







1. 项目起因
- 最近,阿里开源了一款全新的多智能体协同的Multi-Agent应用框架-AgentScope,早先的单智能体还只能完成对话类等一些简单的应用,通过调用外部API(如搜索 绘画 配音等)也只是拓展了单智能体的能力边界。如果能够调用多个智能体,并做好多个智能体之间的协同配合,就能够打造出内容和样式更加丰富的应用。
- 中国古典诗词中的经典游戏(如飞花令 尾字接龙 即景联诗 九宫格)等,非常考验选手的知识储备。对于裁判而言,如果没有一定知识储备,也很难立刻判断出选手的回答是否正确。这些富有文化魅力和审美体验的活动,却因为
较高的门槛无法惠及更多爱好诗词的朋友。大模型的出现,刚好可以打破这一门槛! - 本项目将以飞花令为切入点,利用AgentsSope开发框架,打造一款和Agent玩飞花令的游戏,希望能够给爱好古诗词的朋友带来一种全新的体验:摆脱场地和人员的限制,随时随地和Agent玩飞花令!
项目地址:和Agent玩飞花令,魔搭创空间链接,欢迎您来体验哦…… 如果对你有帮助,帮忙点颗小红心,谢谢~
2. 游戏简介
飞花令游戏中需要多个角色协同配合,这里的角色完全由多个大模型Agent来扮演,底层大模型可以公用,唯一的区别在于为不同的Agent配备针对角色设计的提示词(Prompt)。具体而言,飞花令这个游戏中至少需要以下三个Agent:
- 主持人Agent:每轮游戏开始会从中国古典诗词常见意象的关键字中随机选择出题。
- 评审官Agent:根据主持人提供的关键字和用户提供的诗句,判断是否回答正确。
- 对手Agent:和用户对垒,确保回答来自中国古诗词且包含关键字,不能和之前重复。
为了确保游戏体验,需要给评审官Agent非常明确的评审规则,比如我这里设定的游戏规则包括:
- 1.必须来自中国古诗词;
- 2.必须包含主持人提供的关键字;
- 3.不能和之前的诗句重复。
PS:游戏规则还需要进一步优化,比如我发现输入有错别字的诗句,评审官Agent目前还无法识别出来。
3. 项目实战
项目代码:https://modelscope.cn/studios/Action/Paper-Genie/files
如需查看项目代码:
Step1: 熟悉AgentScope开发框架
这里主要参考了项目官方文档和Datawhale社区提供的一份非常棒的入门教程:
Step2: 跑通并测试游戏逻辑
游戏配置
代码在:./configs/
针对本项目,我们首先要设计好两个配置文件,也即底层模型和Agent的config:
- model_config.json: 底层模型的配置文件,这里我只用了qwen-max。此外,AgentScope也支持更多底层大模型,具体参数设置可以参考官方文档。
[
{
"model_type": "dashscope_chat",
"config_name": "qwen",
"model_name": "qwen-max",
"api_key": "",
"generate_args": {
"temperature": 0.5
}
}
]
- agent_configs_poem.json:多个Agent的配置文件,本项目主要用到了三个Agent,这里最关键的是需要设计到针对不同角色的提示词sys_prompt。
[
{
"class": "DialogAgent",
"args": {
"name": "host",
"sys_prompt": "作为中国古诗词经典游戏飞花令的主持人,您会从'风 花 雪 月'四个字中随机选择一个关键字,限制:你仅需说出一个关键字,其他的话不需要说",
"model_config_name": "qwen",
"use_memory": true
}
},
{
"class": "DialogAgent",
"args": {
"name": "judge",
"sys_prompt": "作为中国古诗词经典游戏飞花令的评审官,根据主持人提供的关键字和用户提供的诗句,您的任务是判断用户提供的诗句中是否包含主持人提供的关键字。你必须严格遵守以下三条评审规则:1.用户提供的诗句必须来自中国古诗词;2.用户提供的诗句必须包含主持人提供的关键字;3.不能和之前提供的诗句重复。假定用户的初始分score=5,如果用户回答正确,需要给出用户提供诗句的出处,给score加1分并回答'恭喜你,回答正确,加1分,当前得分是{score}'同时鼓励用户继续加油,如果用户回答错误则给score减1分并回答'很遗憾,回答错误,减1分,当前得分是{score}',同时给出用户违反的具体是哪一条评审规则。如果用户得分达到10分,则恭喜用户取得游戏胜利,本轮游戏结束。",
"model_config_name": "qwen",
"use_memory": true
}
},
{
"class": "DialogAgent",
"args": {
"name": "participant",
"sys_prompt": "作为的中国古诗词经典游戏飞花令的参与者,您的任务是根据主持人给出的关键字,给出包含该关键字的一句中国古诗词,比如主持人给的关键字是'花',你可以说'烟花三月下扬州'。限制:请确保您的回答来自中国古诗词,且必须包含关键字,不能和之前的重复。",
"model_config_name": "qwen",
"use_memory": true
}
}
]
逻辑测试
代码在:poem_run.py
这一部分主要是将多个Agent加载进来,并测试他们是否能够有效完成协同配合,核心逻辑主要参考AgentScope官方文档的Agent调用和通信,代码实现如下:
import time
import threading
import agentscope
from agentscope.agents import DialogAgent
from agentscope.agents.user_agent import UserAgent
from agentscope.message import Msg
from agentscope.pipelines import SequentialPipeline
from agentscope.web_ui.utils import send_chat_msg, generate_image_from_name
def main():
agents = agentscope.init(
model_configs="./model_configs.json",
agent_configs="./agent_configs_poem.json",
)
host_agent = agents[0]
judge_agent = agents[1]
parti_agent = agents[2]
user_agent = UserAgent()
thread_name = threading.current_thread().name
uid = thread_name
x = None
msg = Msg(name="system", content="飞花令游戏规则:请回答一句包含特定关键字的中国古诗词。下面有请主持人出题。")
host_msg = host_agent(msg)
host_avatar = generate_image_from_name(host_agent.name)
judge_avatar = generate_image_from_name(judge_agent.name)
parti_avatar = generate_image_from_name(parti_agent.name)
send_chat_msg(f"您好,欢迎来到 飞花令大挑战,{msg.content}",
role=host_agent.name,
flushing=True,
uid=uid,
avatar=host_avatar)
send_chat_msg(f"本轮的关键字是:{host_msg.content}",
role=host_agent.name,
flushing=True,
uid=uid,
avatar=host_avatar)
while x is None or x.content != "退出":
x = user_agent()
judge_content = f'主持人的关键字是{host_msg.content},用户的诗句是{x.content}'
judge_msg = judge_agent(Msg(name='judge', content=judge_content))
send_chat_msg(f"{judge_msg.content}",
role=judge_agent.name,
flushing=True,
uid=uid,
avatar=judge_avatar)
time.sleep(0.5)
if '结束' in judge_msg.content:
break
parti_content = f'主持人的关键字是{host_msg.content}'
parti_msg = parti_agent(Msg(name='parti', content=parti_content))
send_chat_msg(f"{parti_msg.content}",
role=parti_agent.name,
flushing=True,
uid=uid,
avatar=parti_avatar)
if __name__ == "__main__":
main()
测试发现,qwen-max完全可以胜任这个任务。通过测试,迭代修改Agent的提示词sys_prompt使得3个Agent能够更好地完成自己的任务。
Step3:Gradio前端实现
这一部分前置需要对Gradio的常用组件和操作有一定了解,不过不熟悉Gradio也没关系,找一个你觉得还不错的项目界面,down下来依葫芦画瓢改一个,先把流程跑通,后面有时间再慢慢优化UI界面。比如我的具体实践是:
首先,clone了之前开发的一个ModelScope项目-睡前故事小助手的界面设计,这个项目当时还是单智能体对话类项目,集成了语音合成和图像生成API。利用Chatbot设计了如下的页面,核心代码可参考:./app_run.py,算是把项目跑通了。
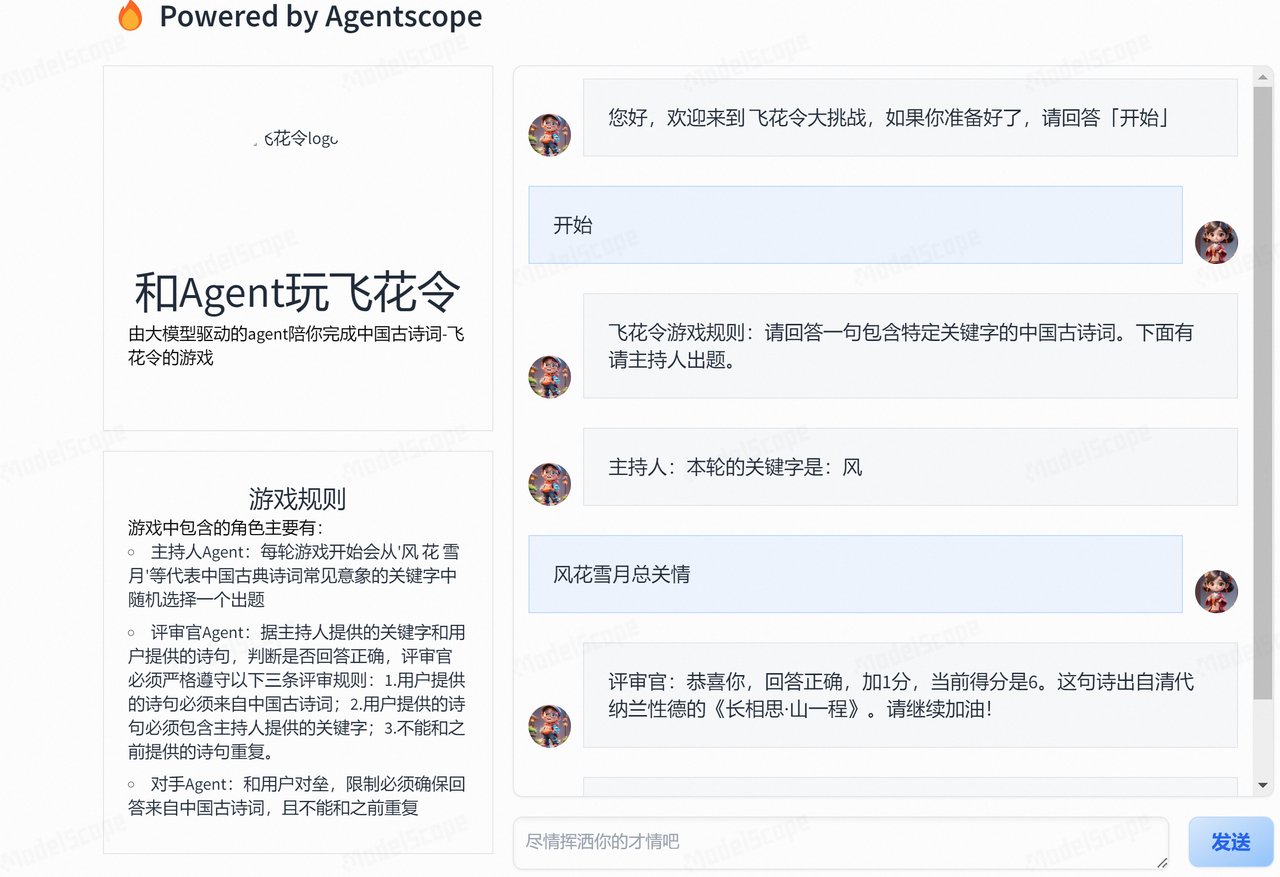
不过这个前端设计的缺陷是:多个Agent之间无法区分,因为单个Chatbot中只能包含两个角色。
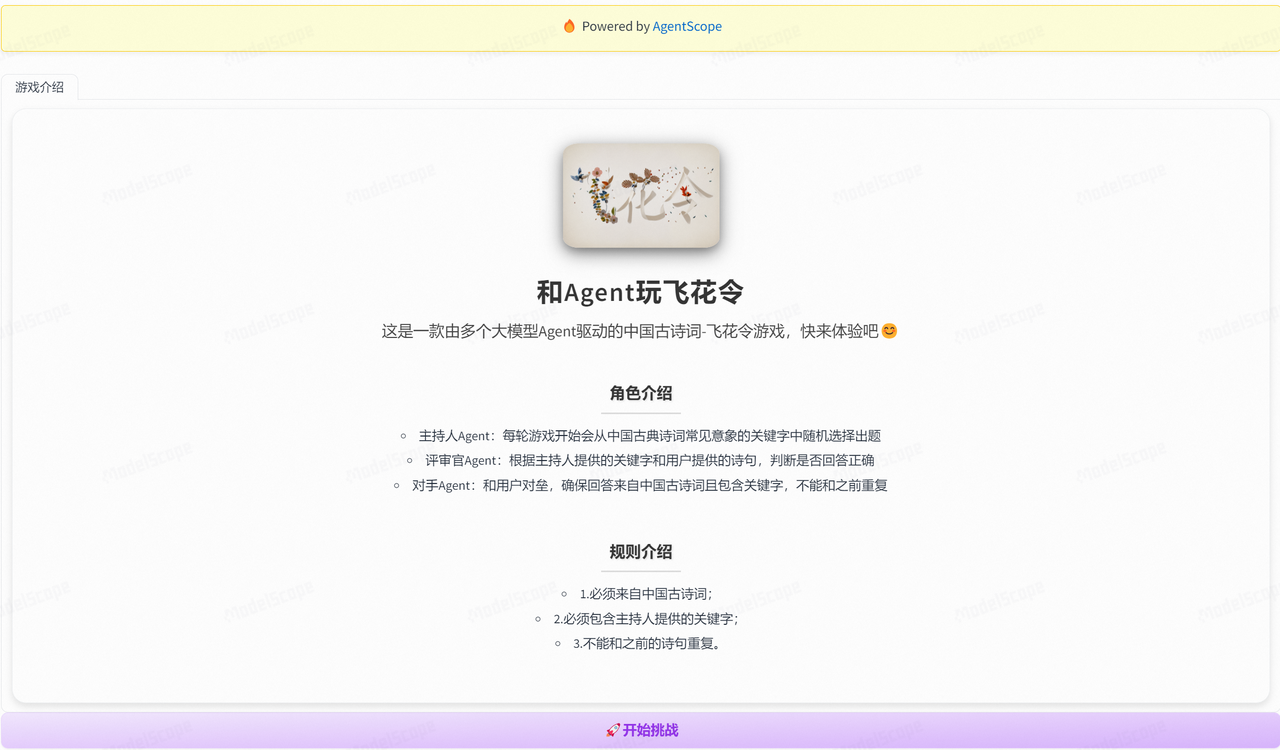
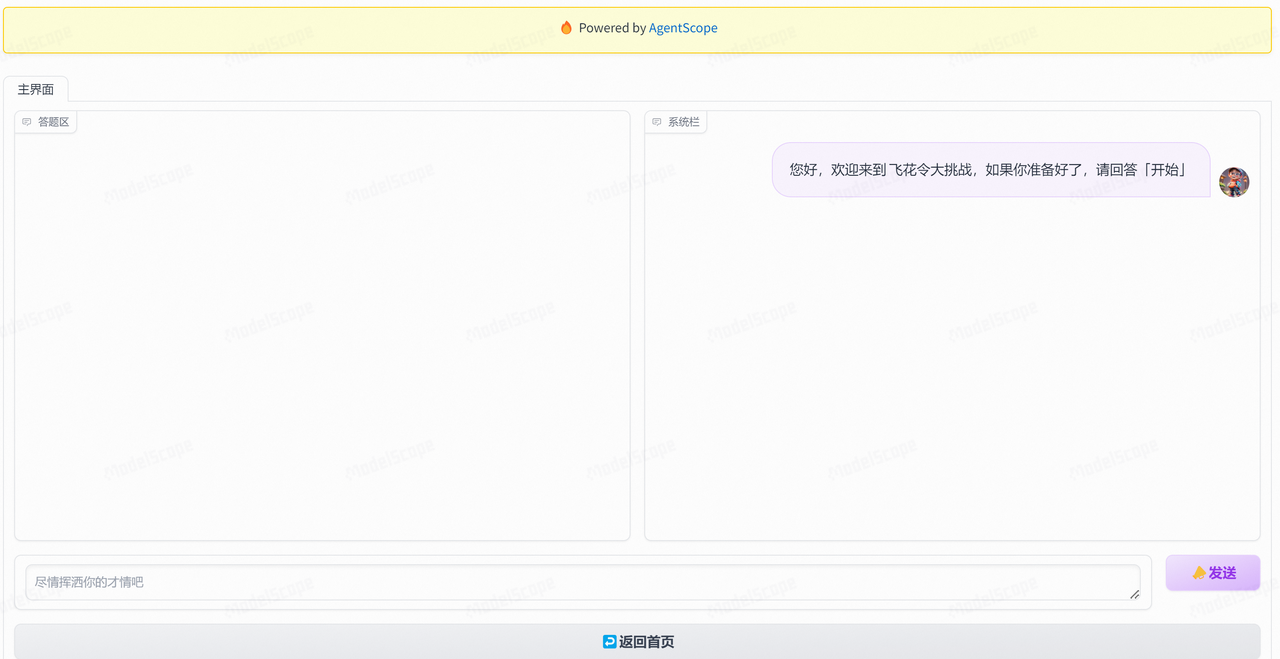
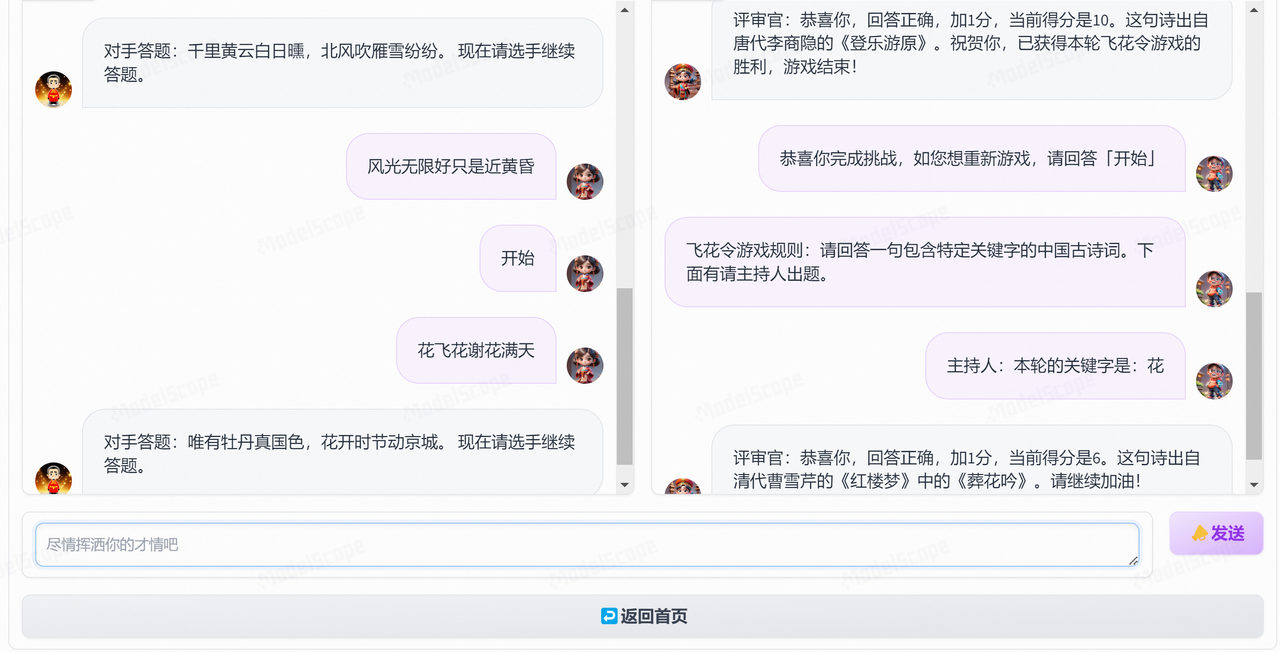
然后,继续查看其他项目的界面设计,发现谜馔:寻找招财猫(千问)这个项目的界面设计和逻辑非常适合“飞花令”这个游戏,主要启发是可以设计两个Chatbot,拿来改造一番,核心代码可参考:./app_game.py。这一版分别设计了两个界面:
- 欢迎界面:介绍游戏规则;这里预留了tab页,用于后续添加更多古诗词游戏类型。
- 这里的游戏logo设计采用了锦书 - 创新艺术字,非常优秀的一个艺术字生成项目。
- 游戏界面:分两栏,左侧Chatbot是答题区-对应的角色是对手Agent和我,右侧Chatbot是系统区-对应的角色是主持人Agent和评审官Agent;同样这里预留了tab页,用于后续添加更多古诗词游戏类型。
Step4:ModelScope部署上线
本地测试成功后,就可以将项目部署到ModelScope了。
这里需要注意的点有:
- 添加环境变量:调用大模型的api_key不要暴露在代码中,可以在环境变量管理中添加:比如我的qwen-max需要设置"DASHSCOPE_API_KEY"。

- 本地安装AgentScope:由于Agentscope目前还在迭代更新中,pip源安装的Agentscope版本是0.0.1,会出现依赖冲突,这里推荐源码安装:
# 在自己的项目代码中
git clone https://github.com/modelscope/agentscope.git
cd AgentScope
rm -rf .git
# 新建app.py, 写入
import os
os.system('pip install -e ./agentscope')
os.system('python app_game.py')
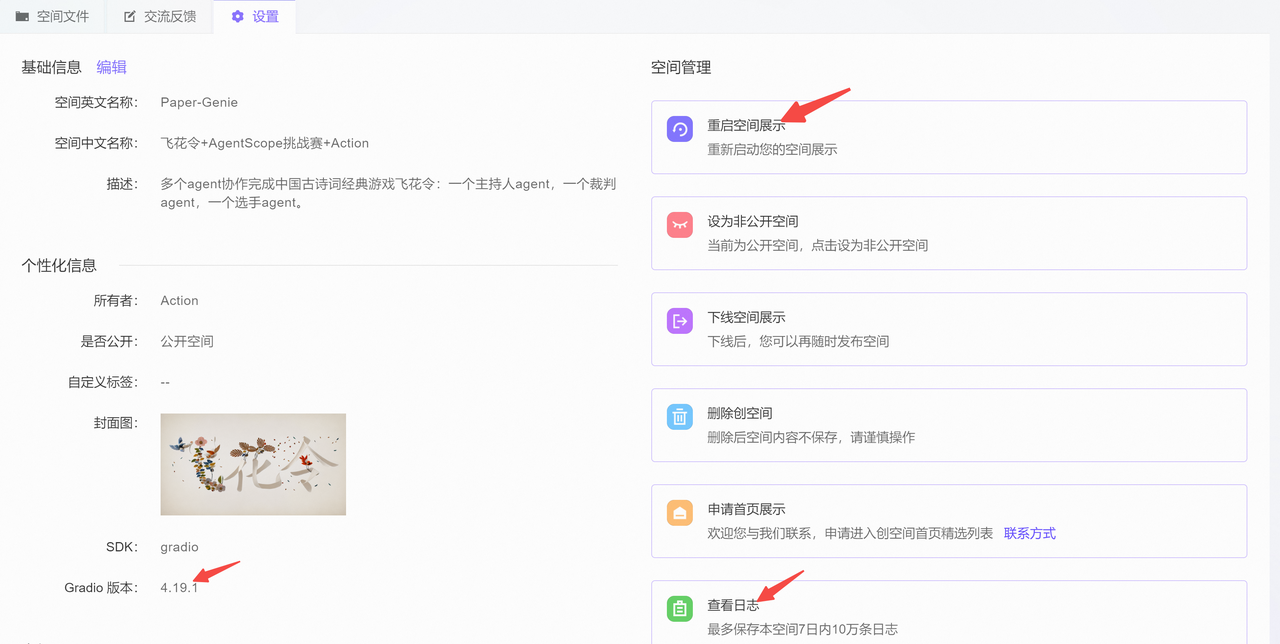
- 启动失败:重启空间展示
- Gradio报错:点击‘查看日志’,如果发现是gradio相关的报错,查看线下gradio版本和云端的是否一致
pip show gradio
4. 未完待续
本项目利用AgentsSope框架,开发了一款和Agent玩飞花令的游戏,充分验证了当前大模型在中国古诗词知识储备方面的能力,未来期待在已有框架的基础上,开发更多的古诗词经典游戏:
- 尾字接龙:根据一句古诗词的末尾的字为关键字,给出以该关键字开头的一句古诗词。
- 即景联诗:由Agent根据一句古诗词画出对应的风景图,用户根据风景图猜出对应的古诗词是啥,最后由Agent做出评审。
- 九宫格:将一句古诗词的文字随机打乱,再加上干扰字,组成一个九宫格,用户根据九宫格猜出其中包含的一句古诗词,最后由Agent做出评审。
此外,还可以尝试: - 利用AgentsSope框架中的tools,接入更多外部API,比如语音合成,提供更多的音色选项,为用户提供更多的游戏体验。
- 增加游戏难度等级,为用户提供更多的激励机制。

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









