







2024ICML(International Conference on Machine Learning,国际机器学习会议)在2024年7月21日-27日在奥地利维也纳举行
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
Mamba进行了自我更新迭代变为了Mamba2接收了(Gu和Dao换了一下作者顺序)
Transformers are SSMs: Generalized Models and Efficient Algorithms with Structured State Space Duality
作者:Tri Dao,Albert Gu
链接:https://icml.cc/virtual/2024/poster/32613
注:现在都是poster,还没有评出来Oral

另外标题带Mamba的还有两篇
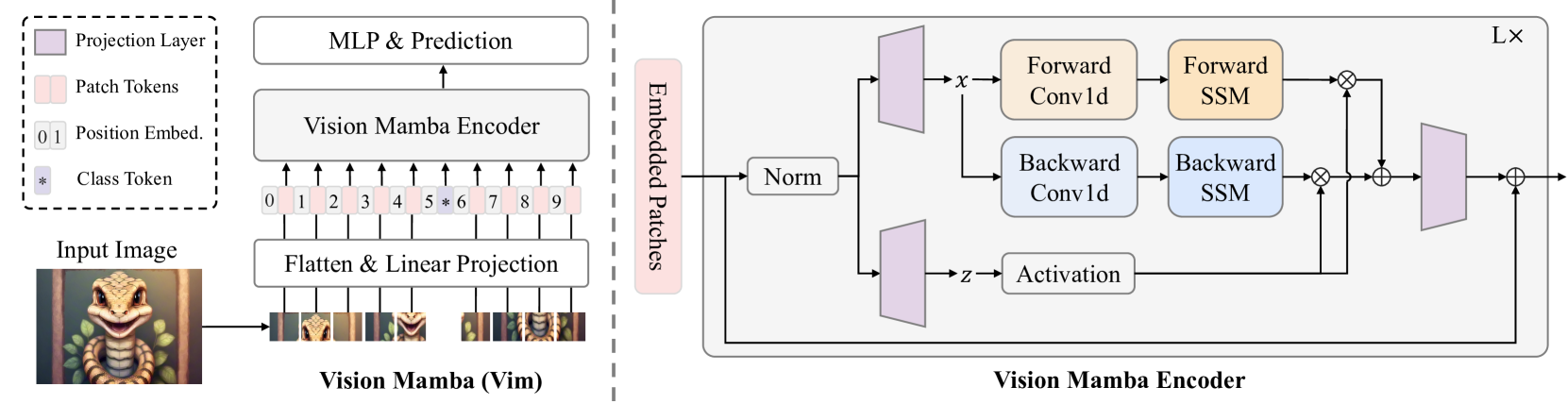
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
(已经太多号推过这个文章了)
作者:Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, Xinggang Wang
机构:华中科技大学,地平线机器人,北京智源研究院
链接:https://arxiv.org/abs/2401.09417
代码:https://github.com/hustvl/Vim
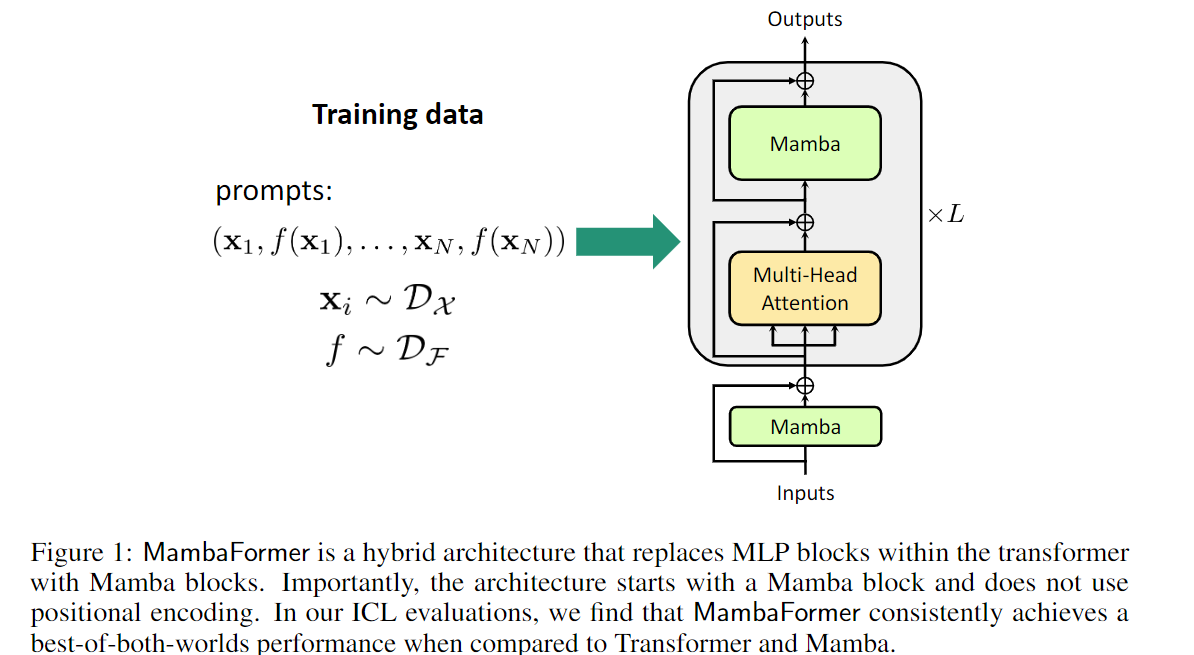
Can Mamba Learn How To Learn? A Comparative Study on In-Context Learning Tasks
作者:Jongho Park, Jaeseung Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, Dimitris Papailiopoulos
机构:蓝洞工作室(做绝地求生即吃鸡那个公司),首尔大学,威斯康辛大学麦迪逊分校,密歇根大学安娜堡分校
链接:https://arxiv.org/abs/2402.04248
代码:https://github.com/krafton-ai/mambaformer-icl
搜索State-space Models和State space Models也能搜到一共7篇,感兴趣的各位可以搜一下看看,我就不一一罗列了。
相关链接
ICML24全部论文:ICML 2024 Papers
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









