







 本文详细介绍了SSD(Single Shot MultiBox Detector)算法,包括其多尺度特征图、先验框设置和网络结构,并对比了YOLO。此外,还探讨了SSD的训练过程、损失函数和数据扩增策略。接着,文章介绍了DSSD,它通过ResNet和反卷积层增强浅层特征,提高了小目标检测的准确性。DSSD在网络结构上进行了优化,如使用跳跃连接和改进的预测模块。最后,讨论了SSD和DSSD的性能评估及优缺点。
本文详细介绍了SSD(Single Shot MultiBox Detector)算法,包括其多尺度特征图、先验框设置和网络结构,并对比了YOLO。此外,还探讨了SSD的训练过程、损失函数和数据扩增策略。接着,文章介绍了DSSD,它通过ResNet和反卷积层增强浅层特征,提高了小目标检测的准确性。DSSD在网络结构上进行了优化,如使用跳跃连接和改进的预测模块。最后,讨论了SSD和DSSD的性能评估及优缺点。
SSD(Single Shot MultiBox Detector)
特点:多尺度特征图用于检测;采用了先验框,,SDD backbone采用VGG-16
SSD和YOLO一样都是采用一个CNN网络进行检测,但是采用了多尺度的特征图,如下图所示:
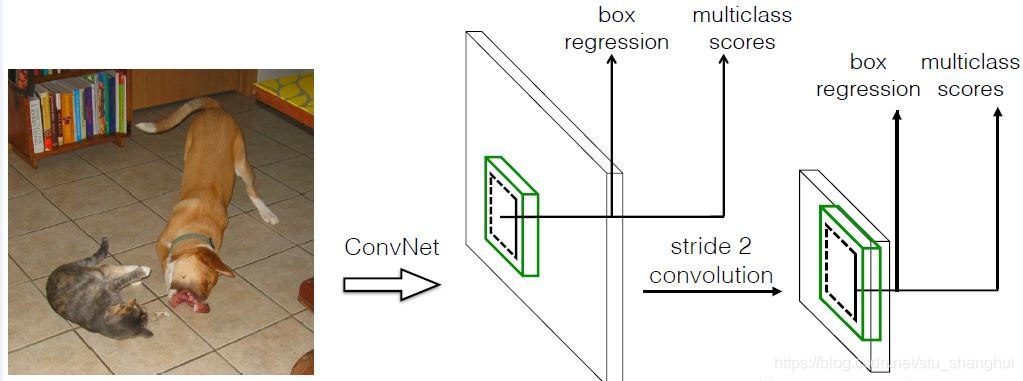
采用多尺度特征图用于检测
采用步长stride=2的卷积或者pool来降低特征图的大小,比较大的特征图用来检测小目标,比较小的特征图用来检测大目标
采用卷积进行检测
YOLO最后采用全连接,而SSD直接采用卷积对不同的特征图进行提取特征。对于形状为m×n×p特征图,只需要采用3×3×p这样比较小的卷积核得到检测值。
设置先验框
YOLO中每个单元预测多个边界框,但是都是相对于这个单元本身的,YOLO需要在训练过程中自适应目标的形状。SSD借鉴了Faster-RCNN的anchor理念,每个单元设置尺度或者长宽比不同的先验框,文中每个单元设置了4个先验框
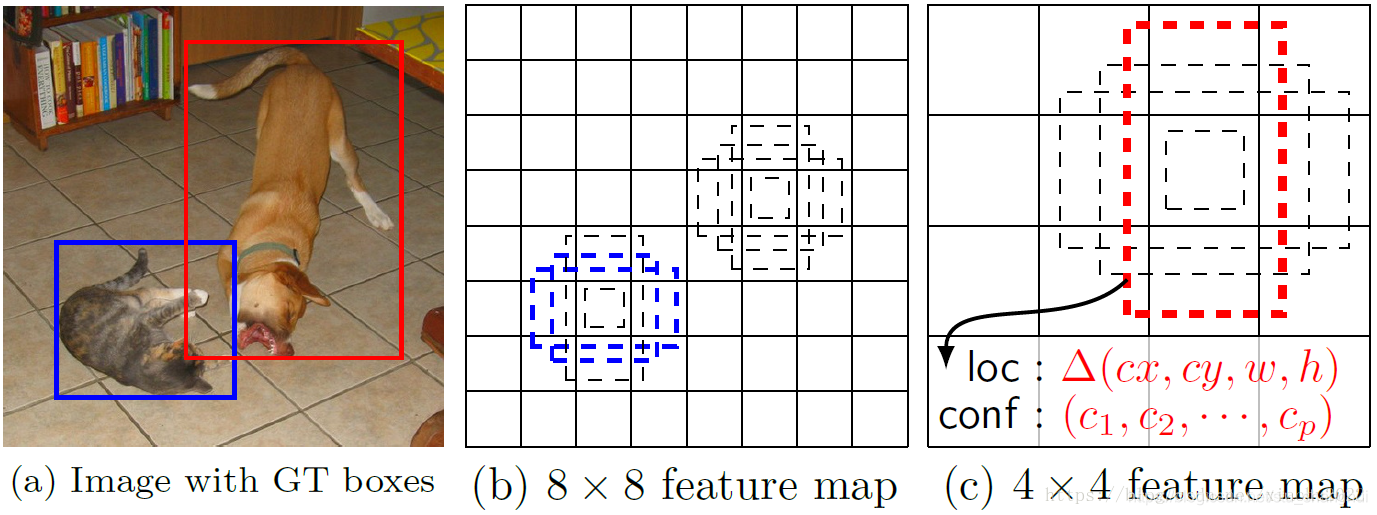
SSD的检测值与YOLO也不一样
对每一个单元,SSD都输出一套独立的检测值,对应一个边界框。检测值主要分为两部分:
- 第一部分是各个类别的置信度或者评分(注意:SSD将背景也当做一个特殊的类别,所有检测类别是C+1,第一个类别是是否有背景,这个置信度最高时就表示不含有目标)
- 第二部分是边界框的location,包含(cx,cy,w,h),真实预测值只是边界框相对于先验框的转换值。先验框位置用d=(dcx,dcy,dw,dh)表示,对应的边界框用b=(bcx,bcy,bw,bh)表示,那么边界框的预测值L其实是b相对于d的转换值:(边界框的编码过程)
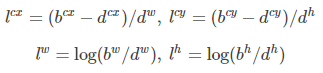
预测时框的反向这个过程,就是进行边界解码
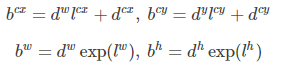
所以对于一个m*n大小的特征图,每个单元设置K个先验框,每个单元就需要(C+4)*k个预测值,一共需要(c+4)*k*m*n个预测值,所以就需要(k+4)*k个卷积核完成这个特征图的检测过程
网络结构
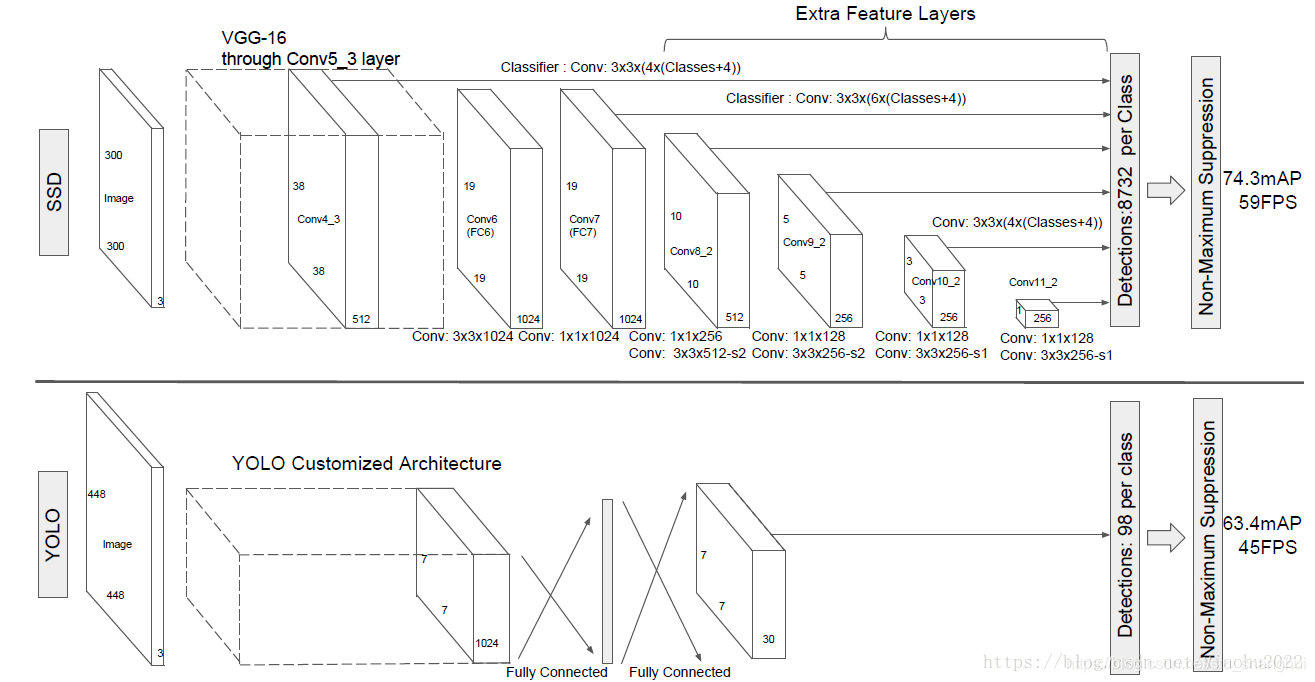
图片来源:https://blog.csdn.net/xiaohu2022
1.模型的输入是300*300,SDD backbone采用VGG-16,在其基础上增加新的卷积层获得更多的特征图用于检测
- 将VGG16的全连接层fc6和fc7转换成3*3的卷积层conv6和1*1卷积层conv7
- 将池化层pool5由原来的2*2-s2变成3*3-s1
- Conv6采用扩展卷积或带孔卷积(dilation conv), 卷积核大小是3*3,dilation rate=6
- 移除dropout和fc8
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









