







 本文深入探讨了Dropout在神经网络中的应用,包括其原理、不同类型的Dropout(如SpatialDropout和VariationalDropout),以及在CNN不同位置使用Dropout的影响。通过在IMDB数据集上的实验,对比了在CNN前、后以及卷积层和池化层之间使用Dropout的效果,揭示了最佳实践。
本文深入探讨了Dropout在神经网络中的应用,包括其原理、不同类型的Dropout(如SpatialDropout和VariationalDropout),以及在CNN不同位置使用Dropout的影响。通过在IMDB数据集上的实验,对比了在CNN前、后以及卷积层和池化层之间使用Dropout的效果,揭示了最佳实践。
一、什么是dropout
dropout是解决神经网络模型过拟合的好办法,那什么是dropout呢?简而言之,它就是随机的将输入的张量中元素置为0,dropout可以理解为一种集成模型。因为我们将元素置为0后,相当于主动抛弃了一部分特征,强迫模型基于不完整的特征进行学习,而每次特征又不一样,所以避免模型过度学习某些特征,得到避免过拟合的效果。我们看如下代码感受下什么是dropout,首先我们有一个输入尺寸为4*6的矩阵,然后对其使用dropout,其中参数0.5为要置为0的元素比例,也可以理解为要丢掉(drop)的元素比例,然后再调用时候记得加上"training=1"这个参数,使其处于训练状态。因为keras中的dropout层只有在训练状态才使用,再预测阶段是不会执行的。完整代码
def normal_dropout():
input_layer = Input(shape=(4, 6), dtype='float')
dropout = Dropout(0.5)(input_layer, training=1)
f = K.function(inputs=[input_layer], outputs=[dropout])
data = np.random.random(size=(4, 6))
result = f([data])
print('before:')
print(data)
print('after:')
print(result[0])执行结果如下,可以看到before下面是输入,after下面是dropout后的结果。那dropout后有什么变化呢?首先,可以清晰的看到有很多元素被置为了0,如果计数的话,0的数量应该占总元素数量的50%,也就是我们设置的参数0.5。另外可以看到第一行第三列元素输入为0.19+,但是经过dropout后值变为0.38+。再仔细看其他没有置0的元素,全部都乘了2。这是为什么呢?这是因为dropout仅在训练时候才使用,在预测阶段是关闭的,如果不将所有剩余元素乘2,做一个rescale的话,训练和预测阶段的数据规模是不一样的。继续看下面这个例子,有50%的元素被置为0,那么剩余所有元素的和相加肯定小于原始输入的,这就出现了一个问题,训练和预测阶段输入数据规模很不一样,所以要乘以(1/0.5)做一个修正。
before:
[[0.93758934 0.57196567 0.1902503 0.60589551 0.91796478 0.35004656]
[0.26774784 0.38095422 0.67994113 0.0130283 0.32857862 0.00616712]
[0.68691713 0.8100105 0.66088479 0.16992333 0.90752647 0.6425508 ]
[0.67713655 0.41954406 0.15749447 0.96562673 0.79455004 0.76805125]]
after:
[[0. 0. 0.3805006 0. 0. 0. ]
[0.5354957 0. 0. 0.0260566 0.65715724 0.01233423]
[0. 0. 1.3217696 0.33984664 0. 0. ]
[1.3542731 0.83908814 0.31498894 0. 0. 1.5361025 ]]二、不同的dropout
2.1 不同的位置
理论上dropour可以加到神经网络层与层之间,或者输出层的前面,比如,这里有两个全连接层
...
model.append(Dense(32))
model.append(Dense(32))
...我们可以把dropout加到两个全连接层之间
...
model.append(Dense(32))
model.append(Dropout(0.5))
model.append(Dense(32))
...
同时dropout还可以加到输入层,直接对输入的数据进行dropout。
我们可以看到dropout基本上可以被加到任何地方,同时还可以设置drop rate,那么问题来了,dropout layer放到哪里合适呢,rate设置成多少合适呢?至于放的位置,很多人认为放到output的前面效果比较好,网络比较复杂的时候推荐使用,那具体放到哪其实也是一门玄学,在下一节我们在IMDB数据上进行实验,看看究竟放到哪里比较合适。至于rate,大家推荐0.2-0.5之间比较好,具体值也是需要调参的(玄学)。
2.2 Spatial Dropout
spatial dropout是对dropout的改进,来自于这篇论文。如下图所示,输入是一个文本的三阶张量,传统的dropout随机将元素置为0,而spatial dropout 每次将一整列元素置为0,这么做的动机是这样的,假设我们的输入是一个图像,图像本身相邻的元素都是高度相关的,我们对这些元素随机置0后,在上面使用一层卷积,得到的结果与不使用dropout相比,其实并不大,因为卷积本身就是提取一个图像局部的特征,你把元素随机置0,卷积层还是能识别出这个局部特征。但是spatial dropout就不一样了,它把没列元素随机置0,保证这个输入发生很大的变化,从而起到正则化的作用。
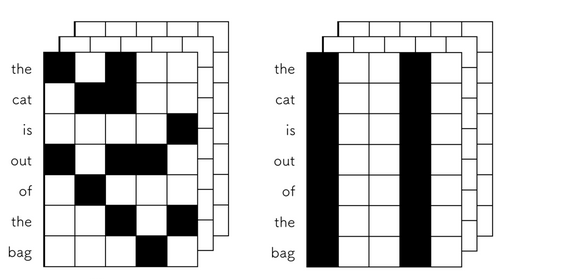
在keras中我们可以直接调用SpatialDropout1D实现这一效果,如下代码,设置rate=0.5。完整代码
def spatial1d_dropout():
input_layer = Input(shape=(4, 6), dtype='float')
dropout = SpatialDropout1D(0.5)(input_layer, training=1)
f = K.function(inputs=[input_layer], outputs=[dropout])
data = np.random.random(size=(1, 4, 6))
result = f([data])
print('before:')
print(data)
print('after:')
print(result[0])
打印的结果如下,我们可以看到在spatial dropout之后,有三列被置为了0,同时剩下的元素都做了rescale。
before:
[[[0.86679474 0.57246349 0.52834759 0.26994444 0.07498533 0.77428166]
[0.70333678 0.28649889 0.30915543 0.29089858 0.15378921 0.0982206 ]
[0.01439577 0.41908501 0.8872668 0.0079067 0.06663811 0.24451797]
[0.75578244 0.47489295 0.81374286 0.7241388 0.86658178 0.08190873]]]
after:
[[[0. 0. 1.0566952 0.53988886 0. 1.5485634 ]
[0. 0. 0.61831087 0.5817972 0. 0.1964412 ]
[0. 0. 1.7745336 0.01581339 0. 0.48903593]
[0. 0. 1.6274858 1.4482776 0. 0.16381747]]]2.3 Variational Dropout
Variational dropout是针对RNN结构一种的改进,来自这篇论文。如下图,左边是普通的dropout,我们关注纵向的箭头就好,这种dropout,会在层与层之间产生作用。variational dropout会在RNN之间发挥作用,也就是右图的横向箭头,RNN单元之间的输入的元素会被随机置0。
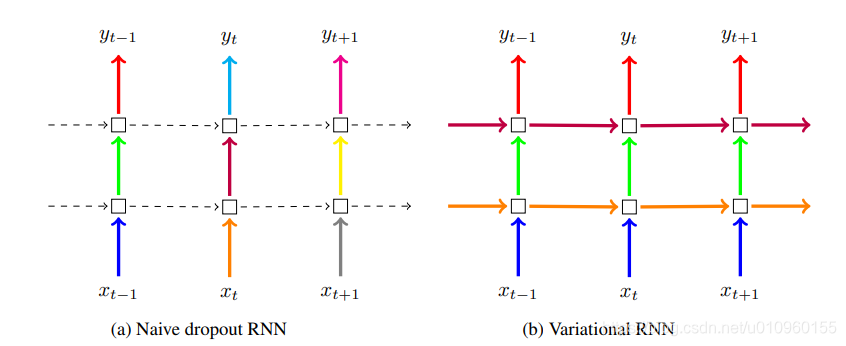
在Keras中,我们也可以直接使用这种dropout, 如下图所示,我们使用了一个LSTM结构,然后看其中的参数,recurrent_dropout指的就是variational dropout,但是由于它是在LSTM之间起作用的,我们就看不到它的效果了。
def variational_dropout():
input_layer = Input(shape=(4, 6), dtype='float')
dropout = LSTM(7, dropout=0.5, recurrent_dropout=0.5, return_sequences=True)\
(input_layer, training=1)
f = K.function(inputs=[input_layer], outputs=[dropout])
data = np.random.random(size=(1, 4, 6))
result = f([data])
print('before:')
print(data)
print('after:')
print(result[0])三 在什么位置加dropout
我们在IMDB数据集上进行实验,看看究竟在哪里加上dropout效果最好,首先先上没有dropout的代码:
# Build model
sentence = Input(batch_shape=(None, max_words), dtype='int32', name='sentence')
embedding_layer = Embedding(top_words, embedding_dims, input_length=max_words)
sent_embed = embedding_layer(sentence)
conv_layer = Conv1D(filters, kernel_size, padding='valid', activation='relu')
sent_conv = conv_layer(sent_embed)
sent_pooling = GlobalMaxPooling1D()(sent_conv)
sent_repre = Dense(250)(sent_pooling)
sent_repre = Activation('relu')(sent_repre)
sent_repre = Dense(1)(sent_repre)
pred = Activation('sigmoid')(sent_repre)
model = Model(inputs=sentence, outputs=pred)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])以上代码是一个经典的CNN网络,我们没有加入任何的dropout,它的结果如下
25000/25000 [==============================] - 44s 2ms/step - loss: 0.3442 - acc: 0.8414 - val_loss: 0.2847 - val_acc: 0.8780
Epoch 2/2
25000/25000 [==============================] - 40s 2ms/step - loss: 0.1591 - acc: 0.9393 - val_loss: 0.2704 - val_acc: 0.8951
Accuracy: 89.51%3.1 在CNN前加入dropout
我们在卷积之前加一层dropout,相当于抛弃embedding的某些值,让我们看看会发生什么
sent_embed = embedding_layer(sentence)
sent_embed = Dropout(0.5)(sent_embed)
conv_layer = Conv1D(filters, kernel_size, padding='valid', activation='relu')
sent_conv = conv_layer(sent_embed)跑出的结果如下,加了dropout后准确率增加了0.22(因为神经网络随机性,每次结果会不一样,我们只取一次实验的结果,有可能不具备代表性) 。看来在CNN前加dropout还是有点作用。
25000/25000 [==============================] - 52s 2ms/step - loss: 0.3914 - acc: 0.8052 - val_loss: 0.2718 - val_acc: 0.8854
Epoch 2/2
25000/25000 [==============================] - 50s 2ms/step - loss: 0.2229 - acc: 0.9090 - val_loss: 0.2543 - val_acc: 0.8973
Accuracy: 89.73%
3.2 在CNN前加入spatial dropout
# Build model
sentence = Input(batch_shape=(None, max_words), dtype='int32', name='sentence')
embedding_layer = Embedding(top_words, embedding_dims, input_length=max_words)
sent_embed = embedding_layer(sentence)
sent_embed = SpatialDropout1D(0.5)(sent_embed)
conv_layer = Conv1D(filters, kernel_size, padding='valid', activation='relu')
sent_conv = conv_layer(sent_embed)
sent_pooling = GlobalMaxPooling1D()(sent_conv)
sent_repre = Dense(250)(sent_pooling)
sent_repre = Activation('relu')(sent_repre)
sent_repre = Dense(1)(sent_repre)
pred = Activation('sigmoid')(sent_repre)
model = Model(inputs=sentence, outputs=pred)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])我们可以看到准确率达到了89.81,比使用普通的dropout效果要好一些
25000/25000 [==============================] - 53s 2ms/step - loss: 0.3945 - acc: 0.8051 - val_loss: 0.2791 - val_acc: 0.8830
Epoch 2/2
25000/25000 [==============================] - 42s 2ms/step - loss: 0.2236 - acc: 0.9106 - val_loss: 0.2502 - val_acc: 0.8981
Accuracy: 89.81%
3.3 在卷积层和池化层之间加入dropout
我们在卷积层和池化层之间加入dropout,看看会发生什么
conv_layer = Conv1D(filters, kernel_size, padding='valid', activation='relu')
sent_conv = conv_layer(sent_embed)
sent_conv = Dropout(0.5)(sent_conv)
sent_pooling = GlobalMaxPooling1D()(sent_conv)发型准确率下降了不少 ,猜测是drop rate 太高了,把重要的特征也抛弃了
25000/25000 [==============================] - 33s 1ms/step - loss: 0.3557 - acc: 0.8353 - val_loss: 0.3068 - val_acc: 0.8811
Epoch 2/2
25000/25000 [==============================] - 31s 1ms/step - loss: 0.2052 - acc: 0.9182 - val_loss: 0.2938 - val_acc: 0.8782
Accuracy: 87.82%
在这里调小drop rate = 0.2
sent_conv = conv_layer(sent_embed)
sent_conv = Dropout(0.2)(sent_conv)
sent_pooling = GlobalMaxPooling1D()(sent_conv)看到准确率有所提升,但是跟没加dropout之间没啥差距,甚至还将了一点
25000/25000 [==============================] - 35s 1ms/step - loss: 0.3476 - acc: 0.8392 - val_loss: 0.2741 - val_acc: 0.8863
Epoch 2/2
25000/25000 [==============================] - 32s 1ms/step - loss: 0.1744 - acc: 0.9327 - val_loss: 0.2539 - val_acc: 0.8937
Accuracy: 89.37%
3.4 在pooling层之后加入dropout
sentence = Input(batch_shape=(None, max_words), dtype='int32', name='sentence')
embedding_layer = Embedding(top_words, embedding_dims, input_length=max_words)
sent_embed = embedding_layer(sentence)
conv_layer = Conv1D(filters, kernel_size, padding='valid', activation='relu')
sent_conv = conv_layer(sent_embed)
sent_pooling = GlobalMaxPooling1D()(sent_conv)
sent_repre = Dense(250)(sent_pooling)
sent_repre = Activation('relu')(sent_repre)
sent_repre = Dropout(0.2)(sent_repre)
sent_repre = Dense(1)(sent_repre)
pred = Activation('sigmoid')(sent_repre)
model = Model(inputs=sentence, outputs=pred)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])发现准确率有略微的提升,但不是太多
25000/25000 [==============================] - 35s 1ms/step - loss: 0.3501 - acc: 0.8364 - val_loss: 0.3201 - val_acc: 0.8628
Epoch 2/2
25000/25000 [==============================] - 34s 1ms/step - loss: 0.1677 - acc: 0.9370 - val_loss: 0.2593 - val_acc: 0.8959
Accuracy: 89.59%
一些结论
通过在IMDB数据集上的实验,我们可以看出,dropout加在哪,drop rate设置多少都会影响最终的结果。而在IMDB数据集上我们发现dropout加在CNN之前,和CNN之后都是有作用的,都能带来准确率的提升。特别是在CNN之前使用spatial dropout,比传统的dropout效果要好。而在卷积层和池化层之间加dropout反而没什么效果,可能与我们的网络太简单有关系。
Reference
https://machinelearningmastery.com/how-to-reduce-overfitting-with-dropout-regularization-in-keras/

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









