








 超级会员免费看
超级会员免费看

 本文详细分析了Transformer计算复杂度,重点探讨了自注意力机制的计算过程,包括矩阵计算、注意力矩阵归一化和加权求和。针对自注意力层的高计算复杂度,提出了稀疏化和线性化两种改进策略,介绍了包括Sparse Transformer、Reformer、Linformer等在内的多种优化方法,旨在降低长序列处理时的计算成本。
本文详细分析了Transformer计算复杂度,重点探讨了自注意力机制的计算过程,包括矩阵计算、注意力矩阵归一化和加权求和。针对自注意力层的高计算复杂度,提出了稀疏化和线性化两种改进策略,介绍了包括Sparse Transformer、Reformer、Linformer等在内的多种优化方法,旨在降低长序列处理时的计算成本。
文章目录
如何降低Transformer的计算复杂度
Efficient Transformers.
本文目录:
- Transformer的计算复杂度
- 改进自注意力机制
1. Transformer的计算复杂度
(1) Transformer的典型结构
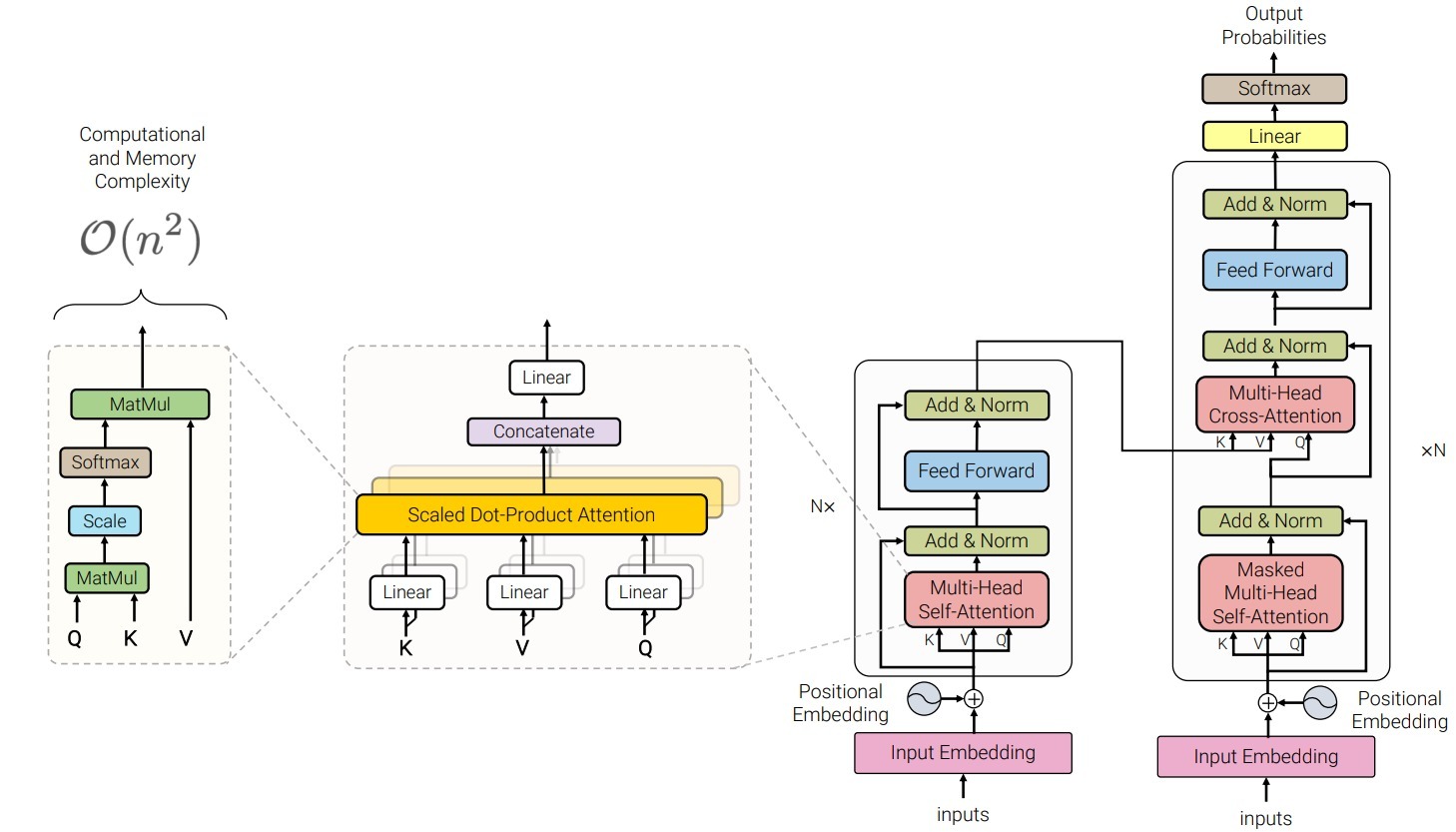
典型的Transformer结构如上图所示,其整体计算量来源于模型中的自注意力层和全连接层两部分,本文主要讨论自注意力层的改进。
(2) 自注意力机制的运算
由于计算机中乘法的计算速度比加法慢,因此在衡量计算复杂度时主要考虑乘法。对于矩阵乘法
Efficient Transformers.
本文目录:
典型的Transformer结构如上图所示,其整体计算量来源于模型中的自注意力层和全连接层两部分,本文主要讨论自注意力层的改进。
由于计算机中乘法的计算速度比加法慢,因此在衡量计算复杂度时主要考虑乘法。对于矩阵乘法
 1112
492
992
1112
492
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























