








 超级会员免费看
超级会员免费看

 混合专家模型(MoE)通过组合多个专家网络处理大规模数据集上的复杂任务,提高模型的泛化能力。文章介绍了MoE的基本结构,包括门控网络(Softmax和Gating Tree)和专家网络(前馈神经网络和卷积神经网络),并讨论了MoE的训练过程。此外,还提供了使用PyTorch实现MoE模型的代码示例。
混合专家模型(MoE)通过组合多个专家网络处理大规模数据集上的复杂任务,提高模型的泛化能力。文章介绍了MoE的基本结构,包括门控网络(Softmax和Gating Tree)和专家网络(前馈神经网络和卷积神经网络),并讨论了MoE的训练过程。此外,还提供了使用PyTorch实现MoE模型的代码示例。
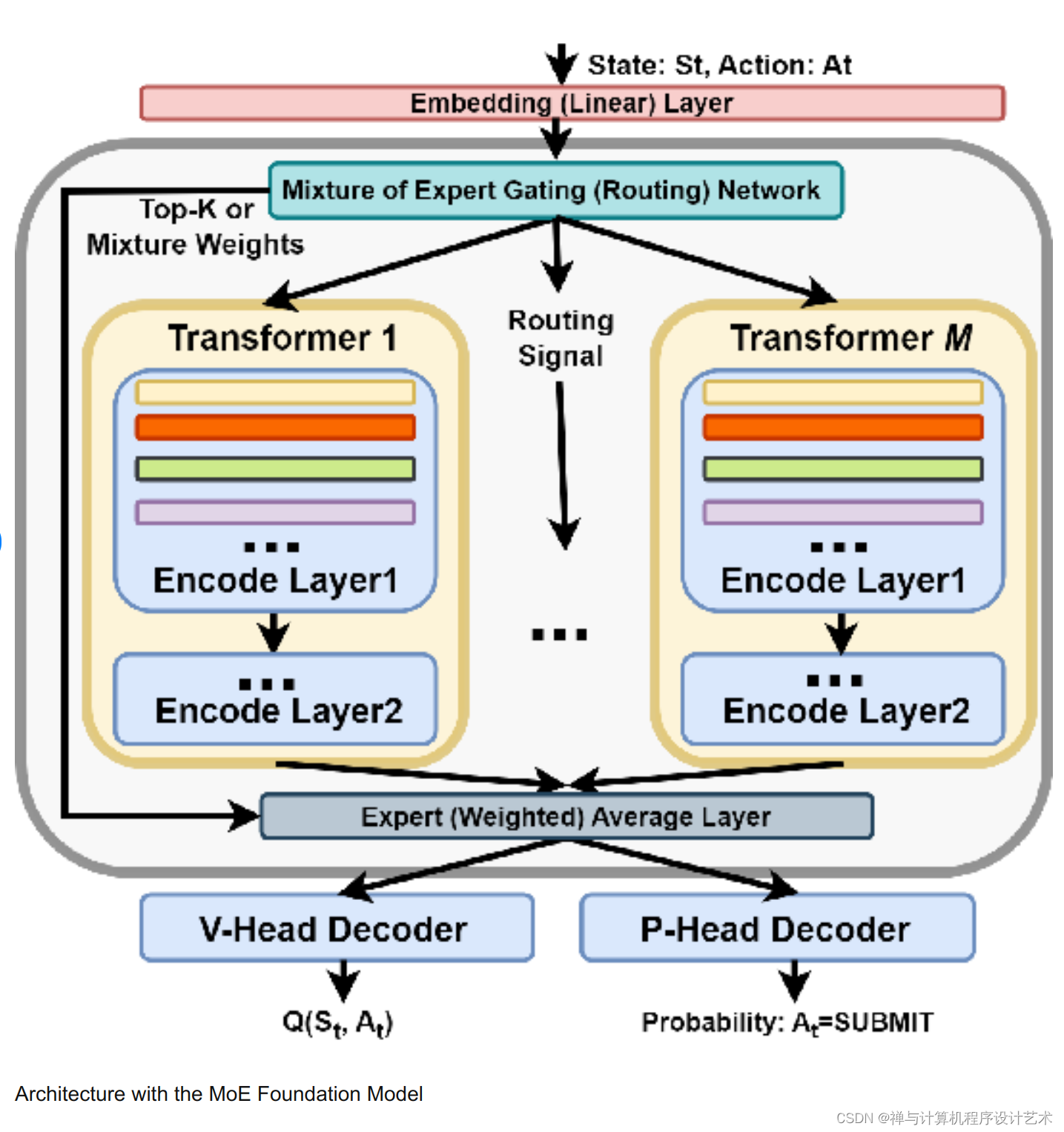
混合专家模型(Mixture of Experts, MoE)是一种用于解决大规模数据集上的复杂任务的神经网络模型。它可以自适应地组合多个专家网络来处理不同的数据子集,从而提高模型的泛化能力和性能。本文将对MoE模型的原理进行讲解,包括其数学公式和代码实现。
一、MoE模型原理
1.1 基本结构
MoE模型由两部分组成:门控网络和专家网络。门控网络用于选择哪个专家网络处理输入数据,而每个专家网络负责处理相应的数据子集。
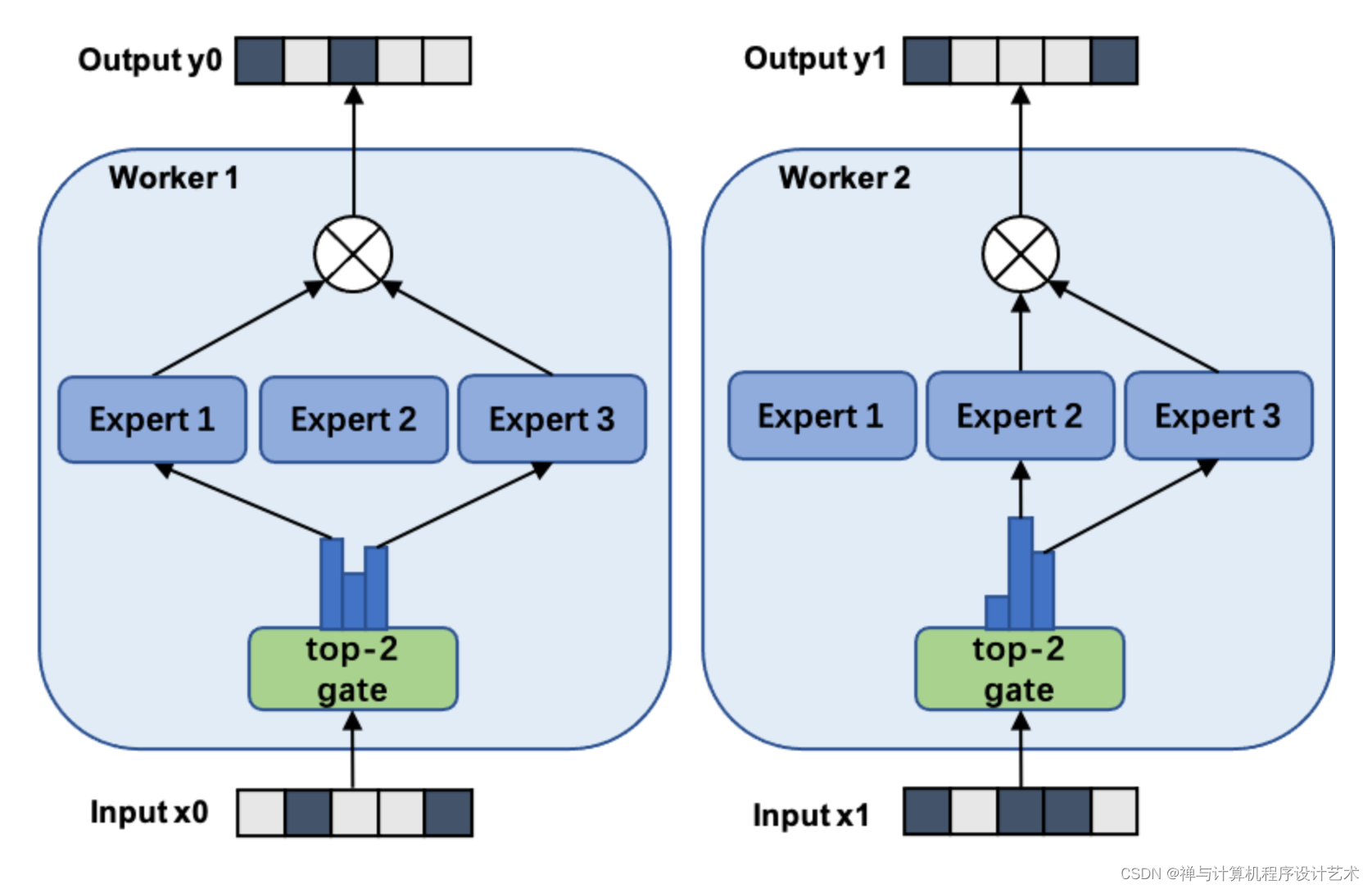
下图展示了一个有三个专家的两路数据并行MoE模型进行前向计算的方式.
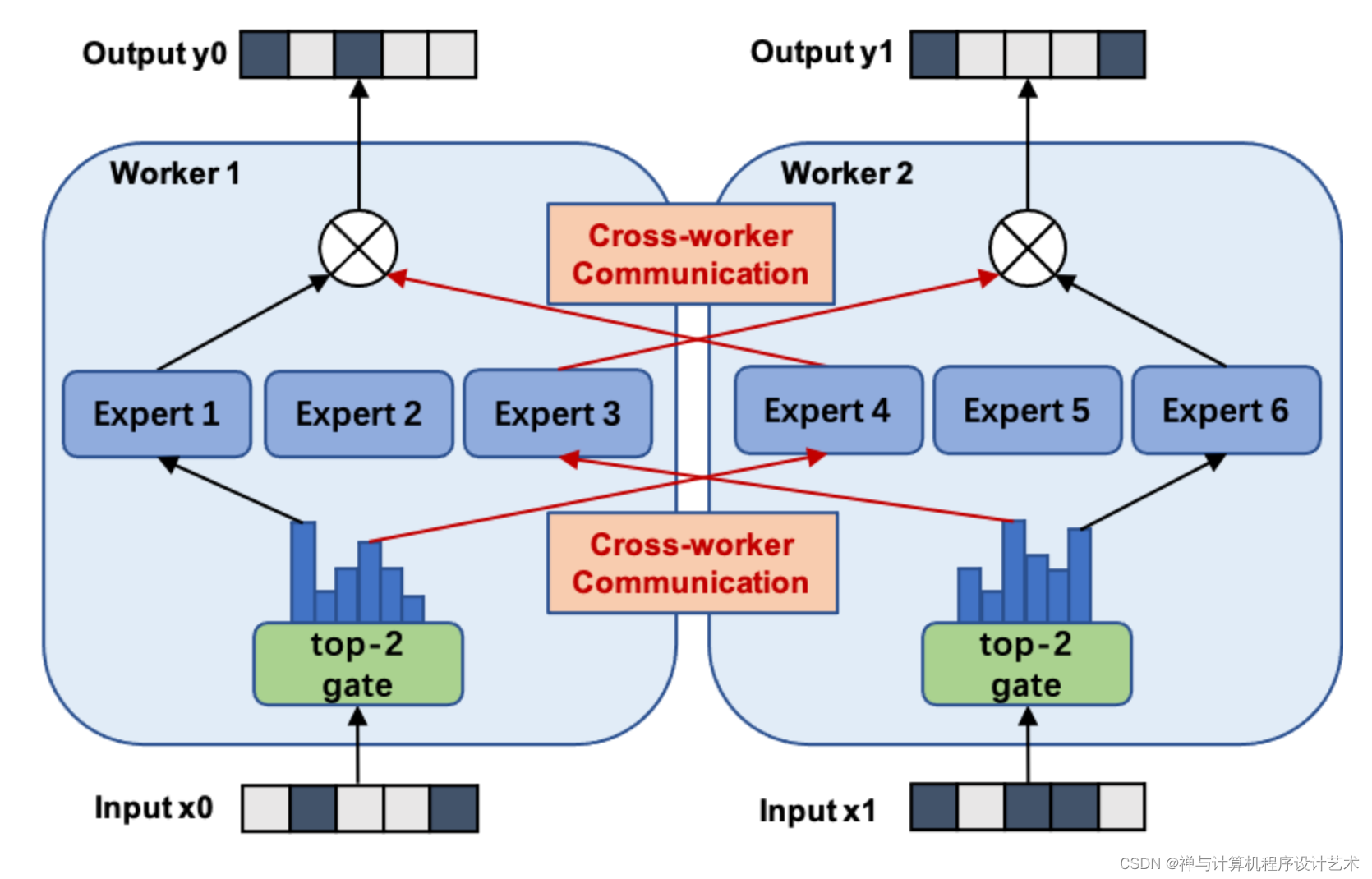
下图展示了一个有六个专家网络的模型被两路模型并行地训练.
注意专家1-3被放置在第一个计算单元上, 而专家4-6被放置在第二个计算单元上.

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











