






对于基于多源检索的高准确率知识问答系统,可以考虑以下系统设计方案,通过不同的数据存储结构和检索方式(如向量检索、知识图谱、ES等),实现更加精准的回答生成。以下是具体设计和实现步骤:
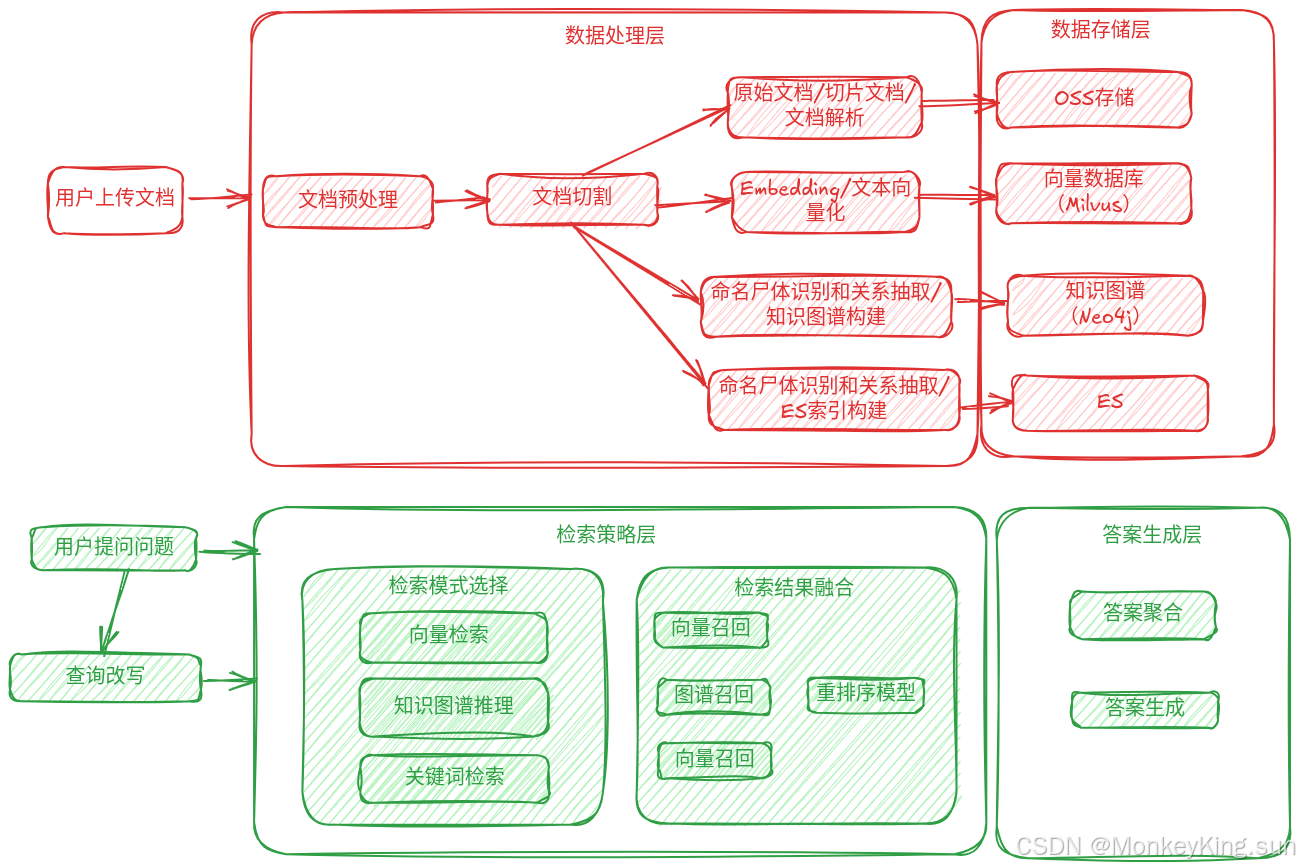
一、系统架构设计
-
数据存储层
- 向量数据库(如 Milvus, Pinecone):用于存储文本、段落或整篇文档的向量化表示,支持语义级别的检索和相似度计算。
- 知识图谱(如 Neo4j, Dgraph):用于结构化数据管理,尤其适用于复杂关系的检索(如关联性问题或推理)。
- Elasticsearch (ES):用于关键词搜索和全文索引,支持复杂的布尔逻辑检索和查询过滤。
- 原始文档存储(如 MinIO, 文件系统):存储原始 PDF 文档内容,确保在需要的时候能够查找到原文。
-
数据处理层
- 文档解析:使用 PDF 解析工具(如 PDFMiner, PyPDF2)将 PDF 文档切分为段落或句子,并提取文本和元数据(如标题、章节、图片描述等)。
- 文本向量化:通过嵌入模型(如 BERT, SentenceTransformers)将文本内容向量化,存入向量数据库。
- 知识图谱构建:解析文本中的实体、关系,使用 NLP 方法(如 SpaCy, AllenNLP)进行命名实体识别和关系抽取,将数据存入知识图谱中。
- ES 索引构建:对解析后的文本内容进行关键词提取、分词,生成适合 ES 的索引结构。
-
检索策略层
-
检索模式选择:
- 向量检索:用于处理模糊查询或语义匹配(例如:用户问题用向量化后与段落向量进行相似度比对)。
- 知识图谱推理:用于复杂关系和逻辑推理(例如:用户问“X和Y的关系是什么”)。
- 关键词检索:用于精确匹配和复杂布尔逻辑(例如:用户希望查找某特定关键字的内容)。
-
检索结果融合:
- 各种检索策略返回结果后,进行多路召回(向量召回、关键词召回、图谱召回)。
- 对召回结果使用基于学习的排序模型(Learning to Rank, 如 XGBoost, LambdaRank)进行重排序。
- 采用基于置信度的加权平均或相互验证策略(如使用 cross-encoder 再计算不同策略结果的相似度)。
-
-
答案生成层
- 答案聚合:
- 从多种检索策略中获取的候选答案,通过答案聚合(Answer Aggregation)模型进行融合,剔除冗余或冲突答案。
- 基于上下文的答案生成:
- 利用预训练的语言模型(如 GPT-4、T5)在参考候选答案的基础上生成最终答案。
- 使用知识图谱或关键词匹配的原始文本进行回答验证,确保输出结果与知识库保持一致性。
- 答案聚合:
-
系统优化策略
- 查询改写(Query Rewriting):
- 用户查询中的模糊词汇或拼音简写通过向量检索和关键词替换进行改写,提升检索命中率。
- 自动纠错与拼写修正:
- 检测输入中的拼写错误或不规范词汇,进行自动纠错处理。
- 查询改写(Query Rewriting):
二、具体实现步骤
-
数据准备与导入
- 使用 Python 脚本解析 PDF 文档,将其切分成段落或句子,并提取元数据(如段落位置、章节名等)。
- 对段落文本进行预处理(去除噪声、分句、过滤无用信息),并保存到各个数据库(向量数据库、知识图谱、ES 索引)中。
-
向量化与存储
- 使用
SentenceTransformers或OpenAI Embeddings对每个段落进行向量化,并存入 Milvus。 - 将实体和关系提取结果存入 Neo4j 知识图谱。
- 使用
Elasticsearch对文本构建索引,支持全文检索。
- 使用
-
检索与融合策略
- 当用户提出问题时,首先对问题进行解析(实体识别、语义分析)。
- 根据问题类型选择合适的检索策略:
- 如果问题是开放性或主观性问题(如“什么是…”),优先使用向量数据库。
- 如果问题涉及实体关系(如“X的朋友有哪些”),则优先使用知识图谱。
- 如果问题是具体的文本查找(如“第几章提到了Y”),则使用 ES 进行关键词检索。
- 将多种检索结果汇总,使用
BM25或cross-encoder模型对候选结果进行重排序。
-
答案生成与验证
- 利用生成模型(如 GPT-4)对检索结果进行答案生成,并进行上下文扩展(例如补充上下文、细化答案)。
- 使用召回的原始文本或图谱中的关系进行交叉验证,确保答案的准确性。
-
系统集成与 API 接口
- 使用 FastAPI 搭建接口服务,集成所有检索策略,并通过 RESTful API 方式对外提供统一的问答接口。
- 向客户端返回答案以及检索路径(即,使用了哪些数据源和检索策略)。
三、关键技术选型
- 向量数据库:
- Milvus, Pinecone, Qdrant。
- 知识图谱:
- Neo4j, Dgraph, ArangoDB。
- 全文索引:
- Elasticsearch, OpenSearch。
- 向量化模型:
- BERT, SentenceTransformers, OpenAI Embeddings。
- 答案生成模型:
- GPT-4, T5, BART。
四、系统示例流程
- 用户输入问题:
- “讲一下《数据结构》这本书中关于二叉树的内容。”
- 问题解析与检索策略选择:
- 检测到“二叉树”为关键词,匹配相关实体和关系,触发向量检索和关键词检索。
- 多路检索与召回:
- 通过向量数据库找到相关段落,通过 ES 查找到具体章节位置,通过图谱查找到相关概念及推理路径。
- 结果融合与答案生成:
- 对检索到的内容进行融合,生成答案:“《数据结构》中关于二叉树的内容主要包括……”,并补充上下文细节。
- 返回结果与追溯路径:
- 返回最终答案,并提供每个答案的原始出处及检索策略(如“向量检索”或“关键词匹配”)。
通过这种设计,可以实现高准确率的多源知识问答系统,并能够兼顾灵活性、可扩展性和高效性。


















 2516
2516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











