







模型微调简介
模型微调是一种在已有预训练模型的基础上,通过使用特定任务的数据集进行进一步训练的技术。这种方法允许模型在保持其在大规模数据集上学到的通用知识的同时,适应特定任务的细微差别。使用微调模型,可以获得以下好处:
- 提高性能:微调可以显著提高模型在特定任务上的性能。
- 减少训练时间:相比于从头开始训练模型,微调通常需要较少的训练时间和计算资源。
- 适应特定领域:微调可以帮助模型更好地适应特定领域的数据和任务。
登录硅基流动
登录硅基流动:https://cloud.siliconflow.cn/fine-tune 去注册一个账号,然后进入模型微调 - 新建微调任务
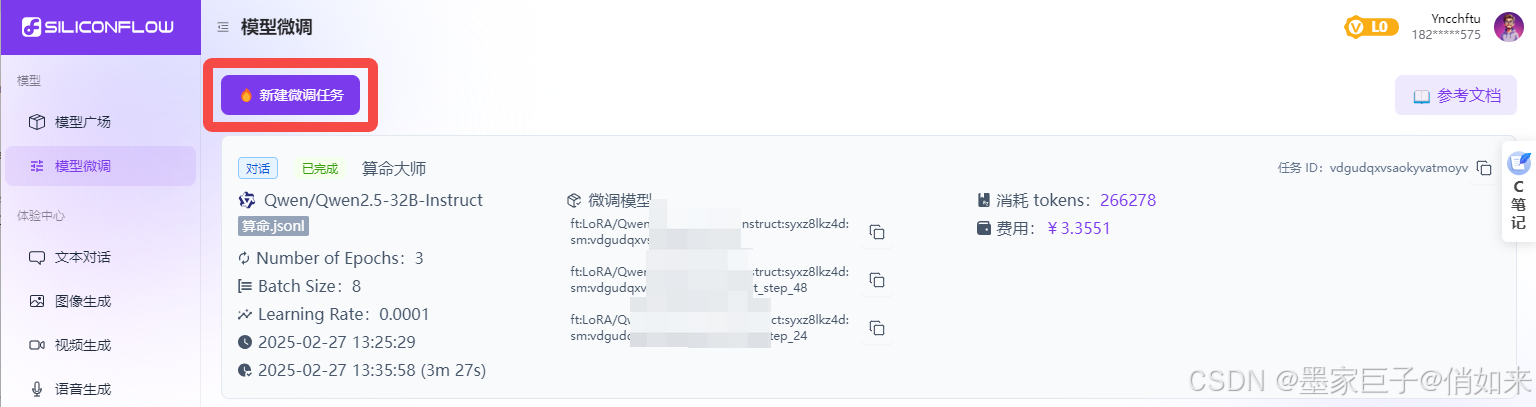
新建微调任务
选择微调模型
目前有以下模型支持微调:生图模型已支持:black-forest-labs/FLUX.1-dev对话模型已支持:
- Qwen/Qwen2.5-7B-Instruct
- Qwen/Qwen2.5-14B-Instruct
- Qwen/Qwen2.5-32B-Instruct
- Qwen/Qwen2.5-72B-Instruct
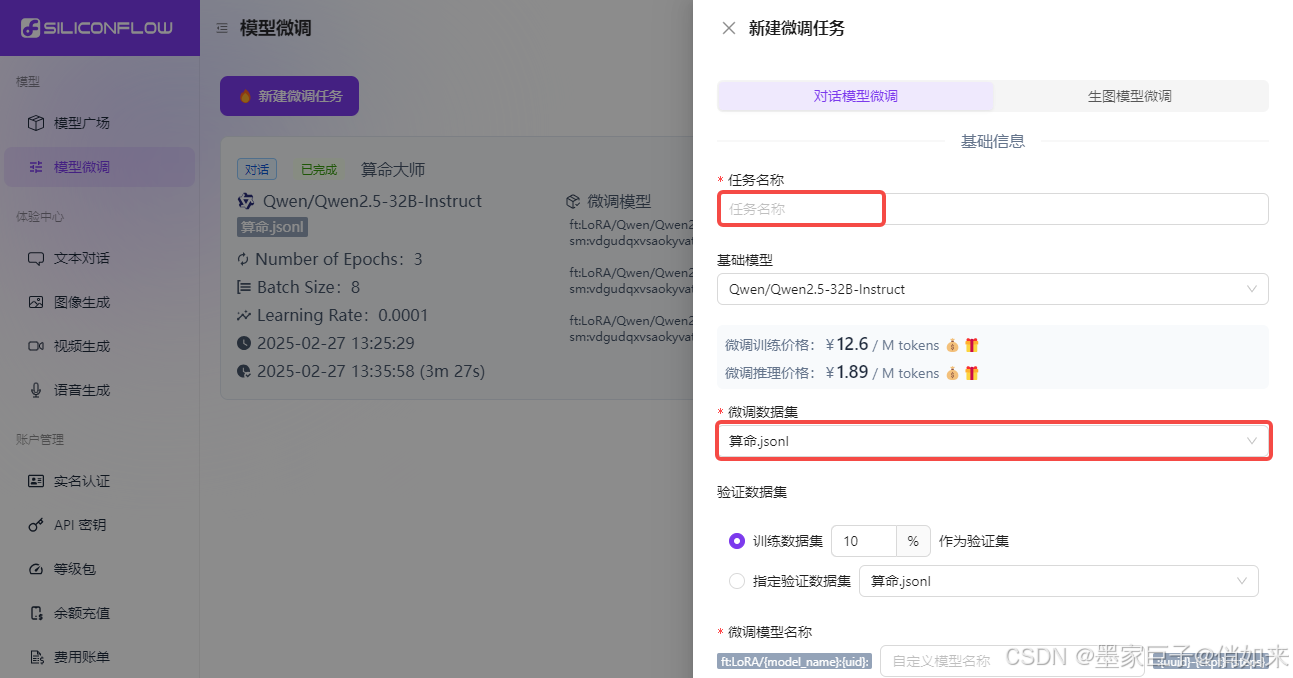
对话模型-微调数据准备
仅支持 .jsonl 文件,且需符合以下要求:
- 每行是一个独立的 JSON 对象;
- 每个对象必须包含键名为 messages 的数组,数组不能为空;
- messages 中每个元素必须包含 role 和 content 两个字段;
- role 只能是 system、user 或 assistant;
- 如果有 system 角色消息,必须在数组首位;
- 第一条非 system 消息必须是 user 角色;
- user 和 assistant 角色的消息应当交替、成对出现,不少于 1 对
数据可以自己准备,如下为数据示例:
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何修改收货地址?"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改地址'\n3. 输入新地址信息\n4. 保存修改"}]}
{"messages": [{"role": "system", "content": "你是客服助手"}, {...}]}
家练习或测试的话可以去网上找一些公开数据集,这里推荐两个可以获取公开数据集的网站:
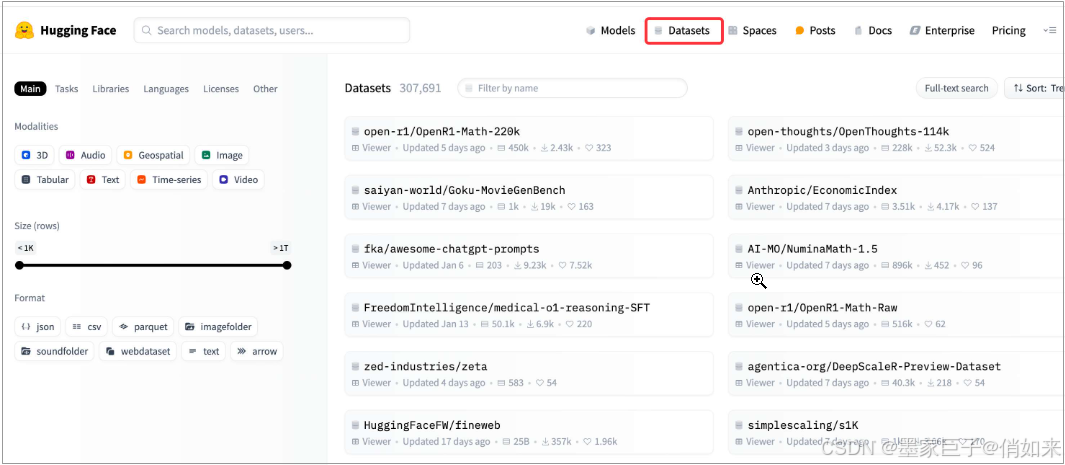
第一个:Hugging Face(🪜),我们可以把 Hugging Face 平台比作 AI 领域的 GitHub,它为开发者提供了一个集中化的平台,用于分享、获取和使用预训练模型和数据集。就像 GitHub 是代码共享和协作的中心一样,Hugging Face 是 AI 模型和数据共享的中心。在后面的实战环节中我们还会用到它:
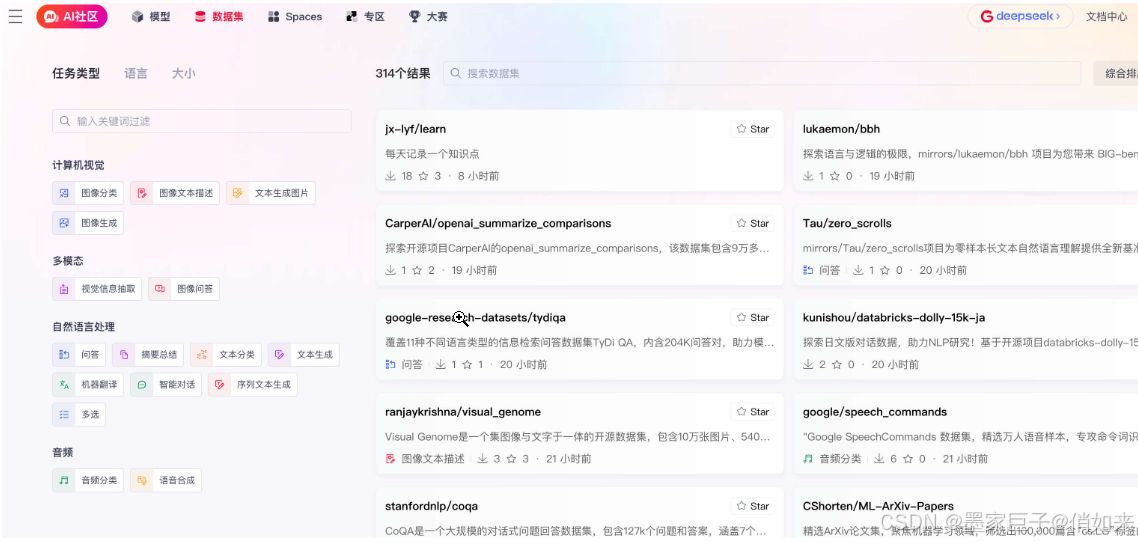
如果你没有🪜,也可以退而求其次,选择国内的一些类似社区,比如 GitCode 的 AI 社区:
微调数据我是在网上找了一份算命大师微调数据,然后使用Python格式化为上面格式
import requests
import json
# 下载JSON文件
url = "https://huggingface.co/datasets/Conard/fortune-telling/raw/main/all_details.json"
response = requests.get(url)
data = response.json()
# 转换格式
jsonl_data = []
for item in data:
question = item["Question"]
response = item["Response"]
# 构建新的JSON对象
new_item = {
"messages": [
{"role": "system", "content": "你是位精通八字算命、紫微斗数、风水、易经卦象、塔罗牌占卜、星象、面相手相和运势预测等方面的算命大师"},
{"role": "user", "content": question},
{"role": "assistant", "content": response}
]
}
# 将新的JSON对象转换为JSONL格式(每行一个JSON对象)
jsonl_data.append(json.dumps(new_item, ensure_ascii=False))
# 将JSONL数据写入文件
with open("output.jsonl", "w", encoding="utf-8") as f:
for line in jsonl_data:
f.write(line + "\n")
print("转换完成,结果已保存到 output.jsonl 文件中。")
没有Python环境的去Python官网下载安装,然后在IDEA中安装一个Python插件即可使用。或者也可以安装VS Code安装Python插件使用。
微调参数设置
其他的参数使用默认的也可以,下面是配置参考:
| 参数名 | 说明 | 取值范围 | 建议值 | 使用建议 |
|---|---|---|---|---|
| Trigger Word | 【仅生图】触发词 | 训练时会被添加到每张图片的描述内容的开头 | ||
| Number of Repeats | 【仅生图】单张图片重复训练次数 | |||
| Learning Rate | 学习速率 | 0-0.1 | 0.0001 | |
| Number of Epochs | 训练轮数 | 1-10 | 3 | |
| Batch Size | 批次大小 | 1-32 | 8 | |
| Max Tokens | 最大标记数 | 0-4096 | 4096 | 根据实际对话长度需求设置 |
- 学习率解释:想象你已经学会了骑自行车(相当于预训练模型),现在要学习骑摩托车(新任务)。学习骑摩托车时,你不需要从头开始学平衡和操控,只需要在骑自行车的基础上做一些小调整,学习率就是你调整的幅度:
- 如果调整太大(学习率过大),可能会忘记怎么骑自行车,甚至摔倒。
- 如果调整太小(学习率过小),学骑摩托车的速度会很慢。
- 如果调整得刚刚好(合适的学习率),你就能快速学会骑摩托车,同时不会忘记怎么骑自行车
- 训练轮数 :好理解,就是进行几轮训练(反复练习)
- 批次大小 :一次训练的数据条数,也就是同时处理的样本数,批次太大比较耗硬件,批次太小训练会比较慢。如果 GPU 内存较大,可以选择较大的批次大小,以加快训练速度。如果 GPU 内存较小,可以选择较小的批次大小,避免内存不足
官方建议配置
| 场景 | Learning Rate | Epochs | Batch Size | LoRA Rank | LoRA Alpha | Dropout |
|---|---|---|---|---|---|---|
| 标准方案 | 0.0001 | 3 | 8 | 8 | 32 | 0.05 |
| 效果优先 | 0.0001 | 5 | 16 | 16 | 64 | 0.1 |
| 轻量快速 | 0.0001 | 2 | 8 | 4 | 16 | 0.05 |
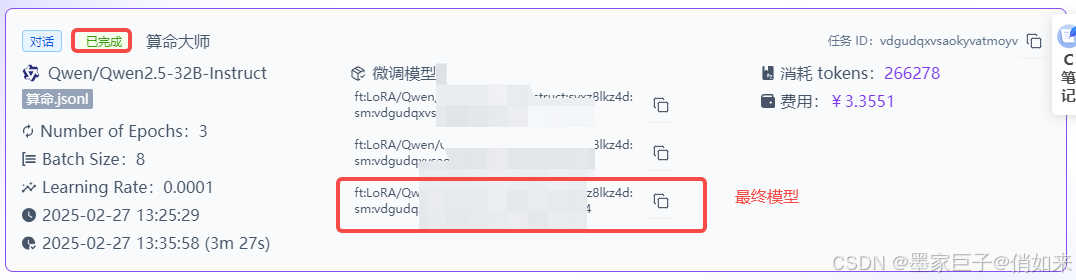
保存之后就耐心等待模型训练完成,短则几分钟,长则几天,就看排队情况,训练好之后可以看到消耗的tokens和费用。然后赋值好最终模型ID
调用模型
模型训练好之后我们就可以通过代码调用模型了,下面是基于 OpenAI的chat.completions 接口访问微调后模型的例子:
from openai import OpenAI
client = OpenAI(
api_key="", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "房间挂什么画最旺运?有什么讲究?"},
]
response = client.chat.completions.create(
model="你自己训练的最终模型",
messages=messages,
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
- api_key : 需要在API秘钥中去创阿金
- model :你训练好的模型,最后一个模型ID,如上图
写到最后
使用硅基流动进行模型微调确实是比较方便的,但是也有几点不足之处,一是要给钱,二是耗时长,三是可选的模型比较少。下面我们我们将介绍另一种微调方式弥补这些不足。
文章就先写到这里,如果对你有帮助请好评!!!


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











