformer模型:在跨模态任务中(如图像描述生成),利用自注意力机制和编码器-解码器结构,自动学习图像和文本之间的注意力分布,实现隐式对齐。BERT-based模型:在问答系统或文本-图像检索中,结合BERT的预训练表示和注意力机制,隐式地对齐文本查询和图像内容。
**语义对齐:**在语义层面上实现不同模态之间的对齐,需要深入理解数据的潜在语义联系。图神经网络(GNN):在构建图像和文本之间的语义图时,利用GNN学习节点(模态数据)之间的语义关系,实现隐式的语义对齐。预训练语言模型与视觉模型结合:如CLIP(Contrastive Language-Image Pre-training),通过对比学习在大量图像-文本对上训练,使模型学习到图像和文本在语义层面上的对应关系,实现高效的隐式语义对齐。
四、多模特LLM示例
Flamingo是2022年推出的多模态大语言模型。视觉和语言组件的工作原理如下:
视觉编码器将图像或视频转换为嵌入(数字列表)。这些嵌入的大小取决于输入图像的尺寸或输入视频的长度,因此另一个称为感知器重采样器的组件将这些嵌入转换为通用的固定长度。
语言模型接收文本和来自 Percever Resampler 的固定长度视觉嵌入。视觉嵌入用于多个“交叉注意力”块,这些块学习根据当前文本权衡视觉嵌入不同部分的重要性。
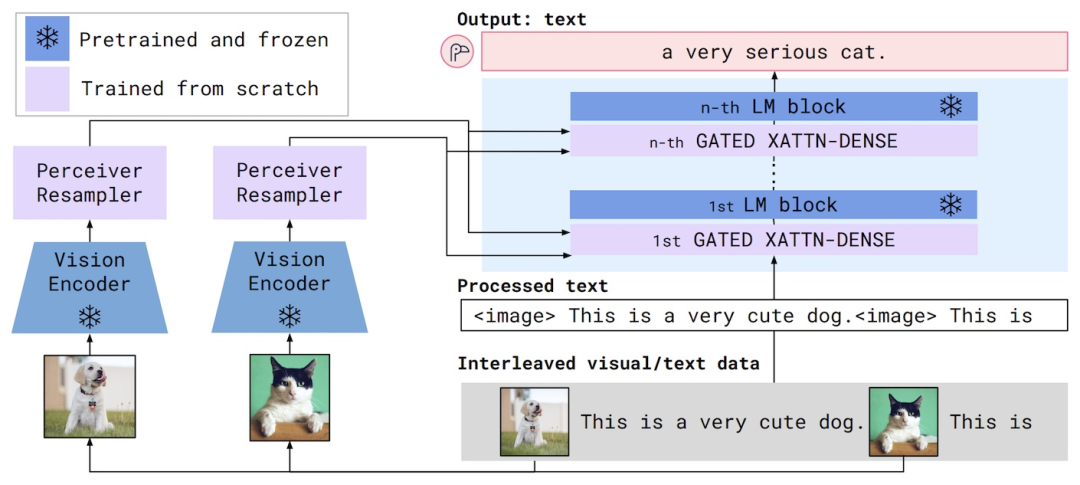 图 1 来自 Flamingo 论文,展示了模型架构。
图 1 来自 Flamingo 论文,展示了模型架构。
训练分为三个步骤:
-
视觉编码器使用 CLIP 进行预训练。CLIP 实际上同时训练视觉编码器和文本编码器,因此此步骤中的文本编码器将被丢弃。
-
该语言模型是一个预先训练了下一个标记预测的Chinchilla模型,即根据一系列先前的字符预测下一组字符。大多数 LLM(如 GPT-4)都是这样训练的。您可能会听到这种类型的模型被称为“自回归”,这意味着该模型根据过去的值预测未来的值。
-
在第三阶段,将未经训练的交叉注意力模块插入语言模型中,并在视觉编码器和语言模型之间插入未经训练的感知器重采样器。这是完整的 Flamingo 模型,但交叉注意力模块和感知器重采样器仍需要训练。为此,整个 Flamingo 模型用于计算下一个标记预测任务中的标记,但输入现在包含与文本交错的图像。此外,视觉编码器和语言模型的权重被冻结。换句话说,只有感知器重采样器和交叉注意力模块实际上得到更新和训练。
经过训练,Flamingo 能够执行各种视觉语言任务,包括以对话形式回答有关图像的问题。

图 2 取自 Flamingo 论文,展示了视觉对话的示例。
Flamingo 论文:
https://arxiv.org/pdf/2204.14198
BLIP-2是一款多模态 LLM,于 2023 年初发布。与 Flamingo 一样,它包含预训练的图像编码器和 LLM。但与 Flamingo 不同的是,图像编码器和LLM 均未受影响(预训练后)。
为了将图像编码器连接到 LLM,BLIP-2 使用“Q-Former”,它由两个组件组成:
-
视觉组件接收一组可学习的嵌入和冻结图像编码器的输出。与 Flamingo 中所做的一样,图像嵌入被输入到交叉注意层中。
-
文本组件接收文本。
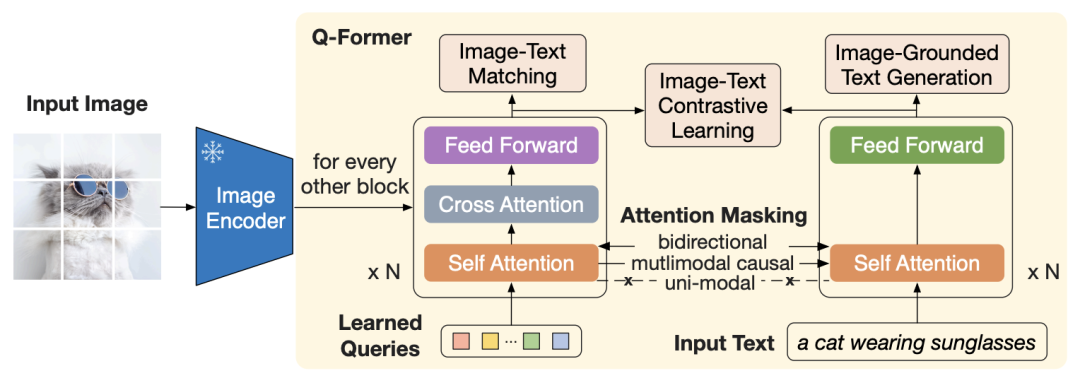
图摘自 BLIP-2 论文,展示了 Q-Former 的内部结构及其训练目标。
BLIP-2 训练分为两个阶段:
-
在第 1 阶段,Q-Former 的两个组件针对三个目标进行训练,这些目标实际上源自BLIP-1论文:
-
图像-文本对比学习(类似于 CLIP,但有一些细微的差别)。
-
基于图像的文本生成(生成图像的标题)。
-
图像-文本匹配(二元分类任务,其中对于每个图像-文本对,模型必须回答 1 来表示匹配,否则回答 0)。
-
在第 2 阶段,通过在 Q-Former 和 LLM 之间插入投影层来构建完整模型。此投影层将 Q-Former 的嵌入转换为具有与 LLM 兼容的长度。然后,完整模型负责描述输入图像。在此阶段,图像编码器和 LLM 保持冻结状态,并且仅训练 Q-Former 和投影层。

图 3 摘自 BLIP-2 论文,展示了完整的模型架构。投影层标记为“完全连接”。
在论文的实验中,他们使用 CLIP 预训练图像编码器和OPT或Flan-T5作为 LLM。实验表明,BLIP-2 在各种视觉问答任务上的表现都优于 Flamingo,但可训练参数却少得多。这使得训练过程更加轻松,且更具成本效益。
BLIP-2 论文 :
https://arxiv.org/pdf/2301.12597
LLaVA是一种多模态 LLM,于 2023 年发布。其架构非常简单:
-
视觉编码器使用 CLIP 进行预训练。
-
LLM 是经过预先训练的Vicuna模型。
-
视觉编码器通过单个投影层连接到 LLM。
请注意视觉编码器和 LLM 之间的组件的简单性,与 BLIP-2 中的 Q-Former 以及 Flamingo 中的感知器重采样器和交叉注意层相比。
训练分为两个阶段:
-
在第 1 阶段,训练目标是图像字幕。视觉编码器和 LLM 被冻结,因此只训练投影层。
-
在第 2 阶段,LLM 和投影层在部分合成的指令跟踪数据集上进行微调。它是部分合成的,因为它是在 GPT-4 的帮助下生成的。
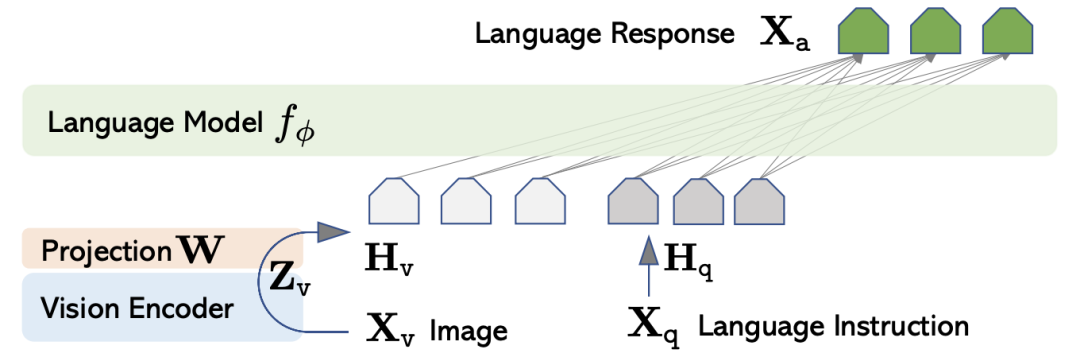
图 1 来自 LLaVA 论文,展示了完整的模型架构。
作者对 LLaVA 的评价如下:
-
他们使用 GPT-4 来评估 LLaVA 在部分合成数据集上的响应质量。在这里,LLaVA 相对于 GPT-4 的得分为 85%。
-
他们在名为 ScienceQA 的视觉问答数据集上使用标准评估指标。在这里,经过微调的 LLaVA 表现优于 GPT-4。
LLaVA 说明,简单架构在使用部分合成数据进行训练可取得优异结果。LLaVA论文:https://arxiv.org/pdf/2304.08485
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









