







目录
映射过程的理解
一维展开和映射

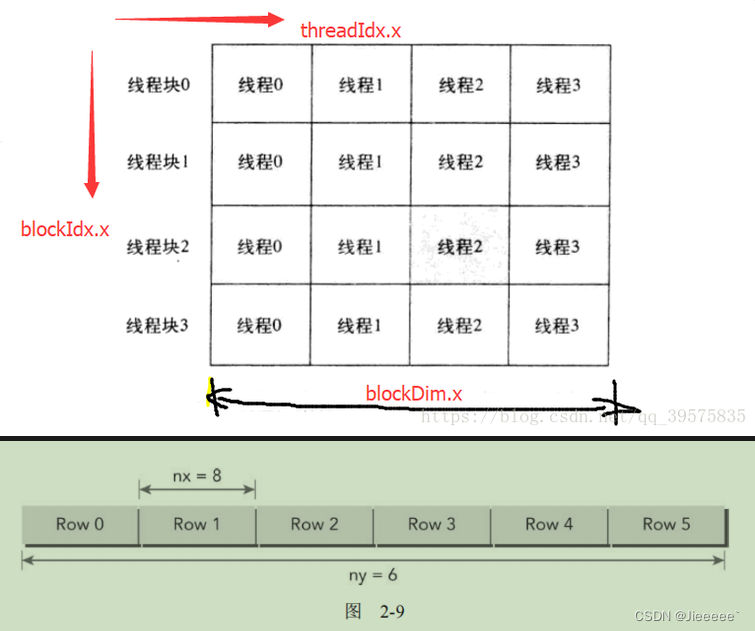
使用的是行优先进行线性存储,相当于把二维数组按行展开,每一行一个线程块,这样展开成一维数组
要所应到展开得到的一维数组的某个特定值,采用的方式就是
int tid = threadIdx.x + blockIdx.x*blockDim.x;
行展开后,这里的X是有增长的,但是Y没有,所以TID只由X轴索引而来
上图中的NX=8就代表blockDim.x=8
blockIdx.x代表的是row 0 到row 5 也就是对应ny
公式就能得出来 idx = iy * nx + ix;
所以说,要通过一维索引的方式索引到44数组的(1,3)这一个数据就是要在44数组的一维展开中找到这个数据,那么就是第14个数据→14=3*4+1
二维展开和映射
二维数组二维展开和一维的思路是一样的,也就是多了一个y轴的索引需要计算,步骤如下
-
利用blockIdx blockDim threadidx来找到某个线程的相对坐标
即 ix = threadIdx.x + blockIdx.x * blockDim.x;
iy = threadIdx.y + blockIdx.y * blockDim.y; - 将索引转换为二维数组索引后,参考一维数组那样,进行‘行展开’,将二维数组展平为一行(方便放进内存)此时如果需要获取某一特定数据,索引就是 idx = iy * nx + ix;
以上两步就实现了从内存到线程号+线程块号的映射,实质还是从一个“行数据”到线程编号+线程块编号的转换,用一个线程去处理一个数据,用几个线程组成一个线程块
举个例
假设:需要处理100*100的两张图(灰度图,单个像素为8bit),让它们相减,并且求绝对值
处理步骤如下:
1.首先将两张图通过opencv读到GPU端的内存中,这个时候,俩张图片就被展开成了“一行数组”存放在内存里,长度是100*100*2=20000,分为了两个区域,对应image1_dev指针和image2_dev指针。
cv::Mat image1 = cv::imread("image1.png", cv::IMREAD_GRAYSCALE);
unsigned char* image1_dev;
cudaMalloc(&image1_dev, width * height);
cudaMemcpy(image1_dev, image1_dev.data, width * height, cudaMemcpyHostToDevice);
2. 设置线程块和线程数量,这里处理是需要相减,仅仅需要执行100*100次即可,让每个线程执行一次相减操作,需要100*100个线程,将线程数对应到32的倍数上去,64*256个线程(据了解每个线程块最多线程数量是1024个),这里的width和height对应的是图片的宽和高
// 设置CUDA的线程块和网格结构
dim3 threadsPerBlock(64, 256); // 64x256个线程块
dim3 numBlocks((width + threadsPerBlock.x - 1) / threadsPerBlock.x, (height + threadsPerBlock.y - 1) / threadsPerBlock.y);3.驱动核函数,这里用到了numBlocks来计算具体的block数量
add_image_Kernel <<<numBlocks, threadsPerBlock >>>(image1_dev,image2_dev);4.核函数里实现,这里将idx = iy * nx +ix 变成了idx = y * width + x,因为图像数据里的宽度width就代表了ny,这里通过两个指针来索引到两张图的GPU内存区域,把他们想象成“一行数组”,就可以理解这个y * width + x的含义
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
image1_dev[y * width + x] = abs(iamge1_dev[y * width + x] - image2_dev[y * width + x]); 我这里试了下线程数量64*256速度最快,如果使用32*32这样的线程数量的话,结果也是正确的,速度会慢不少,应该是线程数量不能一次性覆盖完所有数据运算,内部进行了多轮运算造成,但是不是很明白的是这个机制是如何实现的,明明我这里没有进行线程的跨步处理,线程号和线程块号是无法索引到正确的数据,难不成cuda这种情况下自动调整进行了循环覆盖?
接下来会学习一下线程的跨步处理,即当工作量大于线程数量的时候如何在一个线程里进行跨步处理 ,比如100*100的图像相减通过100个线程进行处理,每个线程完成100个像素的相减。
对线程数量和线程块数量的设置
如果是一维数组进行处理,直接设置一维的线程和线程块就行
size_t threads_per_block = 256; // 每个block的thread数量
size_t number_of_blocks = 32; // block数量二维和三维的时候就需要用到dim3变量,dim3是一个包含三个成员的结构体,分别表示了x、y和z维度上的大小。这样的写法在设置线程块和网格的大小时更加灵活,可以根据需要设置不同维度上的线程块和线程数量。
dim3 threadsPerBlock(8, 128); // 8x128个线程块
dim3 numBlocks((width + threadsPerBlock.x - 1) / threadsPerBlock.x, (height + threadsPerBlock.y - 1) / threadsPerBlock.y);dim3 threadsPerBlock(8, 128)表示每个线程块有8个线程在x维度,以及128个线程在y维度。
而dim3 numBlocks这里,需要随着处理数组的宽度和高度来动态调节,然后加上一个额外的线程块来确保不会溢出,这里也是基于X轴和Y轴来设置线程块的数量,例如640*480的数组,经过以上赋值,结果:线程块为X方向80列,Y方向4行,总共数量就是80*4=320个线程块,每个线程块里有8*128=1024个线程,总和线程就是1024*320=327,680
换回到二维上,这些线程可以组成一个80*8行 4*128列的线程矩阵区域,即640行512列线程矩阵
计算到这个时候再去对比需要处理的二维数组尺寸:
1、能覆盖则能达到性能最优,例如处理300*300数组或是640*480的数组
2、不能覆盖则会出现漏算的情况,例如处理640*640数组,此时就需要考虑增大线程矩阵的行数量或是考虑跨步处理(下一篇博客会提到)















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









