









🚀 YOLOv8 神经网络结构全解析
📌 本文适合对深度学习已有基础,想深入理解 YOLOv8 架构的开发者、毕业设计同学、科研项目实践者
👨💻 作者:夏驰和徐策
🧠 关键词:YOLOv8、神经网络结构、张量输入、Backbone、Neck、Head、结构拆解
一、YOLOv8 是什么?
YOLOv8(You Only Look Once version 8)是 Ultralytics 公司推出的全新一代目标检测框架。与前几代相比,它不仅精度更高,还支持:
-
Anchor-Free 检测结构
-
解耦式 Head
-
支持分类 / 检测 / 分割 / 姿态识别 多任务
-
更模块化、便于部署与魔改
如果你想了解 YOLOv8 是怎么“从一张图”变成“边框 + 类别 + 置信度”的,这篇文章将一步步为你剖析其网络架构。
二、输入张量结构详解:[B, 3, 640, 640]
在 YOLOv8 中,输入图像被转换为 4 维张量:
[B, C, H, W] = [Batch Size, Channel, Height, Width]
| 维度 | 含义 |
|---|---|
B | 一次输入多少张图(如 8 张) |
3 | RGB 三通道图像,不是复制三次,而是分别表示红、绿、蓝 |
640x640 | 每张图的分辨率(可变,YOLOv8 默认支持 320~1280) |
张量 [3, 640, 640] 实际表示:
-
1 张图有 3 层通道(红、绿、蓝)
-
每一层是一个 640x640 的灰度图
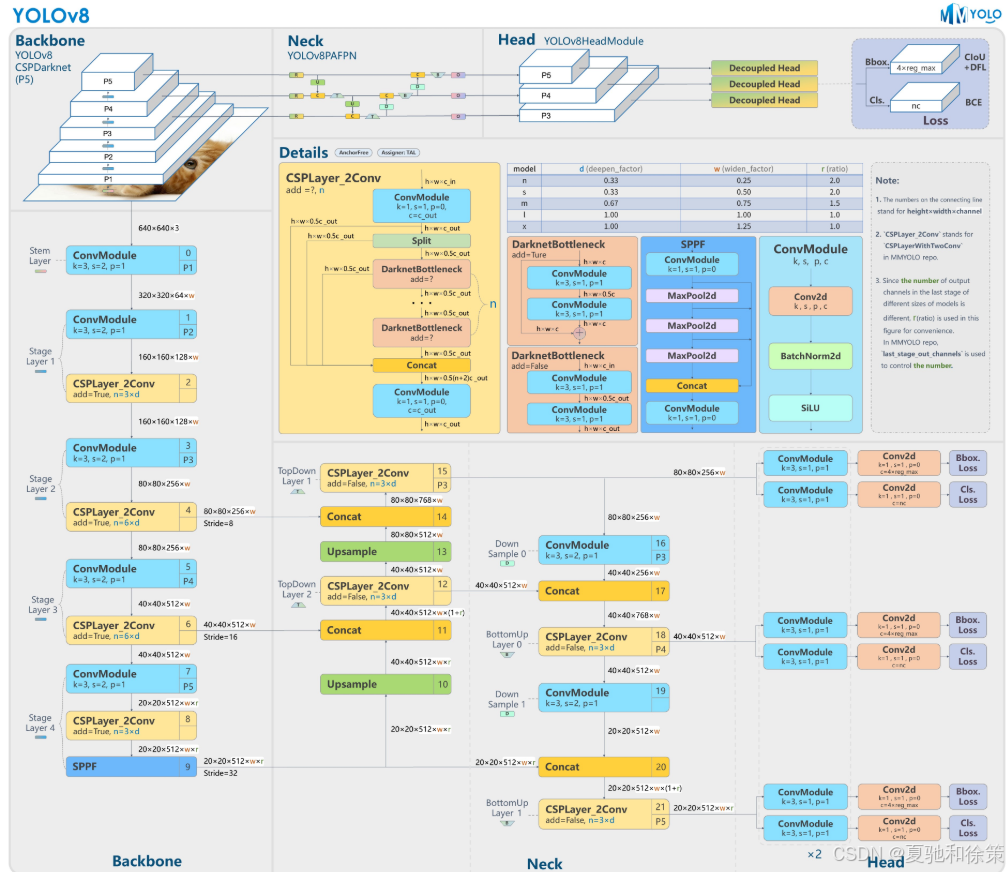
三、YOLOv8 的核心结构:Backbone + Neck + Head
[图像输入]
↓
[Backbone] ← 提取图像语义特征
↓
[Neck: PAFPN] ← 融合多尺度特征
↓
[Head: 解耦头] ← 输出检测结果 (边框+置信度+类别)
四、模块一:Backbone - CSPDarknet + SPPF
✅ 作用:
提取图像的多层语义特征,并逐层下采样,提取从边缘到高级语义的多尺度特征图。
🧩 包含模块:
| 模块 | 输出张量 | 说明 |
|---|---|---|
| Stem Conv | [B, 32, 320, 320] | 卷积 + BN + SiLU 激活 |
| CSP Block 1 | [B, 64, 160, 160] | 第一次下采样 |
| CSP Block 2 | [B, 128, 80, 80] | 第二次下采样 |
| CSP Block 3 | [B, 256, 40, 40] | 第三次下采样 |
| CSP Block 4 | [B, 512, 20, 20] | 第四次下采样 |
| SPPF | [B, 512, 20, 20] | 空间金字塔池化,融合多尺度感受野 |
📌 通道数依据模型规模不同(n/s/m/l/x)而变化,例如 yolov8s 与 yolov8x 会使用不同宽度系数。
五、模块二:Neck - PAFPN(Path Aggregation)
✅ 作用:
通过上下采样融合不同分辨率的特征图,增强多尺度目标的检测能力(尤其是小目标)。
🧩 核心过程:
-
Upsample + Concat(Top-Down 路径) -
Downsample + Concat(Bottom-Up 路径)
最终输出三个特征图:
-
P3:[B, 128, 80, 80]← 小目标 -
P4:[B, 256, 40, 40]← 中目标 -
P5:[B, 512, 20, 20]← 大目标
📌 每个尺度特征图上的每一个像素位置,相当于在原图上的一个检测点。
六、模块三:Head - 解耦式预测头(Decoupled Head)
✅ 作用:
对每个位置进行目标检测预测,包括:
-
边框坐标
[x, y, w, h] -
置信度
objectness -
类别概率
class score
每个 Head 的输出张量为:
[B, num_classes+5, H, W]
以 COCO 80 类为例,num_classes = 80,所以输出为:
[B, 85, 80, 80](P3)
[B, 85, 40, 40](P4)
[B, 85, 20, 20](P5)
| 值 | 含义 |
|---|---|
| 4个 | 边框 [x, y, w, h] |
| 1个 | 置信度 objectness |
| 80个 | 类别概率分布 class_1, class_2, ..., class_80 |
七、输出张量(Postprocess)
预测结果经过 NMS 处理后输出:
[B, N, 6] = [batch, num_detections, (x1, y1, x2, y2, conf, class)]
-
conf = objectness × class_score -
每个检测结果包含预测框坐标、置信度、类别编号
八、模型缩放机制(n/s/m/l/x)
| 模型 | depth_multiple | width_multiple | 适合场景 |
|---|---|---|---|
| yolov8n | 0.33 | 0.25 | 极小模型,部署边缘设备 |
| yolov8s | 0.33 | 0.50 | 小模型,适合低端 GPU |
| yolov8m | 0.67 | 0.75 | 中型模型 |
| yolov8l | 1.00 | 1.00 | 大型模型 |
| yolov8x | 1.00 | 1.25 | 超大精度要求任务 |
结构保持一致,只是通道数和模块重复次数不同。
九、总结一张图(张量流动结构):
[B, 3, 640, 640] ← 输入RGB图像
↓
Backbone
├─ StemConv → [B, 32, 320, 320]
├─ CSPBlock × 4 → ... → [B, 512, 20, 20]
└─ SPPF → [B, 512, 20, 20]
↓
Neck
├─ Upsample + Concat (P4, P5)
├─ Downsample + Concat (P3, P4)
└─ 输出 P3, P4, P5 → 多尺度特征图
↓
Head
├─ 每个位置预测 85 维度(80类+5个框信息)
└─ 拼接后 → [B, N, 6] ← 检测结果
🔚 十、参考与延伸阅读
-
动手学深度学习(7~8章、14章)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











