







在上一篇文章长短期记忆网络LSTM原理详解中,我们介绍了LSTM的原理,那这一篇文章就以一个简单的情感分析的代码例子,来学习一下在代码中如何应用LSTM。
文章目录
1 介绍
情感分析(Sentiment Analysis)是自然语言处理中的经典任务之一,目标是判断一段文本中表达的情绪倾向,比如褒义、贬义或中性。在电商评论、舆情监测、客服反馈等场景中都有着广泛的应用价值。
相比传统的机器学习方法,基于循环神经网络(RNN)尤其是长短期记忆网络(LSTM)的模型,能够更好地捕捉文本中的上下文依赖关系,从而取得更优的效果。
1.1 为什么用LSTM
LSTM 能够理解和记住文本中的上下文顺序,从而更准确地判断整句话的情绪倾向。
在情感分析任务中,你的输入是一段文本,例如:
“我本来以为这部电影会很好看,但结果真的很失望。”
对于这样有“转折”结构的句子,情绪的倾向主要取决于后半部分。而:
- LSTM 能一边“读”句子,一边“记住”前文内容;
- 它通过隐藏状态 h t h_t ht 和单元状态 C t C_t Ct 来捕捉整句话中重要的情感信息;
- 最终输出的向量表示了整句话的情绪语义,再用于分类(比如正面 or 负面)。
为什么不用普通分类模型,比如朴素贝叶斯、SVM?
这是个非常经典的对比。传统的机器学习模型,通常这样处理文本:
- 用
CountVectorizer或TF-IDF把文本转为词频向量; - 然后用 朴素贝叶斯 / SVM / 逻辑回归 做分类。
这种方法有两个局限:
局限 1:忽略词语顺序
传统方法将文本转成词袋(bag of words),只知道词出现了,不知道词的顺序。比如:
“我喜欢你” 和 “你喜欢我”
在词袋模型中向量可能是一样的,语义却完全不同!
局限 2:难以建模上下文依赖
它们无法捕捉“前面的话如何影响后面”的关系。比如:
“虽然前面有点无聊,但结尾非常精彩!”
传统模型可能会被“无聊”误导,而 LSTM 能根据上下文判断真正的情绪是正面。
LSTM 就像一个在“读懂整句话”的分析师,而传统模型像是在“数词”的统计员。它们都能做分类,但 LSTM 的理解能力更强,尤其适合中文、情绪多变、含有转折/暗示的句子,是情感分析中的更优选。
2 代码实现
2.1 环境准备与数据读取
首先,我们导入所需的第三方库。这里使用了 Keras 构建神经网络,pandas 用于数据处理,sklearn 进行基本的预处理与数据划分:
import numpy as np # 数值计算
import pandas as pd # 数据处理
from sklearn.feature_extraction.text import CountVectorizer
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, SpatialDropout1D
from sklearn.model_selection import train_test_split
from keras.utils.np_utils import to_categorical
import re
接着我们读取数据,并筛选我们需要的列:
data = pd.read_csv('../input/Sentiment.csv')
# 仅保留文本和情感标签两列
data = data[['text','sentiment']]
我们只需要text和sentiment两列,其中text为评论,sentiment为情感(Neutral,Positive和Negative)。
2.2 文本预处理与编码
接下来,我们开始对原始的文本数据进行预处理。第一步是去掉中性(Neutral)情感的样本,因为在本次任务中我们只关心Positive和Negative这两类情绪。这是一个二分类问题,因此我们删除了中性样本。
data = data[data.sentiment != "Neutral"]
然后,对文本内容进行清洗,包括:
- 全部转为小写;
- 去除非字母数字字符(如标点、特殊符号);
- 删除转发符号 “rt”。
data['text'] = data['text'].apply(lambda x: x.lower())
data['text'] = data['text'].apply(lambda x: re.sub('[^a-zA-z0-9\s]','',x'))
for idx, row in data.iterrows():
row[0] = row[0].replace('rt', ' ')
我们打印一下每种情感的样本数量:
print(data[ data['sentiment'] == 'Positive'].size) # 输出:4472
print(data[ data['sentiment'] == 'Negative'].size) # 输出:16986
2.3 分词与向量化:将文本转为数值序列
接下来,我们使用 Keras 中的 Tokenizer 将清洗后的文本转为数值化的序列,便于神经网络处理:
max_fatures = 2000
tokenizer = Tokenizer(num_words=max_fatures, split=' ')
tokenizer.fit_on_texts(data['text'].values)
X = tokenizer.texts_to_sequences(data['text'].values)
X = pad_sequences(X)
这里设置了 max_features = 2000,也就是只保留最常出现的 2000 个词。Tokenizer 会根据词频为每个词分配一个唯一的编号,最终将文本转为整数序列。
pad_sequences 则是将这些序列填充到统一长度,方便后续输入模型。
- 神经网络的输入必须是等长的向量,但每个句子的长度是不一样的,有的 5 个词,有的 20 个词。
所以我们需要统一句子的长度 —— 补 0 或截断。- 神经网络是一种“矩阵计算”的系统,它要求每一批输入在形状上是统一的,不然数学上就没法进行运算。
2.4 构建 LSTM 网络结构
现在我们定义 LSTM 模型结构。网络由以下几层构成:
embed_dim = 128
lstm_out = 196
model = Sequential()
model.add(Embedding(max_fatures, embed_dim, input_length=X.shape[1]))
model.add(SpatialDropout1D(0.4))
model.add(LSTM(lstm_out, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(2, activation='softmax'))
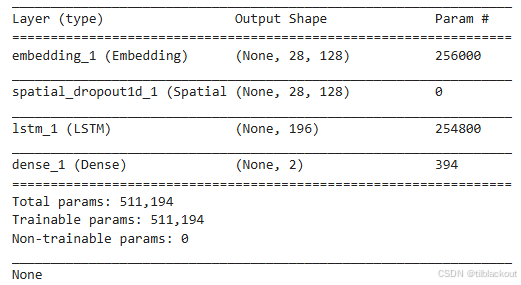
首先,设置词向量维度为 128(embed_dim),LSTM 输出维度为 196(lstm_out)。模型的第一层是 Embedding 层,用于将每个词的整数索引转换为稠密向量,输入维度为词汇表大小,输出为固定长度的词向量序列。随后使用 SpatialDropout1D 层以词向量为单位进行随机丢弃,有助于提高模型的泛化能力。
- 稠密向量是用少量数字来表示一个词的含义,Embedding 层就是用来生成这种语义向量的工具(本文中NLP相关的知识,仅简单解释一下)
核心的 LSTM 层包含 196 个隐藏单元,并应用了输入和递归 Dropout,增强对序列的记忆能力。最后一层是一个 Dense 全连接层,输出为 2 维(表示正面或负面情感),激活函数为 softmax,用于输出每个类别的预测概率。
然后我们用交叉熵损失函数和 Adam 优化器进行编译:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
输出如下:
2.5 训练集和测试集划分
我们将情感标签转为 one-hot 向量,并划分训练集与测试集:
Y = pd.get_dummies(data['sentiment']).values
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
print(X_train.shape, Y_train.shape) # (7188, 28) (7188, 2)
print(X_test.shape, Y_test.shape) # (3541, 28) (3541, 2)
pd.get_dummies把情感类别从文本(如 “Positive”)转换为模型可训练的 one-hot 编码(如[0, 1])- 神经网络的输出是一个向量,如 [0.8, 0.2],表示两个类别的概率。所以我们希望真正的标签也是向量。
2.6 模型训练与评估
模型搭建完成后,我们使用训练数据对其进行训练。设置的超参数包括:
batch_size = 32:每次训练使用的样本数量;epochs = 7:迭代 7 次,可以根据算力和模型表现自行调整
batch_size = 32
model.fit(X_train, Y_train, epochs = 7, batch_size=batch_size, verbose = 2)
训练过程中模型的准确率逐步提升,从第一轮的 81% 提升到第七轮的 92.6%,表现出良好的学习能力:
Epoch 1/7 - loss: 0.4389 - acc: 0.8143
Epoch 2/7 - loss: 0.3256 - acc: 0.8646
Epoch 3/7 - loss: 0.2833 - acc: 0.8837
Epoch 4/7 - loss: 0.2564 - acc: 0.8926
Epoch 5/7 - loss: 0.2247 - acc: 0.9058
Epoch 6/7 - loss: 0.2067 - acc: 0.9174
Epoch 7/7 - loss: 0.1842 - acc: 0.9260
2.7 验证集评估与单类分析
接下来我们从测试集中划出一部分作为验证集,并进行模型评估:
validation_size = 1500
X_validate = X_test[-validation_size:]
Y_validate = Y_test[-validation_size:]
X_test = X_test[:-validation_size]
Y_test = Y_test[:-validation_size]
score, acc = model.evaluate(X_test, Y_test, verbose = 2, batch_size = batch_size)
print("score: %.2f" % (score))
print("acc: %.2f" % (acc))
模型在测试集上的表现为:
score: 0.42
acc: 0.84
总体准确率达到了 84%,表现不错。不过,为了更深入理解模型的预测能力,我们继续分析其对正负样本的分类效果:
pos_cnt, neg_cnt, pos_correct, neg_correct = 0, 0, 0, 0
for x in range(len(X_validate)):
result = model.predict(X_validate[x].reshape(1,X_test.shape[1]), batch_size=1, verbose=2)[0]
if np.argmax(result) == np.argmax(Y_validate[x]):
if np.argmax(Y_validate[x]) == 0:
neg_correct += 1
else:
pos_correct += 1
if np.argmax(Y_validate[x]) == 0:
neg_cnt += 1
else:
pos_cnt += 1
print("pos_acc", pos_correct/pos_cnt*100, "%")
print("neg_acc", neg_correct/neg_cnt*100, "%")
结果如下:
pos_acc: 54.05%
neg_acc: 92.95%
可以看出,模型对负面评论的识别非常准确,但在判断正面评论时表现较差。原因可能在于训练集严重不平衡(正面:4472,负面:16986),可以通过以下方式改进:
- 获取更多正面样本;
- 更换或平衡数据集;
- 使用预训练模型(如 BERT);
- 设置类别权重。
2.8 推理示例
最后,我们以一条推文为例,演示模型如何预测其情绪倾向:
twt = ['Meetings: Because none of us is as dumb as all of us.']
twt = tokenizer.texts_to_sequences(twt)
twt = pad_sequences(twt, maxlen=28, dtype='int32', value=0)
sentiment = model.predict(twt, batch_size=1, verbose=2)[0]
if np.argmax(sentiment) == 0:
print("negative")
elif np.argmax(sentiment) == 1:
print("positive")
输出为:

这说明模型识别出了这句话带有讽刺、负面情绪,预测为 negative。
3 小结
本文展示了如何使用 Keras 构建一个基于 LSTM 的情感分类模型。从数据读取到模型训练,再到预测与误差分析,整个流程清晰完整。尽管模型存在类别不平衡问题,但作为入门级项目,还是有一定的参考价值。希望本文的讲解能帮助你更好理解 LSTM 的实际应用。


















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











