








- 论文题目:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
- 发布期刊:CVPR
- 作者地址:1牛津大学、2中山大学、3国防科学技术大学
- 代码地址:https://github.com/QingyongHu/RandLA-Net
介绍
这篇论文题为《RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds》,研究了大规模3D点云高效语义分割的问题。当前的许多方法依赖于复杂的采样技术或计算量大、内存消耗高的预处理和后处理步骤,因此只能处理小规模的点云数据。为了应对这一挑战,作者提出了一种新的轻量级神经网络架构RandLA-Net,能够直接处理大规模点云,进行逐点的语义推断。
RandLA-Net的关键创新在于采用随机点采样(Random Point Sampling),而不是复杂的点选择方法。尽管随机采样在计算和内存效率上有明显优势,但可能会随机丢弃重要的特征。为此,作者引入了一种新的局部特征聚合模块(Local Feature Aggregation),通过逐渐增大每个3D点的感受野,保留几何细节,从而有效地解决这个问题。
论文的主要贡献包括:
- 分析并比较了现有的采样方法,指出随机采样是最适合大规模点云处理的方式。
- 提出了一种有效的局部特征聚合模块,能够通过逐步增加每个点的感受野来保留复杂的局部结构。
- 通过实验表明,RandLA-Net在处理1百万个点时速度比现有方法快200倍,并且在多个大规模基准数据集(如Semantic3D和SemanticKITTI)上超越了现有的语义分割方法。
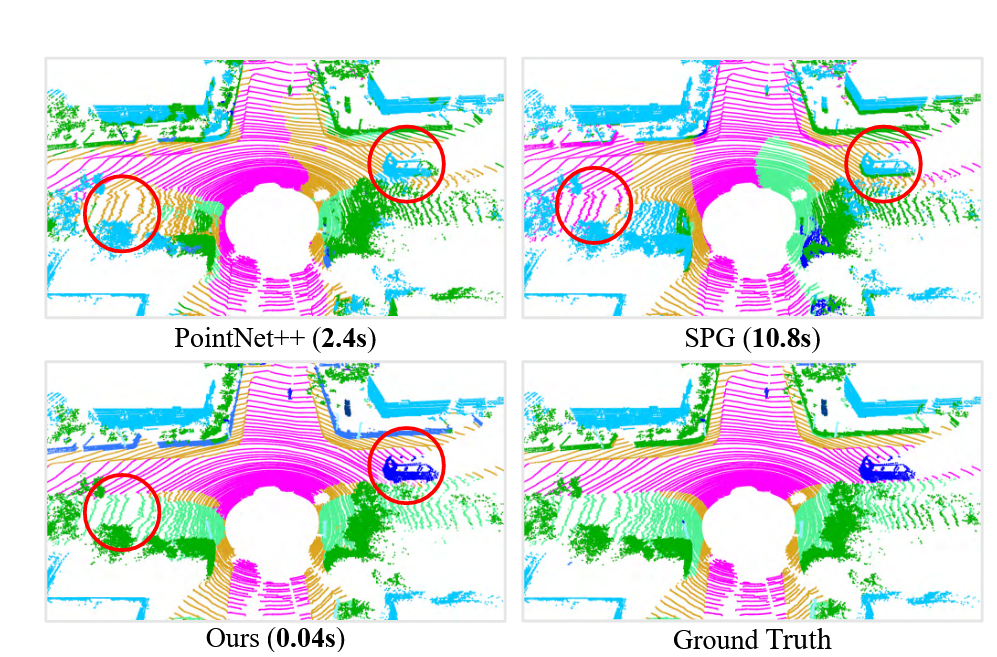
图 PointNet++、SPG和在 SemanticKITTI上的方法的语义分割结果。 RandLA-Net 只需 0.04 秒即可直接处理 3D 空间中超过 150×130×10 米的 105 个点的大型点云,比 SPG 快 200 倍。红色圆圈突出了我们的方法卓越的分割准确性。
核心思想及其实现
RandLA-Net的核心思想是通过随机点采样和局部特征聚合模块来高效处理大规模点云数据,进行语义分割。其设计目标是在保持计算和内存效率的同时,尽量保留点云的几何细节和语义信息。以下是RandLA-Net的核心思想及其实现步骤:
主要贡献
- 随机采样:提供了高效的点云采样方案,显著减少了计算和内存开销。
- 局部特征聚合模块:通过扩展感受野和注意力机制,有效保留了局部几何信息,增强了语义分割的准确性。
- 高效的端到端语义分割:在不需要复杂的预处理/后处理的情况下实现了大规模点云的高效分割。
核心思想
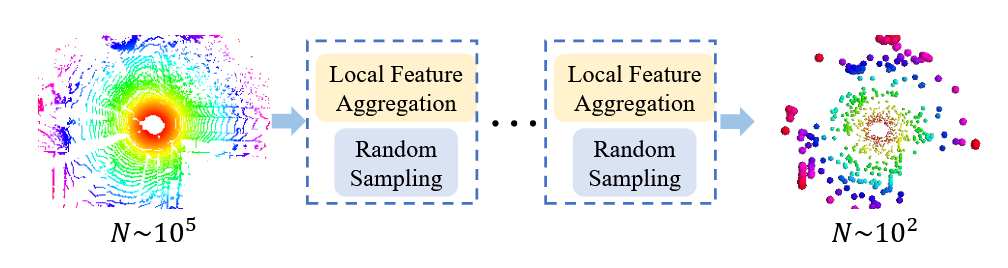
图 在 RandLA-Net 的每一层中,大规模点云都被显着下采样,但仍能够保留精确分割所需的特征。
- 随机采样(Random Sampling):RandLA-Net采用简单且高效的随机采样方法,以减少点云的规模。在大规模点云处理中,常规的采样方法如最远点采样(Farthest Point Sampling, FPS)尽管覆盖范围广,但计算复杂度极高。相比之下,随机采样在计算效率上表现极佳,且能够很好地适应大规模点云数据。
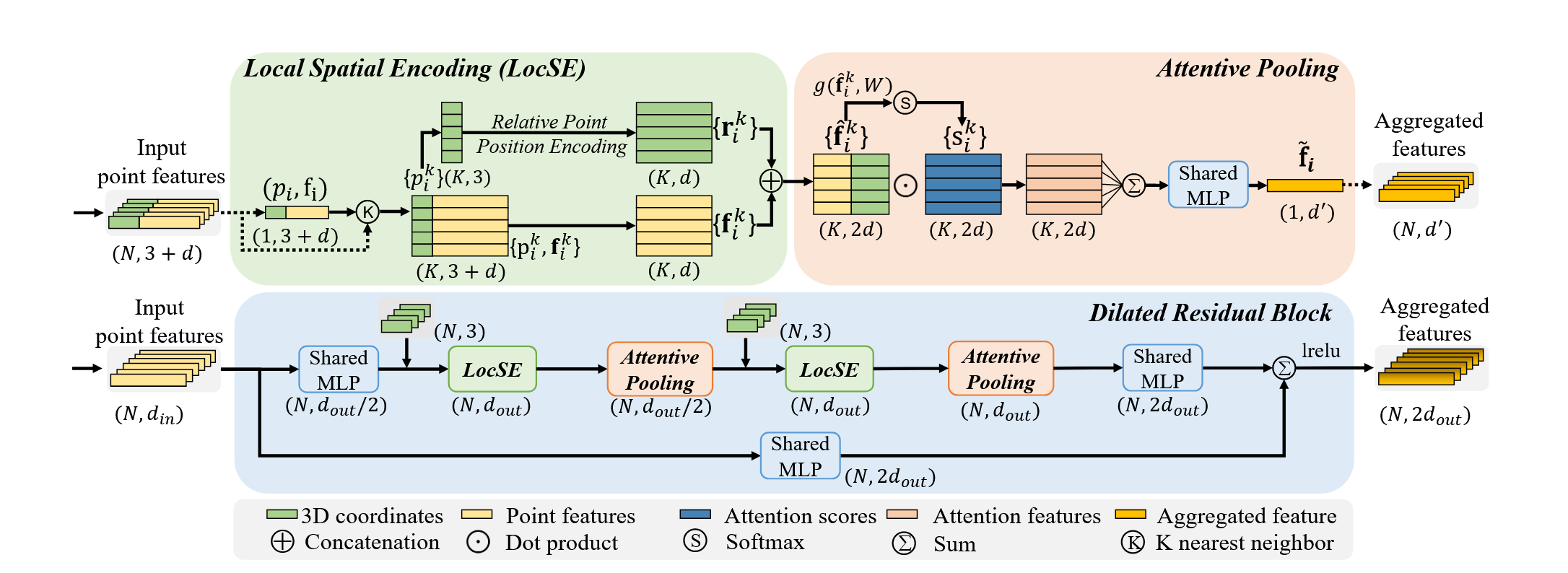
图 local feature aggregation模块。顶部面板显示了提取特征的位置空间编码块,以及基于局部上下文和几何形状对最重要的相邻特征进行加权的注意力池机制。底部面板显示了其中两个组件如何链接在一起,以增加残差块内的感受野大小。
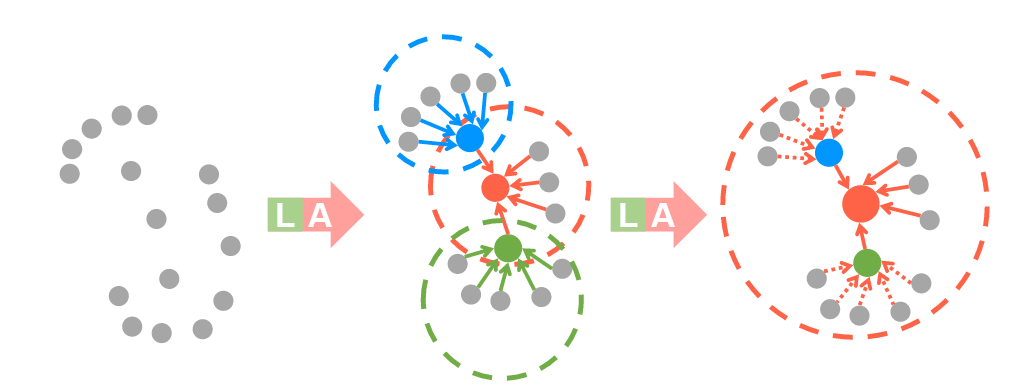
图 扩张残差块的图示,它显着增加了每个点的感受野(虚线圆圈),彩色点代表聚合特征。 L:局部空间编码,A:注意力池。
-
局部特征聚合模块(Local Feature Aggregation, LFA):为了克服随机采样可能丢失重要几何信息的缺点,RandLA-Net设计了一种新的局部特征聚合模块。该模块通过逐渐扩展每个点的感受野来有效地保留点的局部几何结构,包含三个核心步骤:
- 局部空间编码(Local Spatial Encoding, LocSE):为每个点和其邻居点进行相对位置编码,帮助网络理解局部几何结构。
- 注意力聚合(Attentive Pooling):通过注意力机制对邻居点进行加权聚合,选择对当前点语义分割最有贡献的特征。
- 膨胀残差块(Dilated Residual Block):通过堆叠多个LocSE和注意力聚合模块,增加每个点的感受野,从而有效捕获大规模点云中的复杂结构。
-
高效性和端到端处理:RandLA-Net不需要复杂的预处理或后处理步骤,如体素化(voxelization)、块分割(block partitioning)或图构建(graph construction),从而减少了计算开销,并允许在不牺牲准确性的情况下进行端到端的训练和推断。
实现步骤
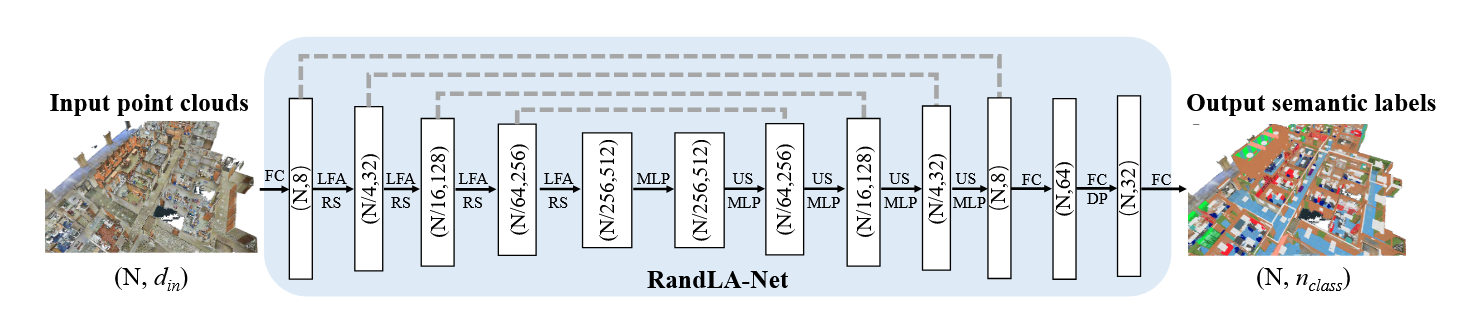
图 RandLA-Net 的详细架构。 (N,D)分别表示点数和特征维度。 FC:全连接层,LFA:局部特征聚合,RS:随机采样,MLP:共享多层感知器,US:上采样,DP:Dropout。
- 输入点云数据:输入是具有几何坐标(x, y, z)及其他特征(如颜色、反射强度等)的点云数据,通常包含百万级别的点。
- 随机采样:
- 在每一层网络中,对输入点云进行随机采样,逐步减少点的数量,同时保持核心特征。这种方法相较于其他复杂的采样方式,计算开销更小,并且能够高效地处理大规模点云。
- 局部特征聚合(LFA):
- 对于每个采样后的点,利用K-最近邻(K-Nearest Neighbors, KNN) 算法选择其邻居点。
- 局部空间编码(LocSE):为每个点的邻居点生成相对位置的编码,通过MLP(多层感知器)将点的几何信息(如点的位置、相对距离等)转换为特征向量。
- 注意力聚合(Attentive Pooling):为每个邻居点计算注意力得分,使用注意力机制加权汇总这些特征,以保留对当前点最有用的局部信息。
- 膨胀残差块(Dilated Residual Block):通过堆叠多个LocSE和注意力聚合单元,显著扩展每个点的感受野。这一模块确保即使在随机采样中丢失了一些点,网络依然能够通过邻域信息保留几何细节。
- 下采样与上采样结构:
- 采用编码-解码(Encoder-Decoder)结构。在编码阶段,逐层下采样点云数据,减少点的数量并增加特征维度。在解码阶段,利用跳跃连接(skip connections)进行特征融合,并逐步上采样,恢复每个点的语义信息。
- 输出语义标签:
- 最终,经过多层网络处理后,输出每个点的语义分类结果。RandLA-Net可以直接处理大规模点云,进行逐点的语义标签推断。
如何改进PointNet++
为了利用RandLA-Net的思想来改进PointNet++,可以结合RandLA-Net中的关键设计思想——随机采样和局部特征聚合模块,从而提高PointNet++在大规模点云处理上的效率和准确性。
结合RandLA-Net的思想,PointNet++可以通过以下方式得到改进:
- 用随机采样替换现有的最远点采样,提升采样效率。
- 引入局部特征聚合模块(LFA),增强局部几何结构的保留能力。
- 通过膨胀残差块扩展感受野,提高对大规模点云中复杂结构的建模能力。
- 简化计算操作,使用MLP-based架构优化内存和计算效率。
- 实现端到端处理,减少预处理和后处理步骤。
1. 替换采样方法
PointNet++采用的是最远点采样(Farthest Point Sampling, FPS),它的计算复杂度为(O(N^2)),处理大规模点云时非常耗时。而RandLA-Net使用的**随机采样(Random Sampling, RS)**计算复杂度为(O(1)),能够极大地降低采样过程的时间和内存开销。
- 将PointNet++中的FPS替换为随机采样(RS)。随机采样的优势在于它可以高效处理百万级别的点云数据,尽管随机采样可能会丢失一些重要点的信息,但结合后续的局部特征聚合模块可以有效弥补这一问题。
通过替换采样方式,PointNet++可以更快地处理大规模点云,显著提升其计算效率。
2. 引入局部特征聚合模块(LFA)
PointNet++的核心在于逐层提取局部特征并进行全局汇总,但是它缺乏像RandLA-Net那样的有效特征聚合机制,导致在处理复杂几何结构时效果有限。RandLA-Net的局部特征聚合模块(LFA),特别是其中的**局部空间编码(LocSE)和注意力聚合(Attentive Pooling)**机制,可以更好地捕获点云中的局部几何结构。
- 引入RandLA-Net的局部特征聚合模块。具体来说,可以在PointNet++的特征提取过程中加入RandLA-Net的局部空间编码(LocSE),为每个点编码其相对于邻居点的空间几何信息。
- 使用注意力聚合(Attentive Pooling)替换原有的特征池化方法。PointNet++中的特征聚合方式主要使用简单的最大池化(Max Pooling),这可能会丢失部分信息。引入注意力机制,可以让网络根据点的邻域信息自动选择更重要的局部特征进行聚合,提高分割精度。
3. 扩展感受野
在PointNet++中,局部特征的感受野通过层次化的点集分层逐步增大,但每层的感受野增长相对有限。RandLA-Net通过膨胀残差块(Dilated Residual Block),大幅增加了每个点的感受野,使得即使在进行随机采样后,一些被丢弃的点的局部几何信息仍能被保留。
- 在特征提取网络中使用膨胀残差块(Dilated Residual Block)。通过堆叠多个局部特征聚合模块,逐渐扩展感受野,使得PointNet++能够捕捉到更大的局部结构,从而在大规模点云中表现更好。这样做有助于增强PointNet++对复杂几何形状和稀疏区域的建模能力。
4. 优化内存和计算效率
RandLA-Net的设计不仅在于提升语义分割的准确性,同时也显著降低了对GPU内存的需求。通过随机采样和MLP(多层感知器)来替代图结构或卷积操作,RandLA-Net具备极高的计算效率。
- 简化PointNet++中的网络架构,避免复杂的计算操作。可以借鉴RandLA-Net的MLP-based架构,去掉一些计算复杂且对大规模点云处理不利的操作,例如较为耗时的图构建或卷积操作,改为使用更简单高效的共享MLP操作,从而进一步优化网络的内存和计算效率。
5. 实现端到端的大规模点云处理
RandLA-Net的另一个关键优点是它能够在无需预处理或后处理的情况下,直接处理大规模点云数据。而PointNet++需要对点云进行块分割,特别是处理大规模场景时,这一块分割步骤可能会增加计算开销且引入边界效应。
- 将PointNet++的块分割机制替换为全局处理机制。可以借鉴RandLA-Net的端到端处理策略,让网络能够直接处理完整的点云,避免对点云进行预处理(如体素化或块分割)以及后处理步骤,从而提升整体处理效率。















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









