







 文章介绍了一种新型模型EfficientViT-SAM,它通过使用EfficientViT替换SAM的图像编码器,实现了在保持性能的同时大幅降低计算成本。EfficientViT-SAM在COCO数据集上表现出色,与先前模型相比,如SAM-ViT-H,其吞吐量显著提升,且在零样本基准测试中达到SOTA性能与效率平衡。
文章介绍了一种新型模型EfficientViT-SAM,它通过使用EfficientViT替换SAM的图像编码器,实现了在保持性能的同时大幅降低计算成本。EfficientViT-SAM在COCO数据集上表现出色,与先前模型相比,如SAM-ViT-H,其吞吐量显著提升,且在零样本基准测试中达到SOTA性能与效率平衡。
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2024年2月7日
论文:
https://arxiv.org/abs/2402.05008 https://arxiv.org/abs/2402.05008代码:
https://arxiv.org/abs/2402.05008代码:
mit-han-lab/efficientvit: EfficientViT is a new family of vision models for efficient high-resolution vision. (github.com)https://github.com/mit-han-lab/efficientvit
2. 摘要
EfficientViT-SAM在保留SAM轻量级的提示编码器和Mask解码器的同时,用EfficientViT替换了沉重的图像编码器。
训练过程包括两个阶段:首先,作者使用SAM的图像编码器作为教师来训练EfficientViT-SAM的图像编码器;其次,作者使用整个SA-1B数据集端到端地训练EfficientViT-SAM。
实验中全面评估了EfficientViT-SAM在一系列零样本基准测试上的表现。EfficientViT-SAM在性能和效率上显著优于所有之前的SAM模型。特别是,在COCO数据集上,与SAM-ViT-H相比,EfficientViT-SAM在A100 GPU上实现了48.9倍的吞吐量提升,而mAP没有下降。
3. 前言
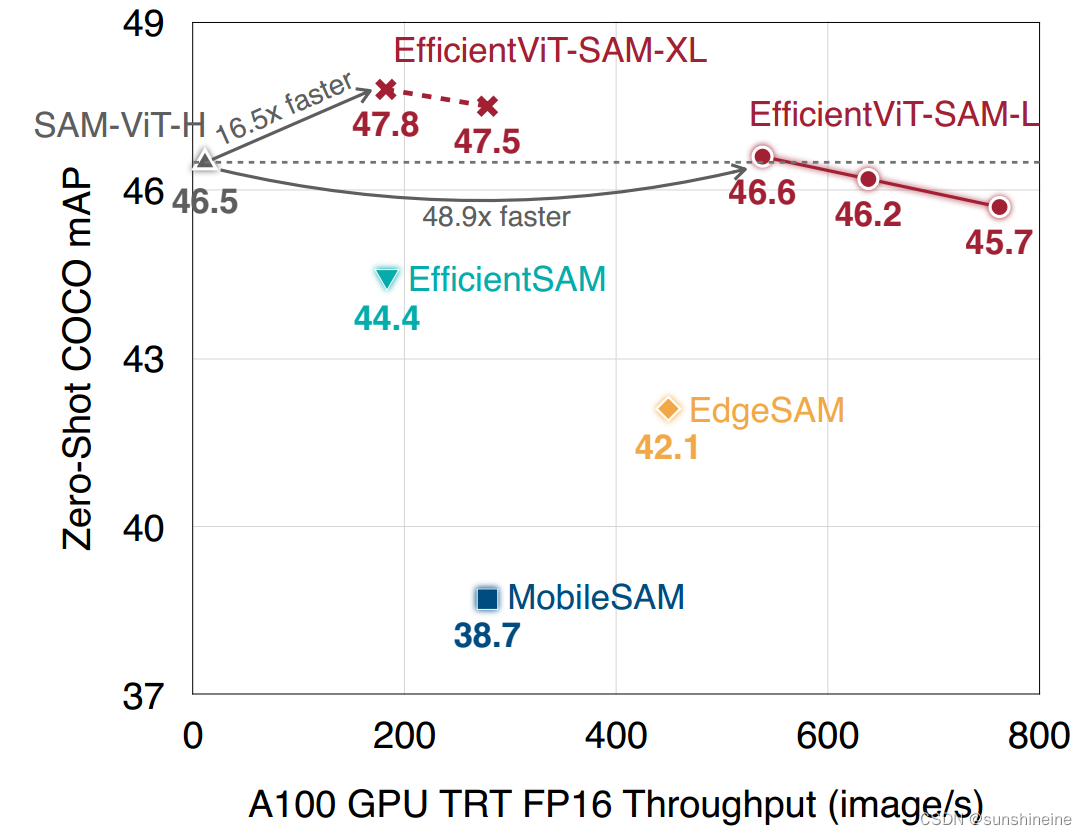
SAM是在高质量数据集上预训练的图像分割模型,尽管性能强大,但SAM的计算量非常大,特别是其图像编码器,在推理时每张图像需要2973 GMACs。为了加速SAM,已经进行了许多尝试,用轻量级模型替换SAM的图像编码器。例如,MobileSAM 将SAM的ViT-H模型的知识蒸馏到一个小型视觉 Transformer 中。EdgeSAM 训练了一个纯基于CNN的模型来模仿ViT-H,并采用了一种细致的蒸馏策略,过程中涉及到提示编码器和 Mask 解码器。EfficientSAM 利用MAE预训练方法来提高性能。尽管这些方法可以降低计算成本,但它们都存在显著的性能下降。本文引入了EfficientViT-SAM来解决这一限制。如下图所示,为各轻量化SAM模型在吞吐量与COCO零射击实例分割mAP上的比较。EfficientViT-SAM实现了SOTA性能效率的权衡。
二、模型结构
EfficientViT-SAM保留了SAM的提示编码器和Mask解码器架构,同时用EfficientViT替换了图像编码器。作者设计了两系列模型,EfficientViT-SAM-L和EfficientViT-SAM-XL,它们在速度和性能之间提供了平衡。随后,作者以端到端的方式使用SA-1B数据集来训练EfficientViT-SAM。
1. EfficientViT
EfficientViT 是用于高效高分辨率密集预测的视觉 Transformer 模型。其核心构建模块是一个多尺度线性注意力模块,它通过硬件高效的运算实现了全局感受野和多尺度学习。具体来说,它用轻量级的ReLU线性注意力替代了效率低下的softmax注意力,以拥有全局感受野。通过利用矩阵乘法的结合性质,ReLU线性注意力可以在保持功能的同时,将计算复杂度从二次降低到一次。此外,它还通过卷积增强了ReLU线性注意力,以减轻其在局部特征提取上的局限性。
2. EfficientViT-SAM
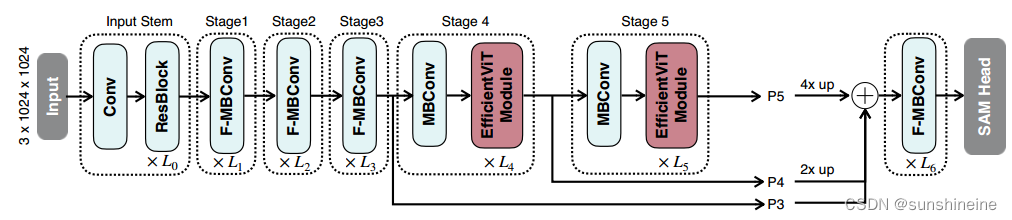
EfficientViT-SAM-XL的宏观架构如下图所示。其主干包含五个阶段。类似于EfficientViT,作者在早期阶段使用卷积块,ResBlock指的是来自ResNet34的基本构建块,而在最后两个阶段使用efficientViT模块。作者通过上采样和加法融合最后三个阶段的特征。融合后的特征被送入由几个融合的MBConv块组成的Neck,然后送入SAM Head。
3. 训练
为了初始化图像编码器,作者首先将SAM-ViT-H的图像嵌入信息蒸馏到EfficientViT中。作者采用L2损失作为损失函数。对于提示编码器和Mask解码器,作者通过加载SAM-ViT-H的权重来初始化它们。然后,作者以端到端的方式在SA-1B数据集上训练EfficientViT-SAM。
在端到端的训练阶段,作者以相等的概率随机选择框提示和点提示。在点提示的情况下,作者从真实Mask中随机选择1-10个前景点,以确保作者的模型能够有效应对各种点配置。在框提示的情况下,作者使用真实边界框。对于EfficientViT-SAM-L/XL模型,作者将最长边调整至512/1024,并相应地填充较短边。作者每张图像选择多达64个随机采样的Mask。
为了监督训练过程,作者使用Focal Loss和骰子损失的线性组合,Focal Loss与骰子损失的比例为20:1。类似于SAM中采用的消除歧义的方法,作者同时预测三个 Mask ,并且只反向传播损失最低的那个。作者还通过添加第四个输出Token来支持单一 Mask 的输出。在训练期间,作者随机交替使用两种预测模式。
作者使用SA-1B数据集对EfficientViT-SAM进行了2个周期的训练,批量大小为256。采用AdamW优化器,动量参数设为0.9,
设为0.999。初始学习率对于EfficientViT-SAM-L/XL分别设定为
/
,并使用余弦衰减学习率计划将其降低至0。在数据增强方面,作者应用了随机水平翻转。
三、实验
在本节中,首先在3.1节中对EfficientViT-SAM的运行时效率进行全面分析。随后,在训练过程中没有遇到的COCO和LVIS数据集上评估了EfficientViT-SAM的零射击能力。作者执行两个不同的任务:第3.2节中的零射击点提示分割以及3.3节中的零射击框提示分割。这些任务分别评估了EfficientViT-SAM的点提示和边界框提示特征的有效性。此外,作者在3.4节还提供了SGlnW基准测试的结果。
3.1 运行时的效率
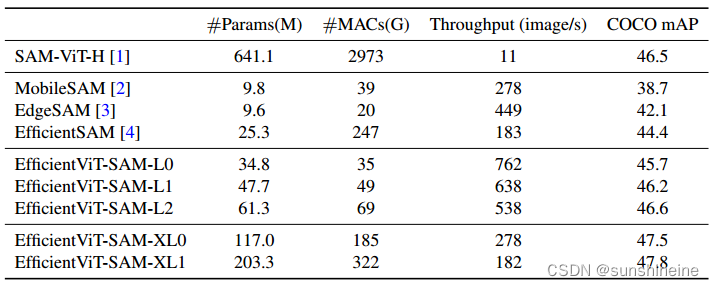
作者比较了EfficientViT-SAM与SAM及其他加速工作的模型参数、MACs和吞吐量。结果展示在下表中。作者在单个NVIDIA A100 GPU上进行了吞吐量的测量,并使用了TensorRT优化。结果显示,与SAM相比,作者实现了令人印象深刻的17到69倍的加速。此外,尽管EfficientViT-SAM的参数数量多于其他加速工作,但由于其有效地利用了硬件友好的运算符,因此其吞吐量显著提高。
3.2 零射击点提示分割
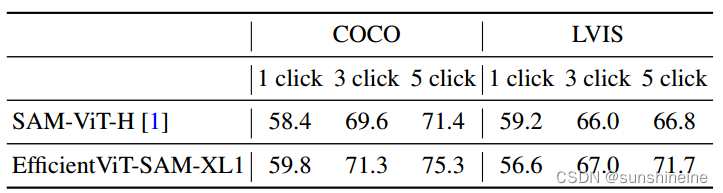
作者在下表中评估了基于点提示对目标进行分割时EfficientViT-SAM的零射击性能。作者采用了SAM中描述的点选择方法。即初始点被选为距离目标边界最远的点。后续的每个点都选为距离错误区域边界最远的点,该错误区域被定义为真实值和先前预测之间的区域。作者在COCO和LVIS数据集上使用1/3/5次点击报告性能,以mIoU(平均交并比)作为评价指标。作者的结果显示,与SAM相比,性能更优,尤其是在提供额外点提示时。
3.3 零射击框提示分割
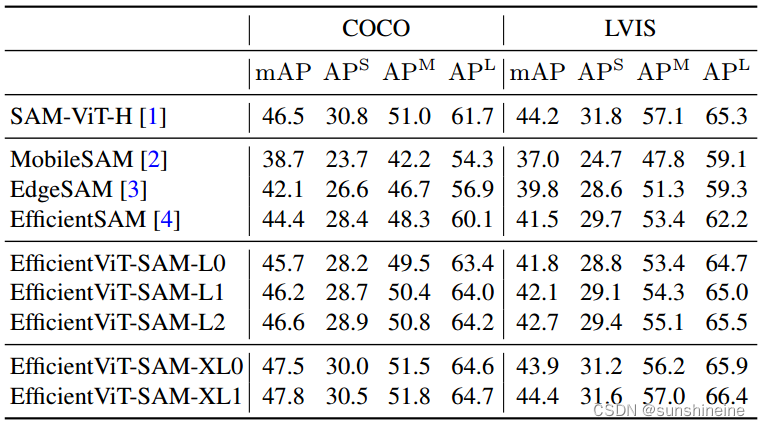
作者评估了EfficientViT-SAM在利用边界框进行目标分割中的零样本性能。首先,作者将真实边界框输入到模型中,结果展示在下表中,所有目标都报告了mIoU(平均交并比),并且分别为小型、中型和大型目标分别报告。EfficientViT-SAM在COCO和LVIS数据集上显著超过了SAM。

接下来,作者采用一个目标检测器ViT-Det,并使用其输出框作为模型的提示。如下表结果显示,EfficientViT-SAM相比于SAM取得了更优的性能。值得注意的是,即使是EfficientViT-SAM的最轻版本,也显著优于其他加速工作。
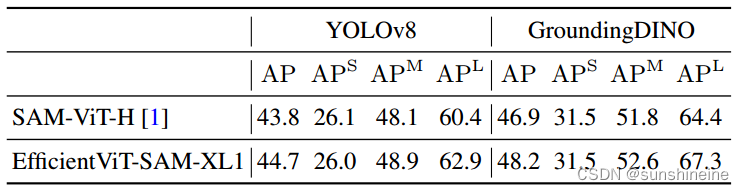
另外,作者使用YOLOv8和GroundingDINO 作为目标检测器,在COCO数据集上评估了EfficientViT-SAM的性能。YOLOv8是一种实时目标检测器,适用于实际应用场景。另一方面,GroundingDINO能够使用文本提示来检测目标,这使得作者可以基于文本线索进行目标分割。下表中展示的结果表明,EfficientViT-SAM相比于SAM具有卓越的性能。
3.4 零射击野外分割
野外分割基准包含25个零射击野外分割数据集。作者将EfficientViT-SAM与Grounding-DINO结合,作为框提示,执行零射击分割。每个数据集的全面性能结果在下表中展示。SAM达到48.7的mAP,而EfficientViT-SAM获得了更高的48.9分。

3.5 定性结果
下图展示了当提供点提示、框提示以及SAM模式时,EfficientViT-SAM的定性分割结果。结果显示,EfficientViT-SAM不仅在分割大型物体上表现出色,也能有效处理小型物体。这些发现强调了EfficientViT-SAM卓越的分割能力



















 2754
2754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









