







| 【导读】本文是专栏《计算机视觉40例简介》的第22个案例《目标检测(YOLO方法、SSD方法)》。该专栏简要介绍李立宗主编《计算机视觉40例——从入门到深度学习(OpenCV-Python)》一书的40个案例。 目前,该书已经在电子工业出版社出版,大家可以在京东、淘宝、当当等平台购买。 大家可以在公众号“计算机视觉之光”回复关键字【案例22】获取本文案例的源代码及使用的测试图片等资料。 针对本书40个案例的每一个案例,分别录制了介绍视频。如果嫌看文字版麻烦,可以关注公众号“计算机视觉之光”直接观看视频介绍版。 本文简要介绍了本案例的一些基础知识,更详细的理论介绍、代码实现等内容请参考《计算机视觉40例简介》第24章《深度学习应用实践》以获取更详细信息。 |
图像分类是将整张图片作为一个整体来看待,而实践中一张图片内往往包含很多个不同的对象。因此,我们往往希望能够对图像内的多个对象进行检测。更进一步来说,图像检测包含两方面的任务:
- 任务1:识别一张图片的多个物体,这属于分类任务。
- 任务2:输出目标的具体位置信息(给出边界框),属于定位任务。
常见的目检测算法有R-CNN系列算法、YOLO和SSD,后续算法基本都是在上述算法基础上的改进,力求获得更好的检测效果。
1 YOLO方法
YOLO来源于You Only Look Once,意味着“仅看一次就解决问题”。YOLO的经典版本是YOLO v1、YOLO v2、YOLO v3,作者均为Joseph Redmon。在上述基础上,又出现了版本4和版本5两个最新版本。版本4曾得到YOLO原作者的认可,被认为是当时最强的实时对象检测模型之一。YOLO v5的速度更快,而且具有非常轻量级的模型大小。
在YOLO之前的目标检测方法都是先产生候选区,再检测。这样的two-stage方式虽然有相对较高的准确率,但运行速度相对较慢。而YOLO则将候选区筛选和检测对象两个阶段合二为一,只需一眼就看出来每张图像中有哪些物体以及物体的位置。
YOLO方法中,没有显式的候选框提取过程,是one-stage目标检测算法。它采用“端到端”(end-to-end)的方式完成目标检测。YOLO的输入是一张图像,输出是图像内对象的坐标位置(框定框)、对象类别和置信度。更进一步来说,YOLO采用整张图来训练模型,筛选候选框。
在图像分类中,我们得到的是图像的类别信息(及置信度);在目标检测中,我们需要得到图像内各个对象的类别、每个对象的边框(及对象的置信度)。
如图1所示,展示了图像分类与目标检测的区别:
- 图像分类仅仅需要输出当前图像的分类信息即可。
- 目标检测时,YOLO会将输入图像划分为若干个子单元,如果某个对象的中心点落在在某个子单元内,那么该子单元就负责检测该对象。最终,会输出图像内多个对象的类别、所在位置等信息。

图1 YOLO处理方式
使用了YOLO方法的核心代码如下:
for out in outs: # 各个输出层(共3各层,逐层处理)
for candidate in out: #每个层中,包含几百个可能的候选框,逐个处理
#每个candidate(共85个数值)包含三部分:
# 第1部分:candidate[0:4]存储的是边框位置、大小(使用的是相对于image的百分比形式)
# 第2部分:candidate[5]存储的是当前候选框的置信度(可能性)
# 第3部分:第5-84个值(candidate[5:]),存储的是对应classes中每个对象的可能性(置信度)
# 在第5-84个值中,找到其中最大值及对应的索引(位置)。两种情况:
# 情况1:如果这个最大值大于0.5,说明当前候选框是最终候选框的可能性较大。
# 保留当前可能性较大的候选框,留作后续处理。
# 情况2:如果这个最大值不大于(小于等于)0.5,抛弃当前候选框。
# 对应到程序上,不做任何处理。
scores = candidate[5:] # 先把第5-84个值筛选出来
classID = np.argmax(scores) # 找到其中最大值对应的索引(位置)
confidence = scores[classID] # 找到最大的置信度值(概率值)
# 下面开始对置信度大于0.5的候选框进行处理。
# 仅考虑置信度大于0.5的,小于该值的直接忽略(不做任何处理)
if confidence > 0.5:
# 获取候选框的位置、大小
# 需要注意,位置、大小都是相对于原始图像image的百分比形式。
# 因此,位置、大小通过将candidate乘以image的宽度、高度获取
box = candidate[0:4] * np.array([W, H, W, H])
# 另外需要注意,candidate所表示的位置是矩形框(候选框)的中心点位置
(centerX, centerY, width, height) = box.astype("int")
# OpenCV中,使用左上角表示矩形框位置。
# 将通过中心点获取左上角的坐标。
#centerX,centerY是矩形框的中心点,通过他们计算出左上角坐标x,y
x = int(centerX - (width / 2)) #x方向中心点-框宽度/2
y = int(centerY - (height / 2)) #y方向中心点-框高度/2
# 将当前可能性较高的候选框放入boxes中
boxes.append([x, y, int(width), int(height)])
# 将当前可能性较高的候选框对应的置信度confidence放入confidences内
confidences.append(float(confidence))
# 将当前可能性较高的候选框所对应的类别放入resultIDS中
resultIDS.append(classID)运行使用了YOLO方法的程序,显示如图2所示,在图中对各个对象进行了标注。
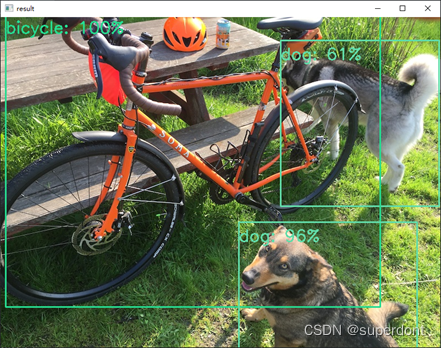
图2 YOLO方法处理结果
2 SSD方法
SSD算法是指Single Shot MultiBox Detector。它也是“端到端”的,即直接接收输入图像后输出计算结果。因此,SSD算法很好地改善了检测速度,能够更好地满足目标检测的实时性要求。同时,SSD的计算精度也有进一步的提高。
如图3所示是SSD框架。在训练阶段,SSD的输入是原始图像和标注好的框,如图(a)所示。在卷积运算中,会将图像划分为尺度不同的“feature map”,进行处理。例如,图(b)中“feature map”包含8×8共计64个小单元,而在图(c)中“feature map”包含4×4共计16个小单元。在每一个小单元上,计算以当前小单元为中心的若干个(图中是4个)default box(图中虚线标注的方框)的“位置值”(图中loc:中心点(cx,cy),宽度w,高度h)及针对各个分类的置信度(图中conf:c1,c2,…,cp)。训练时,首先匹配所有的“default box”和输入中实际标注框。例如,本图中,有两个“default box”匹配到了输入图像中的猫(如图b中左下方的粗虚线边框),一个“default box”匹配到了输入图像中的狗(如图c中粗虚线边框)。因此,这几个“default box”被作为正例,其他的所有“default box”被作为负例。
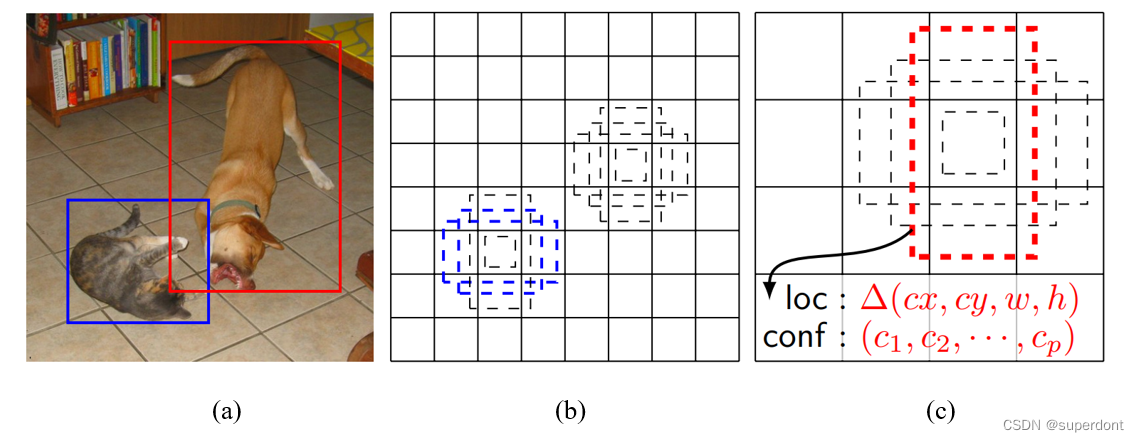
图3 SSD框架
应用SSD方法的核心代码如下:
for i in np.arange(0, outs.shape[2]): # 逐个遍历各个候选框
# 获取置信度,用于:1判断当前对象是否显示、2显示用
confidence = outs[0, 0, i, 2]
if confidence >0.3 : #将置信度大于0.3的对象显示出来,忽略置信度小的对象
# 获取当前候选框对应类别在classes内的索引值
index = int(outs[0, 0, i, 1])
# 获取当前候选框的位置信息(左上角、右下角坐标值)
box = outs[0, 0, i, 3:7] * np.array([W, H, W, H])
# 获取左上角、右下角坐标值
(x1,y1,x2,y2) = box.astype("int")
# 类别标签及置信度
result = "{}: {:.0f}%".format(classes[index],confidence * 100)
# 绘制边框
cv2.rectangle(image, (x1,y1), (x2,y2),classesCOLORS[index], 2)
# 绘制类别标签
cv2.putText(image, result, (x1, y1+25),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, classesCOLORS[index], 2)运行应用SSD方法的程序,显示如图4所示,在图中对各个对象进行了标注。
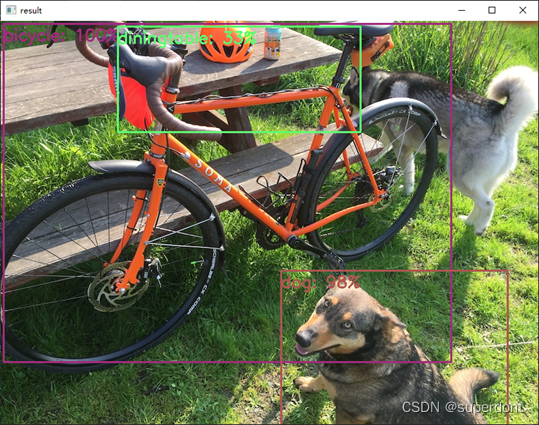
图4 运行结果
欢迎大家阅读《计算机视觉40例——从入门到深度学习(OpenCV-Python)》一书中第24章《深度学习应用实践》获取详细内容。
《计算机视觉40例——从入门到深度学习(OpenCV-Python)》在介绍Python基础、OpenCV基础、计算机视觉理论基础、深度学习理论的基础上,介绍了计算机视觉领域内具有代表性的40个典型案例。这些案例中,既有传统的案例(数字识别、答题卡识别、物体计数、缺陷检测、手势识别、隐身术、以图搜图、车牌识别、图像加密、指纹识别等),也有深度学习案例(图像分类、风格迁移、姿势识别、实例分割等),还有人脸识别方面的案例(表情识别、驾驶员疲劳监测、识别性别与年龄等)。



















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











