






一、研究背景与意义
混合专家模型(Mixture of Experts, MoE)作为一种新兴的大规模语言模型架构,通过条件计算机制显著提升了模型容量和计算效率。近期,以Mixtral-8x7B、Gemini、DeepSeek-MoE等为代表的MoE模型展现出了强大的性能。然而,MoE模型的部署和推理过程中面临着计算资源需求大、延迟高、能源效率低等挑战,这促使学术界和工业界对MoE推理优化技术进行深入研究。
二、MoE模型基础架构
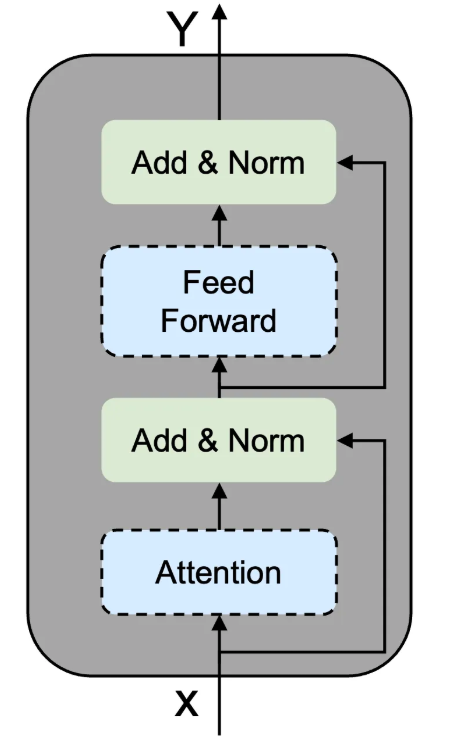
MoE模型的核心架构包含路由网络R(x)和N个专家网络{E1,E2,…,EN}。其基本工作原理可表示为:
y = ∑(i=1 to N) gi(x)·Ei(x)
其中gi(x)为专家i的门控函数,Ei(x)为专家i的输出。
MoE模型的推理过程主要包含三个阶段:
- 路由计算:通过路由器计算专家选择概率
- 专家选择:基于概率选择Top-K个专家
- 并行计算:选中的专家并行处理输入并聚合结果
三、多层次优化框架
本文提出了一个系统的分类框架,将MoE推理优化技术分为三个层次:
1. 模型层优化
1.1 架构设计优化
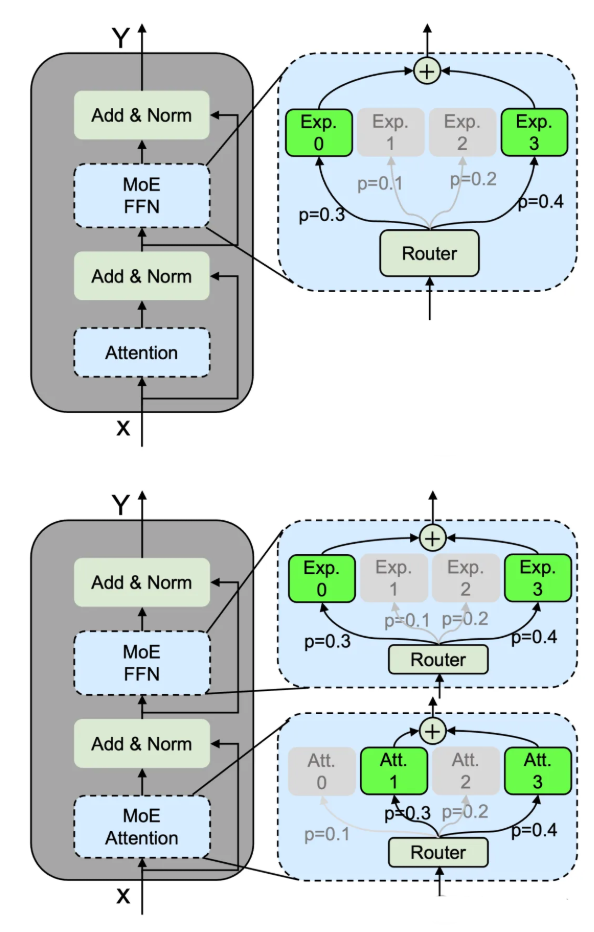
- 注意力机制优化:MoH、JetMoE等通过稀疏注意力提升效率
- FFN结构优化:MoE++引入零计算专家,SCoMoE优化通信开销
- 专家设计优化:Pre-gated MoE提出预门控机制
1.2 模型压缩技术
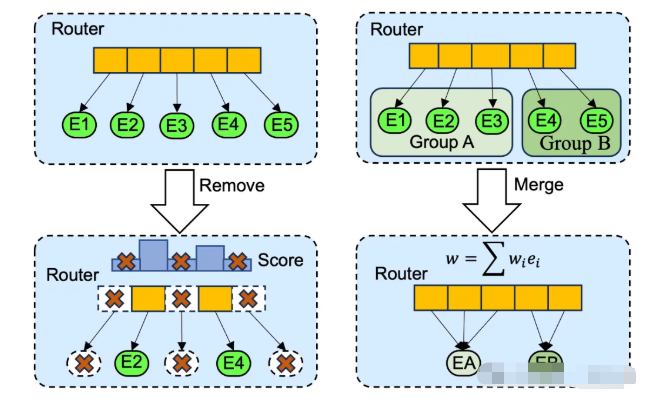
- 专家剪枝:TSEP、NAEE等方法去除冗余专家
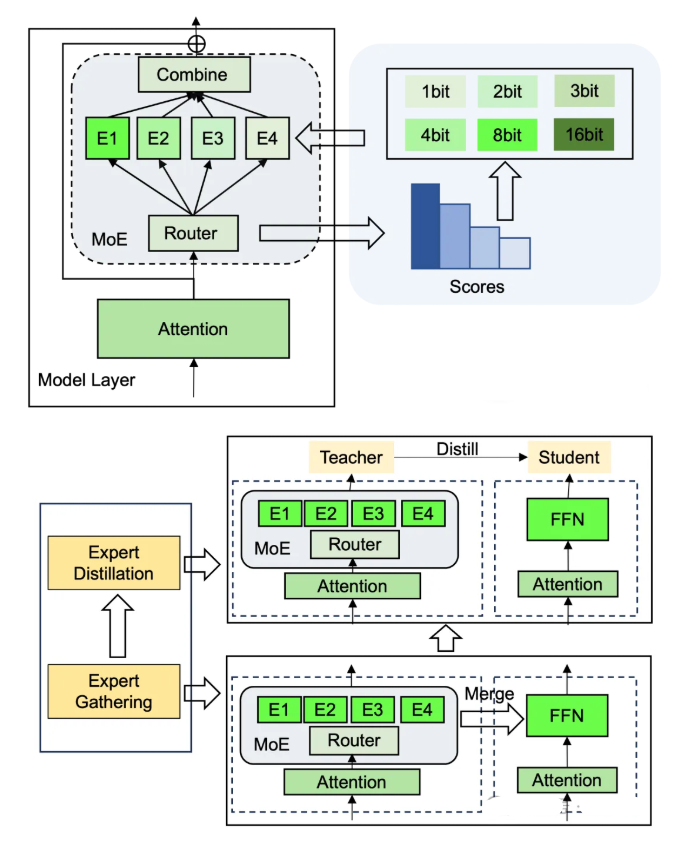
- 专家量化:MC-MoE、QMoE实现低比特量化
- 知识蒸馏:LLaVA-MoD、MoE-KD压缩模型规模
- 低秩分解:MPOE采用矩阵乘积算子进行分解
1.3 算法优化
- 动态门控:AdapMoE等实现自适应专家激活
- 专家合并:FoE、MEO提出高效合并策略
- 稀疏到密集转换:XFT等实现模型结构转换
2. 系统层优化
2.1 专家并行
- 并行策略设计:结合数据、张量、专家并行
- 负载均衡:优化专家分配和放置策略
- 通信优化:减少All-to-All通信开销
- 任务调度:实现计算通信重叠
2.2 专家卸载
- 专家预取:HOBBIT等预测并预加载专家
- 专家缓存:设计高效缓存替换策略
- 专家加载:EdgeMoE等优化加载机制
- CPU辅助:利用CPU-GPU协同计算
3. 硬件层优化
- MoNDE:基于近数据处理的加速方案
- FLAME:面向FPGA的稀疏计算优化
- Duplex:集成xPU和逻辑PIM的协同设计
- Space-mate:面向移动设备的加速器设计
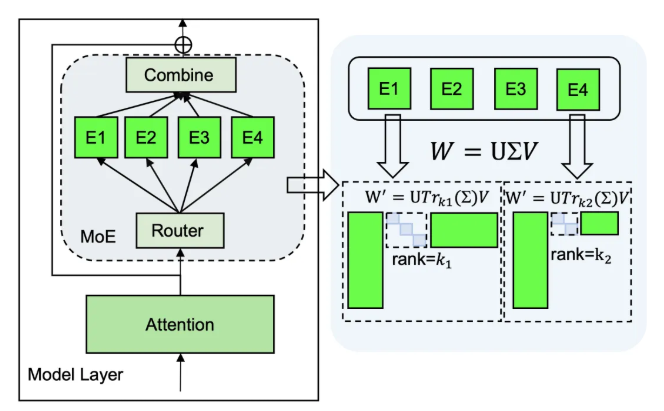
四、关键技术创新
模型结构优化
- 提出混合注意力机制,实现计算和通信的平衡
- 设计零计算专家,降低推理开销
- 引入预门控机制,提前确定所需专家
压缩加速技术
- 结合结构化和非结构化剪枝
- 实现动态混合精度量化
- 采用多阶段知识蒸馏
系统优化方案
- 多维度并行策略组合
- 分层通信机制设计
- 智能预取和缓存管理
硬件协同设计
- 近数据处理架构
- 异构计算单元集成
- 专用加速电路设计
五、未来研究方向
1. 计算基础设施优化
1.1 硬件集成与加速
- 开发专用电路支持专家路由和激活
- 优化针对稀疏访问的内存层次
- 设计高效的动态工作负载处理机制
1.2 系统软件优化
- 改进虚拟内存管理以支持动态专家激活
- 开发智能资源分配和调度策略
- 实现硬件软件协同设计
2. 系统需求与挑战
2.1 能效与可持续性
- 考虑能耗和碳排放作为优化目标
- 开发碳感知部署策略
- 建立全面的能耗评估框架
2.2 延迟与服务质量
- 提高专家激活和路由的可预测性
- 增强分布式系统的可靠性
- 实现优雅的性能降级机制
3. 开发支持生态
3.1 开源框架
- 增强框架对MoE的原生支持
- 开发高层API和抽象
- 实现与现有ML生态的集成
3.2 基准测试与标准化
- 建立统一的评测框架
- 开发标准测试集
- 制定一致的评估方法
六、总结与展望
本文系统地分析了MoE推理优化技术的现状,提出了一个多层次的分类框架,涵盖了从模型设计到硬件加速的各个层面。通过详细梳理现有方法,发现当前研究主要集中在以下几个方向:
- 模型层面:通过改进模型结构、压缩技术和算法优化来提升效率
- 系统层面:着重解决分布式部署和资源受限场景下的优化问题
- 硬件层面:探索专用加速器和异构计算方案
未来的研究方向主要包括:
- 计算基础设施的进一步优化
- 能效和服务质量的平衡
- 开发支持生态的完善
随着MoE模型在大规模语言模型和多模态系统中的广泛应用,推理优化技术将继续演进。关键挑战包括专用硬件架构的开发、更高效的专家路由算法以及改进的分布式部署方案。这些挑战的解决将推动MoE模型在实际应用中发挥更大的价值。
论文地址: https://arxiv.org/abs/2412.14219
项目地址: https://github.com/MoE-Inf/awesome-moe-inference/
七、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 2488
2488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









