







基于翻筋斗觅食策略的灰狼优化算法
摘要: 灰狼优化算法(grey wolf optimization,GWO)存在收敛的不合理性等缺陷,目前对 GWO 的收敛性改进方式较少,除此之外,在 GWO 迭代至后期,所有灰狼个体都逼近 α 狼、β 狼、δ 狼,导致算法陷入局部最优。为针对以上问题,提出了一种增强型的灰狼优化算法(disturbance and somersault foraging-grey wolf optimization,DSF-GWO),该算法首先引入了一种扰动因子,平衡了算法的开采和勘探能力;其次又引入翻筋斗觅食策略,在后期使其不陷入局部最优的同时也使得前期的群体多样性略有提升。
1.灰狼优化算法
基础灰狼优化算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/107716390
2.改进 GWO
2.1动态扰动因子策略
在原始 GWO 算法中,开采与勘探的过渡是由 H 决定的,也就是由收敛因子 a 决定,
∣
H
∣
>
1
|H|>1
∣H∣>1时,狼群进行全局搜索,扩大勘探范围的同时增强其全局性;
∣
H
∣
<
1
|H|<1
∣H∣<1 时狼群进行局部搜索,提高局部搜索效率。然而缺点是 a 的前半段与后半段下降幅度是相同的,导致无法在前期更好的全局搜索,而后期无法更有效的进行局部搜索,这在处理复杂优化问题的时候会显露弊端,大多数情况不能保证全局最优解在收敛的末端出现,会出现早熟收敛和后期陷入局部最优的情形。关于 a 的改进一般为变线性为非线性,使前期的 a 平稳过渡,增强全局勘探能力,后期 a 急速下降呈陡崖状,增强其局部开采能力。本文将引入新的动态扰动因子策略以确保精度,扰动因子 E如式(9),更新后的 H 如式(10)。
E
=
randn
⋅
(
sin
ω
(
π
2
⋅
t
t
max
)
+
cos
(
π
2
⋅
t
t
max
)
−
1
)
(9)
E=\operatorname{randn} \cdot\left(\sin ^{\omega}\left(\frac{\pi}{2} \cdot \frac{t}{t_{\max }}\right)+\cos \left(\frac{\pi}{2} \cdot \frac{t}{t_{\max }}\right)-1\right) \tag{9}
E=randn⋅(sinω(2π⋅tmaxt)+cos(2π⋅tmaxt)−1)(9)
H = a ( 2 ρ 1 − 1 ) + E (10) H=a\left(2 \rho_{1}-1\right)+E\tag{10} H=a(2ρ1−1)+E(10)
式(9)中 randn 代表服从高斯正态分布的随机数, ω \omega ω代表某一常数,它决定了扰动因子峰值的位置。
2.2 翻筋斗觅食策略
由于灰狼优化算法后期易陷入局部最优,针对这个问题受到文献的启发,通过蝠鲼觅食会突然翻身捕捉浮游生物,引入较为新颖的翻筋斗觅食策略来改善 GWO 的跳出局部最优能力。这种捕猎行为,可以将猎物视为一个支点,每次捕猎将会更新到当前位置与对称于支点对面位置的某一位置,数学模型可列为式(11)。
x
i
d
(
t
+
1
)
=
x
i
d
(
t
)
+
S
⋅
(
r
1
⋅
x
best
d
−
r
2
⋅
x
i
d
(
t
)
)
,
i
=
1
,
⋯
,
N
(11)
x_{i}^{d}(t+1)=x_{i}^{d}(t)+S \cdot\left(r_{1} \cdot x_{\text {best }}^{d}-r_{2} \cdot x_{i}^{d}(t)\right), i=1, \cdots, N \tag{11}
xid(t+1)=xid(t)+S⋅(r1⋅xbest d−r2⋅xid(t)),i=1,⋯,N(11)
式(11)中
s
s
s代表空翻因子,决定了翻到猎物对面的位置,取
S
=
2
S =2
S=2,
x
b
e
s
t
d
x^d_{best}
xbestd为猎物位置,
N
N
N 为狼群数量,
d
d
d 为维度,
r
1
,
r
2
r_1,r_2
r1,r2为两个区间为[0,1]的随机数。
DSF-GWO 算法步骤如下:
a) 初始化狼群参数,包括灰狼种群
N
N
N ,最大迭代次数
t
m
a
x
t_{max}
tmax,空间维度
d
i
m
dim
dim ,搜索空间的上下限
u
b
ub
ub 和
l
b
lb
lb 。
b) 计算狼群个体适应度值并确定
α
,
β
,
δ
\alpha,\beta,\delta
α,β,δ。
c) 通过式(3)更新参数
C
C
C ,(10)更新添加扰动因子的参数
H
H
H。
d) 根据式(5)至(7)更新狼群位置,通过式(8)更新猎物位置。
e) 判断条件
t
/
t
m
a
x
t/t_{max}
t/tmax是否大于
r
a
n
d
rand
rand,是则根据式(11)进行翻筋斗计算,然后合并比较,通过升序筛选出新适应度值,否则直接跳至步驟 f)。
f) 跳到步驟 b)直到满足终止条件,即计算到最大迭代次数
t
m
a
x
t_{max}
tmax。
g) 输出最优解 α \alpha α狼的位置。
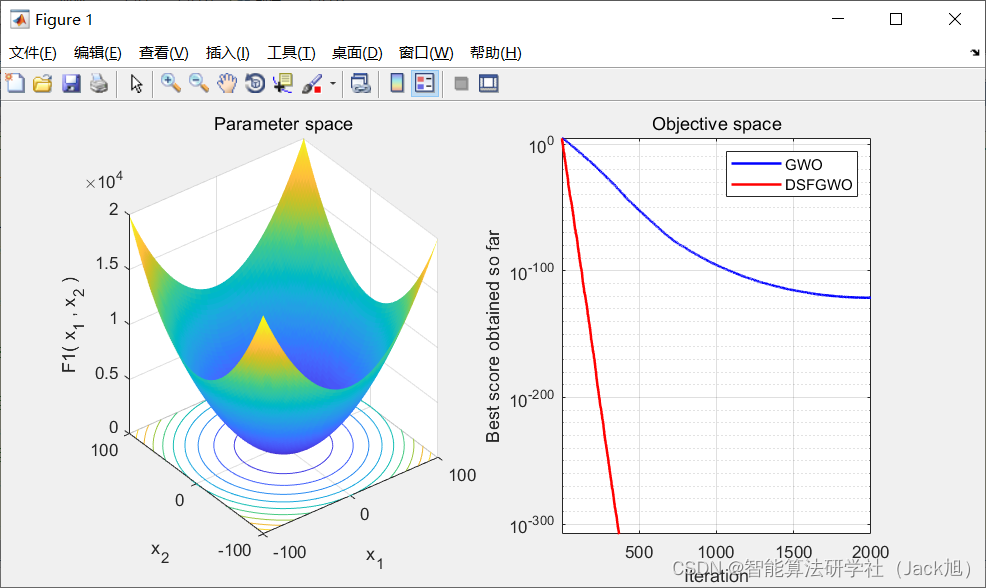
3.实验结果
4.参考文献
[1]王正通,程凤芹,尤文,李双.基于翻筋斗觅食策略的灰狼优化算法[J/OL].计算机应用研究:1-5[2021-02-01].https://doi.org/10.19734/j.issn.1001-3695.2020.04.0102.

















 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











