




 本文详细解析了图注意力网络(GAT)的基本原理与实现,包括计算注意力系数、特征加权求和等步骤,并对比了GAT与图卷积网络(GCN)的优缺点,阐述了GAT在处理动态图和有向图问题上的优势。
本文详细解析了图注意力网络(GAT)的基本原理与实现,包括计算注意力系数、特征加权求和等步骤,并对比了GAT与图卷积网络(GCN)的优缺点,阐述了GAT在处理动态图和有向图问题上的优势。
文章目录
GCN结合邻近节点特征的方式和图的结构依依相关,这也给GCN带来了几个问题:
- 无法完成inductive任务,即处理动态图问题。inductive任务是指:训练阶段与测试阶段需要处理的graph不同。通常是训练阶段只是在子图(subgraph)上进行,测试阶段需要处理未知的顶点。(unseen node)
- 处理有向图的瓶颈,不容易实现分配不同的学习权重给不同的neighbor。
于是,Bengio等人在ICLR 2018上提出了图注意力(GAT)模型,论文详见:Graph Attention Networks
1. GAT基本原理
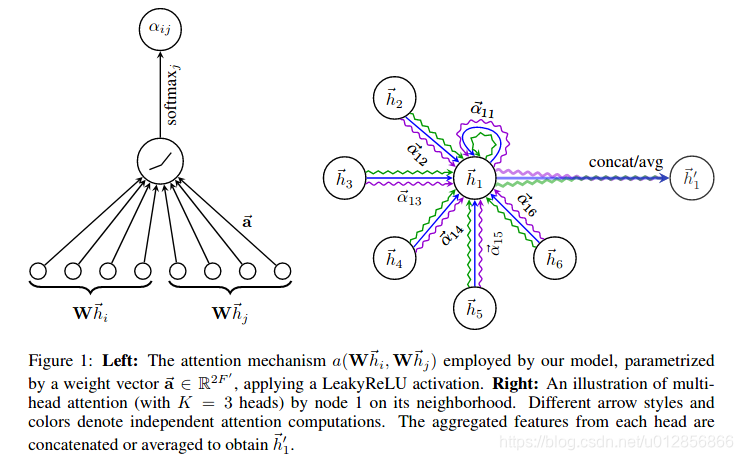
结合上图,GAT的核心思想就是针对节点 i i i和节点 j j j , GAT首先学习了他们之间的注意力权重 a i , j a_{i,j} ai,j(如左图所示);然后,基于注意力权重 { a 1 , . . . , a 6 } \{a_1, ... , a_6\} { a1,...,a6<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2157
2157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









