







最近 DeepSeek 爆火,不只是在自媒体上!
你看 ollama library 上,上线 8 天,就达到了 3.9 M 下载量,这热度,要甩第二名 llama3.3 好几条街!
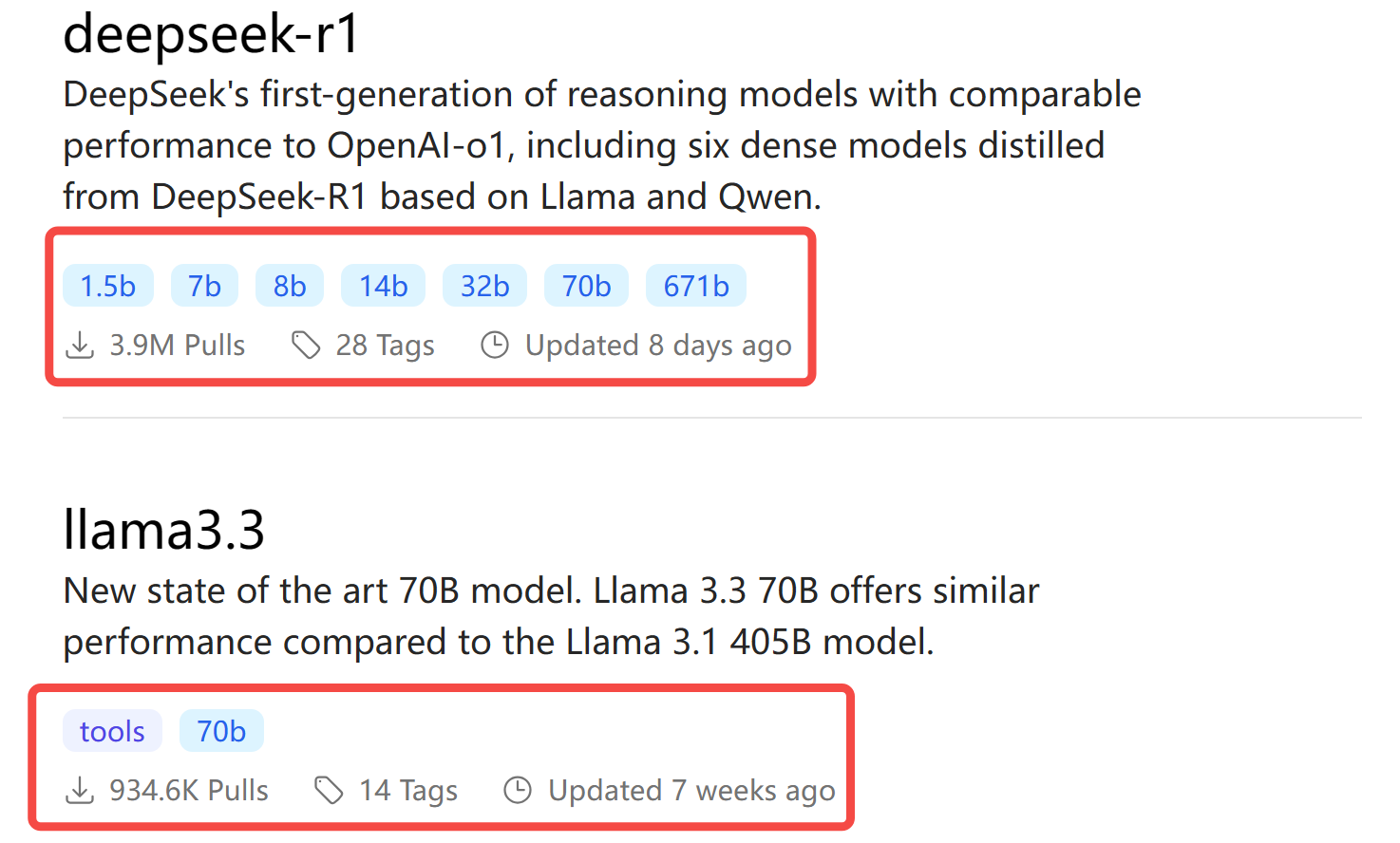
前段时间,官网频繁出现反应迟缓甚至宕机的情况。
不过,这是个开源模型啊,何不本地部署一个,自己用的尽兴。
有朋友问:没有显卡咋跑?
今日分享,带大家用免费 GPU 算力,本地跑 DeepSeek R1 !
1. 腾讯 Cloud Studio
免费算力?
Google Colab?没梯子还真用不了。
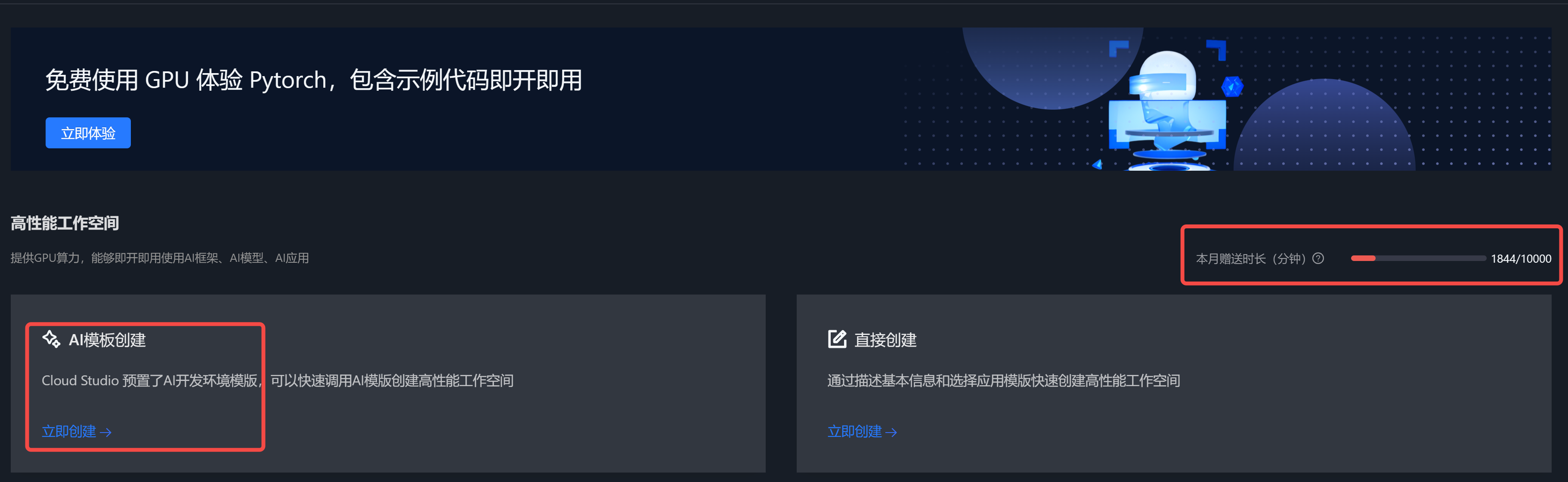
不过,最近腾讯豪横,推出了一款云端 IDE – Cloud Studio,类似百度飞桨 AI Studio 的一款产品。
不过,百度的云端 IDE,你还只能跑PaddlePaddle深度学习开发框架。
这下好,竞品来了,腾讯 Cloud Studio,完全无使用限制,每月可免费使用 1000 分钟!(随用随开,及时关机)
想动手玩玩的盆友,抓紧了~
2. Ollama 跑 DeepSeek
关于 Ollama 的使用,可以翻看之前教程:本地部署大模型?Ollama 部署和实战,看这篇就够了
2.1 创建实例
创建实例时,选择从 AI模板 开始:
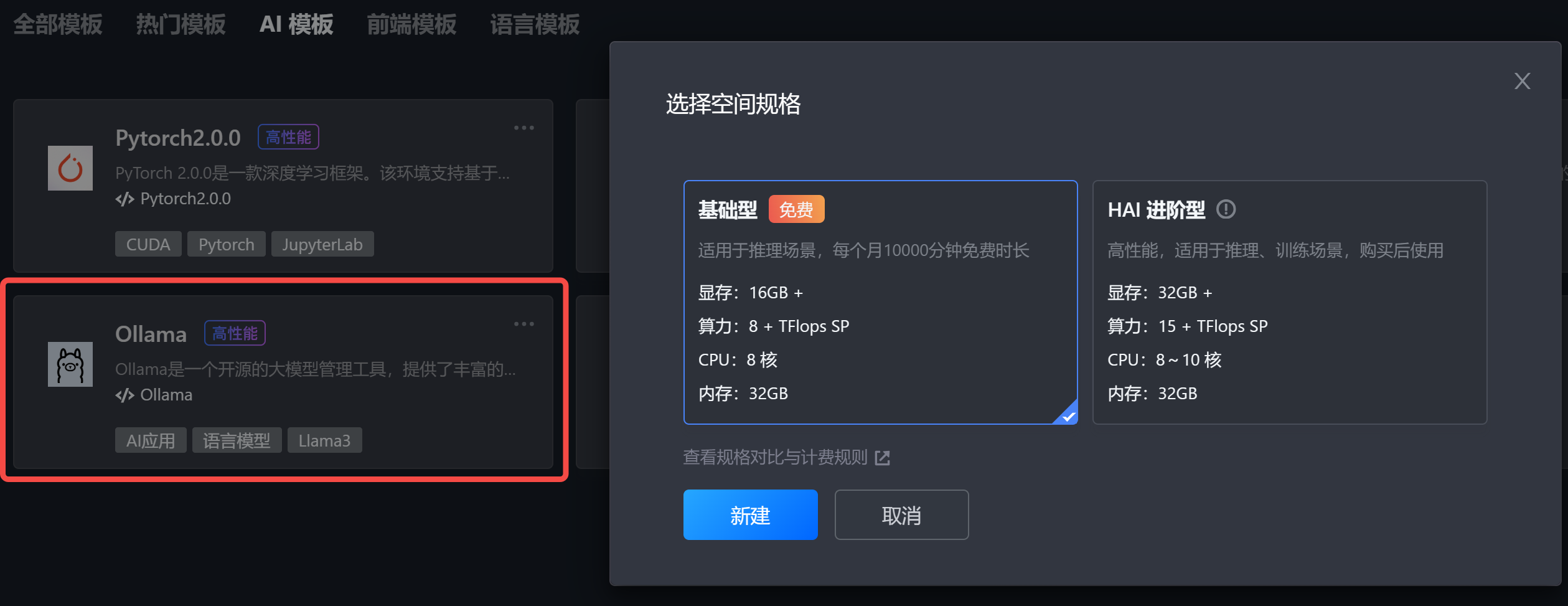
稍等 2 分钟,即可创建成功!
进来后,ctrl+~ 快捷键,打开终端,你看连 conda 虚拟环境都给你装好了~
先来看看给预留了多大存储空间:
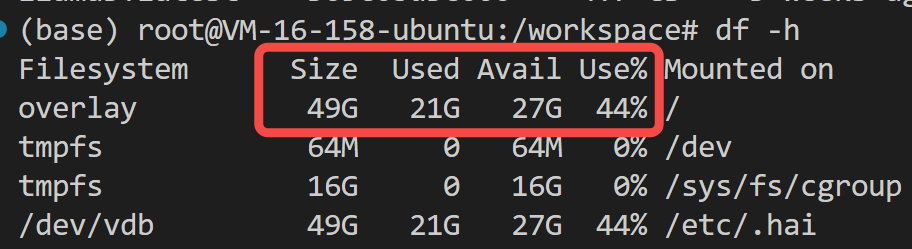
有点遗憾,挂载了不到 50G 的磁盘,系统镜像就占了 21 G,省着点用吧,稍微大点的模型,模型权重都放不下。
内存呢?

32G 内存, Nice ~
再来看看显存啥情况?
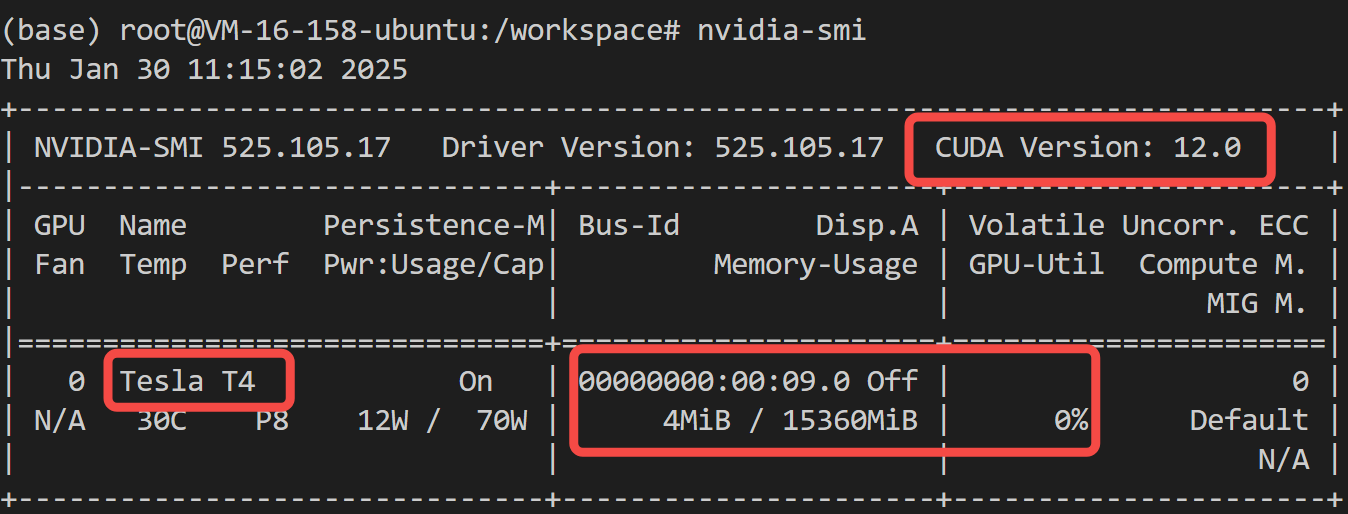
给安排了一张 T4 的推理卡,16G 显存。
2.2 拉取模型权重
最后看看 ollama 啥情况?
(base) root@VM-16-158-ubuntu:/workspace# ollama list
NAME ID SIZE MODIFIED
llama3:latest 365c0bd3c000 4.7 GB 3 weeks ago
预装了 llama 3,删,上主角:DeepSeek R1!
ollama rm llama3
ollama run deepseek-r1:14b
考虑到只有 16G 显存,如果要用 GPU,最大只能选择 14b 模型。
如果下载速度太慢,命令杀掉,重新下载即可!
模型拉取结束,就可以开始玩耍了。
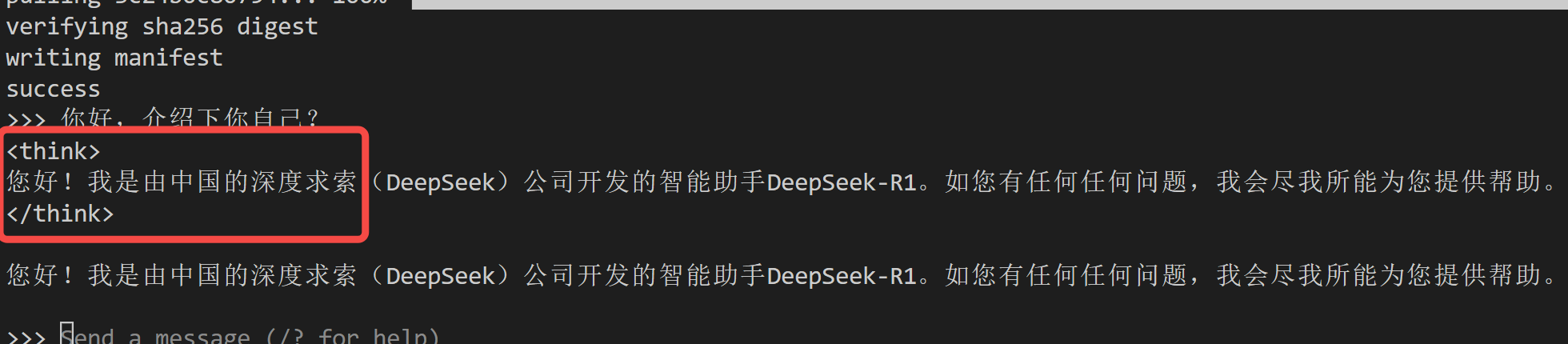
2.3 模型初体验
就这么简单,跑起来了~
再来个复杂点的任务:
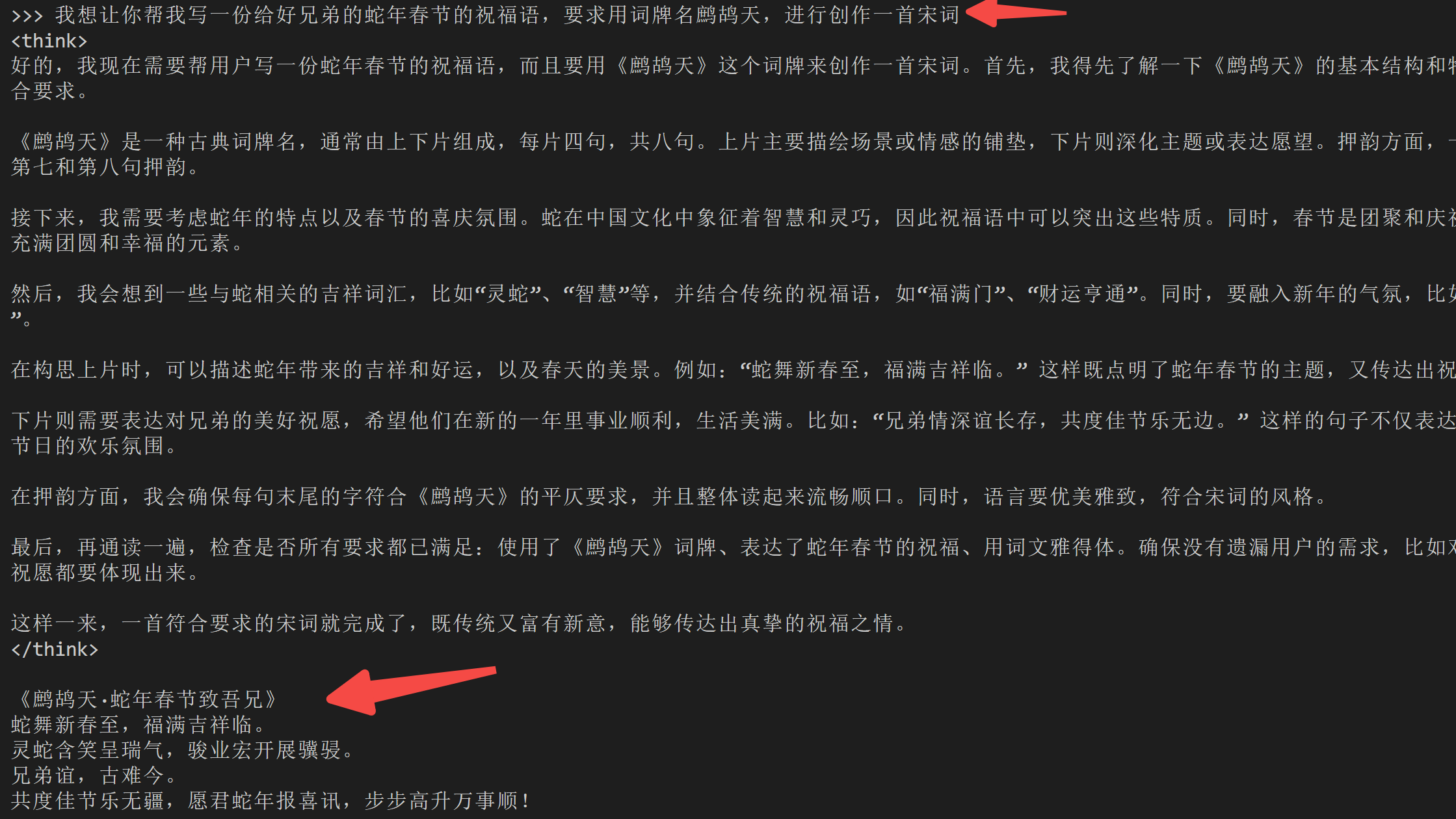
怎么样?
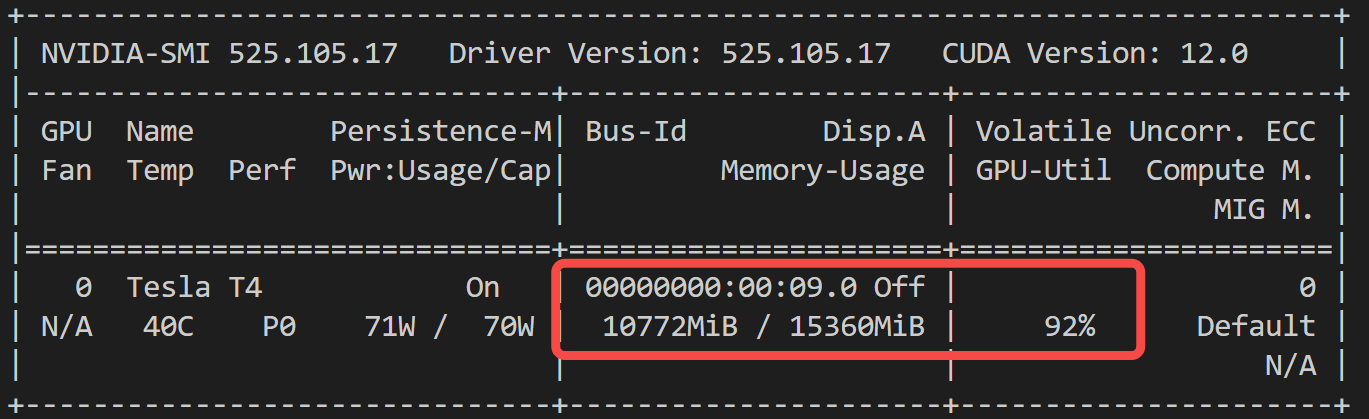
最后,来看下显存占用如何:11 G 足够了。
2.4 内网穿透出来
Cloud Studio 的虚拟机无法安装 docker,所以无法采用 docker 的方式安装 web UI。
且没有公网 IP,咋搞?
总不能每次都得打开终端来用。
这里,介绍一种最简单的内网穿透方法:cloudflared,简单三步搞定!
关于内网穿透,猴哥之前有几篇教程,不了解的小伙伴可以往前翻看。
step 1: 安装 cloudflared:
wget https://mirror.ghproxy.com/https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb
dpkg -i cloudflared-linux-amd64.deb
cloudflared -v
step 2: 查看 ollama 的端口号:
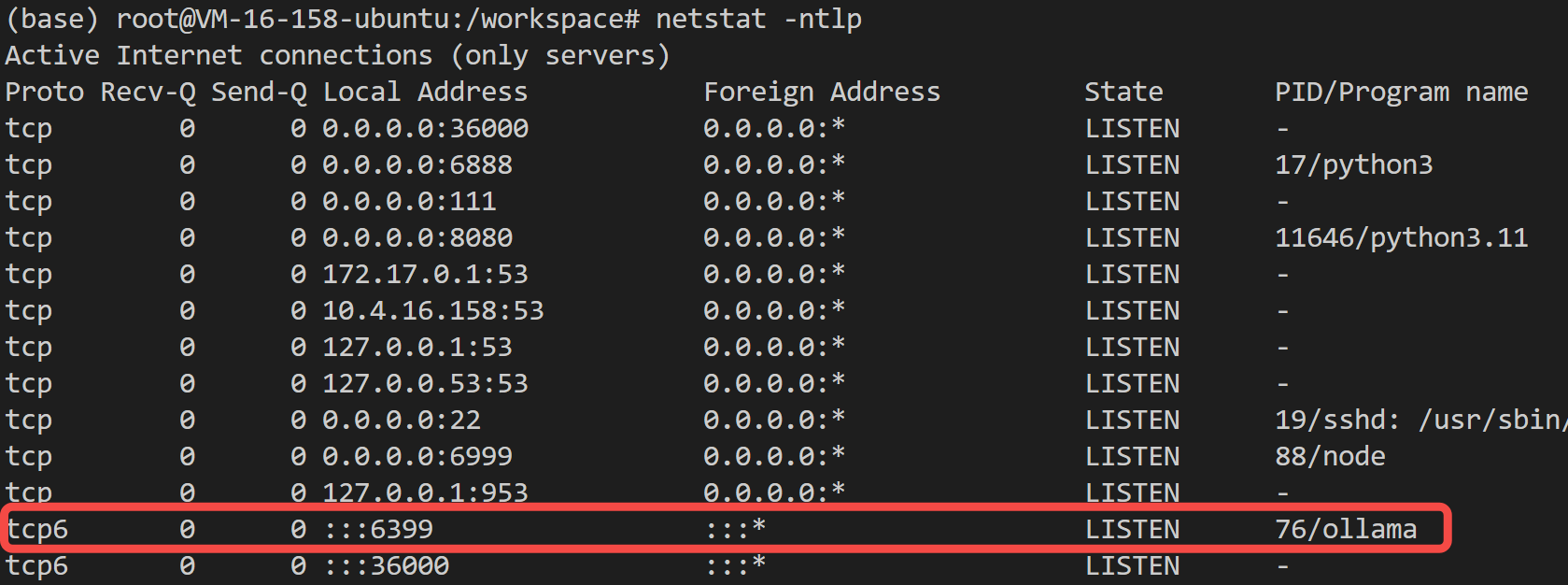
step 3: 穿透出来:
cloudflared tunnel --url http://127.0.0.1:6399
cloudflared 会输出一个公网可访问的链接:
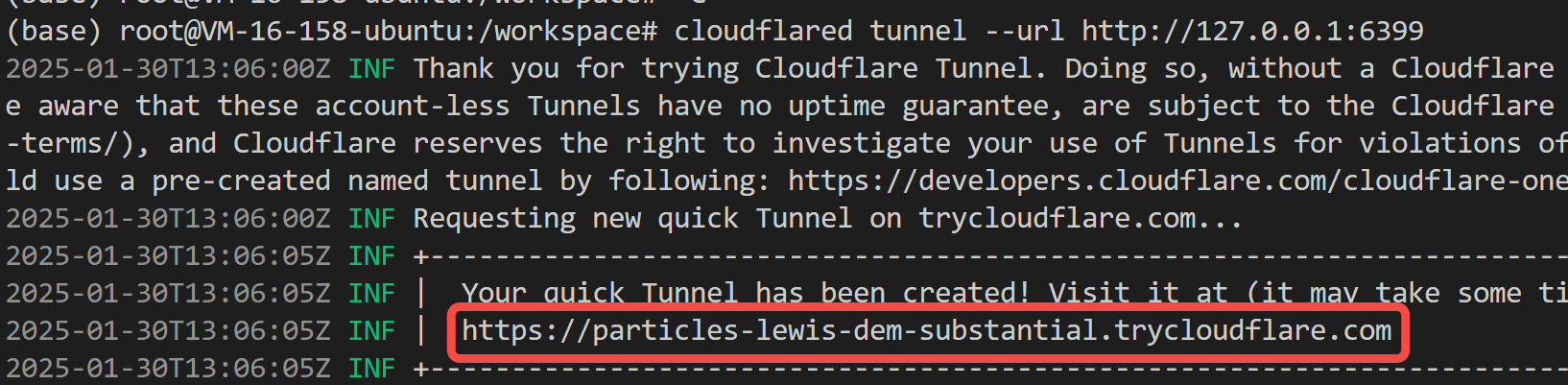
打开浏览器试试吧~

接下来,你可以在本地的任何 UI 界面,用这个 URL 玩耍 DeepSeek-R1 了~
写在最后
本文和大家分享了如何用免费GPU 算力部署 DeepSeek 的推理模型,并内网穿透出来,任性调用。
如果对你有帮助,欢迎点赞收藏备用。
注:DeepSeek-R1 是推理模型,和对话模型不同的是,它多了自我思考的步骤,适合编程、数学等逻辑思维要求高的应用。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









