







数据集简介
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上自动驾驶场景下常用的数据集之一。KITTI数据集的数据采集平台装配有2个灰度摄像机,2个彩色摄像机,一个Velodyne 64线3D激光雷达,4个光学镜头,以及1个GPS导航系统。
官网 国内下载地址1 国内下载地址2
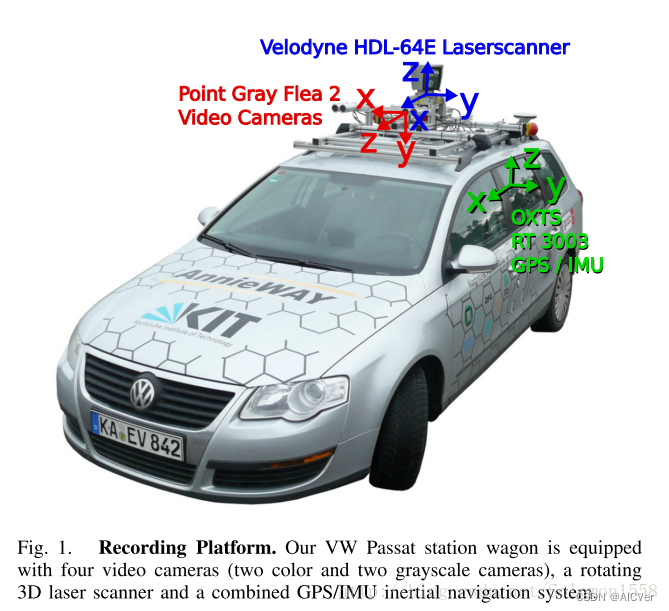
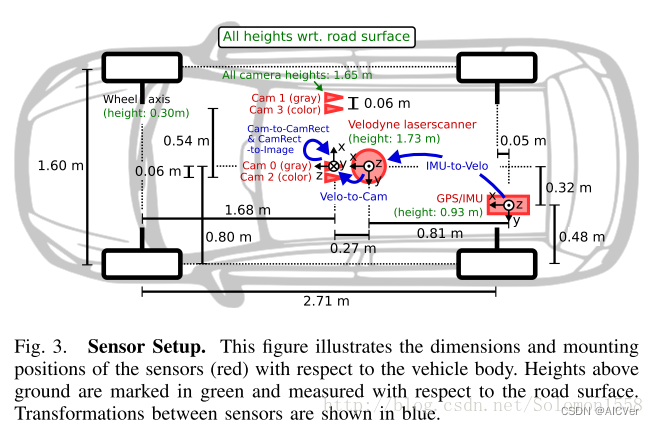
为了生成双目立体图像,相同类型的摄像头相距54cm安装。由于彩色摄像机的分辨率和对比度不够好,所以还使用了两个立体灰度摄像机,它和彩色摄像机相距6cm安装。为了方便传感器数据标定,规定坐标系方向如下[2] :
• Camera: x = right, y = down, z = forward
• Velodyne: x = forward, y = left, z = up
• GPS/IMU: x = forward, y = left, z = up
Dataset详解
文件组织形式

- calib:相机标定参数,可根据参数将2D、3D数据坐标进行转换
- image2: 左侧彩色相机图像数据
- veloyne:雷达点云数据
- label2:对应文件标签
calib标定校准文件解析
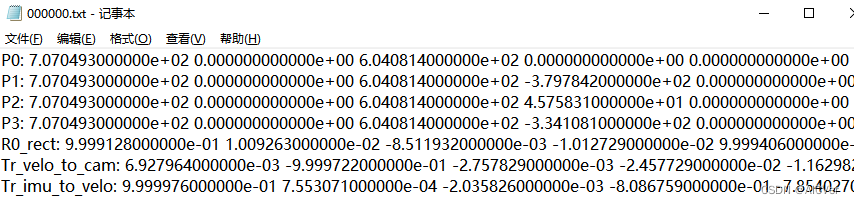
- 内参矩阵: P0-P3分别表示4个相机(左边灰度相机、右边灰度相机、左边彩色相机和右边彩色相机)的内参矩阵,或投影矩阵, 大小为 3x4。相机内参矩阵是为了计算点云空间位置坐标在相机坐标系下的坐标,即把点云坐标投影到相机坐标系。将相机的内参矩阵乘以点云在世界坐标系中的坐标即可得到点云在相机坐标系中的坐标。
- 校准矩阵: R0_rect 为0号相机的修正矩阵,大小为3x3,目的是为了使4个相机成像达到共面的效果,保证4个相机光心在同一个xoy平面上。在进行外参矩阵变化之后,需要于R0_rect相乘得到相机坐标系下的坐标。
- 外参矩阵:根据上述介绍,我们知道存在三种坐标系世界坐标系、相机坐标系、激光雷达坐标系。世界坐标系反映了物体的真实位置坐标,也是作为相机坐标系和激光雷达坐标系之间相互变换的过渡坐标系。点云位置坐标投影到相机坐标系前,需要转换到世界坐标系下,对应的矩阵为外参矩阵。外参矩阵为Tr_velo_to_cam ,大小为3x4,包含了旋转矩阵 R 和 平移向量 T。将相机的外参矩阵乘以点云坐标即可得到点云在世界坐标系中的坐标。
- 综上所述,点云坐标在相机坐标系中的坐标等于
相机坐标 = 内参矩阵 * 外参矩阵 * R0校准矩阵 * 点云坐标
例如要将Velodyne激光雷达坐标系中的点x投影到左侧的彩色图像中y,使用公式:
y = P2 * R0_rect *Tr_velo_to_cam * x - 激光雷达坐标转换图像像素坐标代码
def velodyne2img(calib_dir, img_id, velo_box): """ :param calib_dir: calib文件的地址 :param img_id: 要转化的图像id :param velo_box: (n,8,4),要转化的velodyne frame下的坐标,n个3D框,每个框的8个顶点,每个点的坐标(x,y,z,1) :return: (n,4),转化到 image frame 后的 2D框 的 x1y1x2y2 """ # 读取转换矩阵 calib_txt=os.path.join(calib_dir, img_id) + '.txt' calib_lines = [line.rstrip('\n') for line in open(calib_txt, 'r')] for calib_line in calib_lines: if 'P2' in calib_line: P2=calib_line.split(' ')[1:] P2=np.array(P2, dtype='float').reshape(3,4) elif 'R0_rect' in calib_line: R0_rect=np.zeros((4,4)) R0=calib_line.split(' ')[1:] R0 = np.array(R0, dtype='float').reshape(3, 3) R0_rect[:3,:3]=R0 R0_rect[-1,-1]=1 elif 'velo_to_cam' in calib_line: velo_to_cam = np.zeros((4, 4)) velo2cam=calib_line.split(' ')[1:] velo2cam = np.array(velo2cam, dtype='float').reshape(3, 4) velo_to_cam[:3,:]=velo2cam velo_to_cam[-1,-1]=1 tran_mat=P2.dot(R0_rect).dot(velo_to_cam) # 3x4 velo_box=velo_box.reshape(-1,4).T img_box = np.dot(tran_mat, velo_box).T img_box=img_box.reshape(-1,8,3) img_box[:,:,0]=img_box[:,:,0]/img_box[:,:,2] img_box[:, :, 1] = img_box[:, :, 1] / img_box[:, :, 2] img_box=img_box[:,:,:2] # (n,8,2) x1y1=np.min(img_box,axis=1) x2y2 = np.max(img_box, axis=1) result =np.hstack((x1y1,x2y2)) #(n,4) return result - 各个转换
设 y为 激光雷达坐标写下的点 (x,y,z,r)-
Tr_velo_to_cam * y : 把激光雷达坐标系下的点y投影到相机坐标系
-
R0_rect * Tr_velo_to_cam * y: 将激光雷达坐标系下的点投影到编号为2的相机坐标系,结果为(x,y,z,1),直接取前三个为投影结果,当计算出z<0的时候表明该点在相机的后面 。标注文件中的中心坐标即是相机2下的坐标系。
-
P2 * R0_rect * Tr_velo_to_cam * y:将激光雷达坐标系下的点投影到编号为2的相机采集的图像中,结果形式为(u,v,w)。 Ps:u,w需要除以w后取整才是最终的像素。
-
标注文件解析
标注文件中16个属性,即16列。但我们只能够看到前15列数据,因为第16列是针对测试场景下目标的置信度得分,也可以认为训练场景中得分全部为1但是没有专门标注出来。
- 目标类比别(type),共有8种类别,分别是Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc或’DontCare。DontCare表示某些区域是有目标的,但是由于一些原因没有做标注,比如距离激光雷达过远。但实际算法可能会检测到该目标,但没有标注,这样会被当作false positive (FP)。这是不合理的。用DontCare标注后,评估时将会自动忽略这个区域的预测结果,相当于没有检测到目标,这样就不会增加FP的数量了。此外,在 2D 与 3D Detection Benchmark 中只针对 Car、Pedestrain、Cyclist 这三类。
- 截断程度(truncated),表示处于边缘目标的截断程度,取值范围为0~1,0表示没有截断,取值越大表示截断程度越大。处于边缘的目标可能只有部分出现在视野当中,这种情况被称为截断。
- 遮挡程度(occlude),取值为(0,1,2,3)。0表示完全可见,1表示小部分遮挡,2表示大部分遮挡,3表示未知(遮挡过大)。
- 观测角度(alpha),取值范围为(-pi, pi)。是在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角。这相当于将物体中心旋转到正前方后,计算其与车身方向的夹角。
- 第5-8列:二维检测框(bbox),目标二维矩形框坐标,分别对应left、top、right、bottom,即左上(xy)和右下的坐标(xy)。
- 第9-11列:三维物体的尺寸(dimensions),分别对应高度、宽度、长度,以米为单位。
- 第12-14列:中心坐标(location),三维物体底部中心在相机坐标系下的位置坐标(x,y,z),单位为米。
- 第15列:旋转角(rotation_y),取值范围为(-pi, pi)。表示车体朝向,绕相机坐标系y轴的弧度值,即物体前进方向与相机坐标系x轴的夹角。rolation_y与alpha的关系为alpha=rotation_y - theta,theta为物体中心与车体前进方向上的夹角。alpha的效果是从正前方看目标行驶方向与车身方向的夹角,如果物体不在正前方,那么旋转物体或者坐标系使得能从正前方看到目标,旋转的角度为theta。
- 第16列:置信度分数(score),仅在测试评估的时候才需要用到。置信度越高,表示目标越存在的概率越大。
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











