





注意力机制
注意 (Note)
In this article I have discussed the various types of activation functions and what are the types of problems one might encounter while using each of them.
在本文中,我讨论了各种激活函数,以及在使用每种激活函数时可能遇到的问题类型。
I would suggest to begin with a ReLU function and explore other functions as you move further. You can also design your own activation functions giving a non-linearity component to your network.
我建议从ReLU功能开始,并在您进一步开发其他功能时进行探索。 您还可以设计自己的激活函数,为网络提供非线性组件。
Recall that inputs x0,x1,x2,x3……xn and weights w0,w1,w2,w3……..wn are multiplied and added with bias term to form our input.
回想一下,输入x0,x1,x2,x3……xn和权重w0,w1,w2,w3…….wn被相乘并加上偏置项以形成我们的输入。

Clearly W implies how much weight or strength we want to give our incoming input and we can think b as an offset value, making x*w have to reach an offset value before having an effect.
显然, W表示我们要给输入的输入多少重量或强度,我们可以将b视为偏移值,从而使x * w必须先达到偏移值才能生效。
到目前为止,我们已经看到了输入,那么什么是激活函数? (As far we have seen the inputs so now what is activation function?)
Activation function is used to set the boundaries for the overall output value.For Example:-let z=X*w+b be the output of the previous layer then it will be sent to the activation function for limit it’svalue between 0 and 1(if binary classification problem).
激活函数用于设置总输出值的边界,例如:-let z = X * w + b是上一层的输出,然后将其发送到激活函数以将其值限制在0到0之间。 1(如果二进制分类问题)。
Finally, the output from the activation function moves to the next hidden layer and the same process is repeated. This forward movement of information is known as the forward propagation.
最后,激活函数的输出移至下一个隐藏层,并重复相同的过程。 信息的这种前向移动称为前向传播 。
What if the output generated is far away from the actual value? Using the output from the forward propagation, error is calculated. Based on this error value, the weights and biases of the neurons are updated. This process is known as back-propagation.
如果生成的输出与实际值相去甚远怎么办? 使用前向传播的输出,可以计算误差。 基于此误差值,将更新神经元的权重和偏差。 此过程称为反向传播 。
A neural network without an activation function is essentially just a linear regression model.
没有激活函数的神经网络实质上只是线性回归模型。
一些激活功能 (Some Activation Functions)
Step Function
步进功能

if value of z<0,output=0,if value of z>0,output=1This sort of function is for classification however this activation function is less used because this is very strong function as the small changes are not reflected.
此类功能用于分类,但是此激活功能使用较少,因为由于未反映出较小的变化,因此此功能非常强大 。
2. Sigmoid Function
2.乙状结肠功能
The next activation function that we are going to look at is the Sigmoid function. It is one of the most widely used non-linear activation function. Sigmoid transforms the values between the range 0 and 1.
我们要看的下一个激活函数是Sigmoid函数。 它是使用最广泛的非线性激活函数之一。 Sigmoid转换0到1之间的值。

- A noteworthy point here is that unlike the binary step and linear functions, sigmoid is a non-linear function. This essentially means -when I have multiple neurons having sigmoid function as their activation function,the output is non linear as well. 这里值得注意的一点是,与二值阶跃函数和线性函数不同,Sigmoid是非线性函数。 这本质上意味着-当我有多个具有S型功能作为激活功能的神经元时,输出也是非线性的。
3.Hyperbolic Tangent(tanh(z))
3.双曲正切(tanh(z))

The tanh function is very similar to the sigmoid function. The only difference is that it is symmetric around the origin. The range of values in this case is from -1 to 1. Thus the inputs to the next layers will not always be of the same sign.
tanh函数与S型函数非常相似。 唯一的区别是它围绕原点对称。 在这种情况下,值的范围是-1至1 。 因此,下一层的输入将不会总是具有相同的符号。
4. Rectified Linear Unit(Relu)
4.整流线性单元(Relu)

This is actually a relative simple funcion max(0,z).
这实际上是一个相对简单的函数max(0,z)。

def relu_function(x):
if x<0:
return 0
else:
return xRelu has been found to have very good performance ,especially when dealing with the issue of Vanishing Gradient.
人们发现Relu的性能非常好,尤其是在处理“ 消失梯度 ”问题时。
5. Leaky Rectified Linear Unit
5.泄漏线性整流器
Leaky ReLU function is nothing but an improved version of the ReLU function. As we saw that for the ReLU function, the gradient is 0 for x<0, which would deactivate the neurons in that region.
泄漏的ReLU功能不过是ReLU功能的改进版本。 如我们所见,对于ReLU函数,对于x <0,梯度为0,这将使该区域的神经元失活。
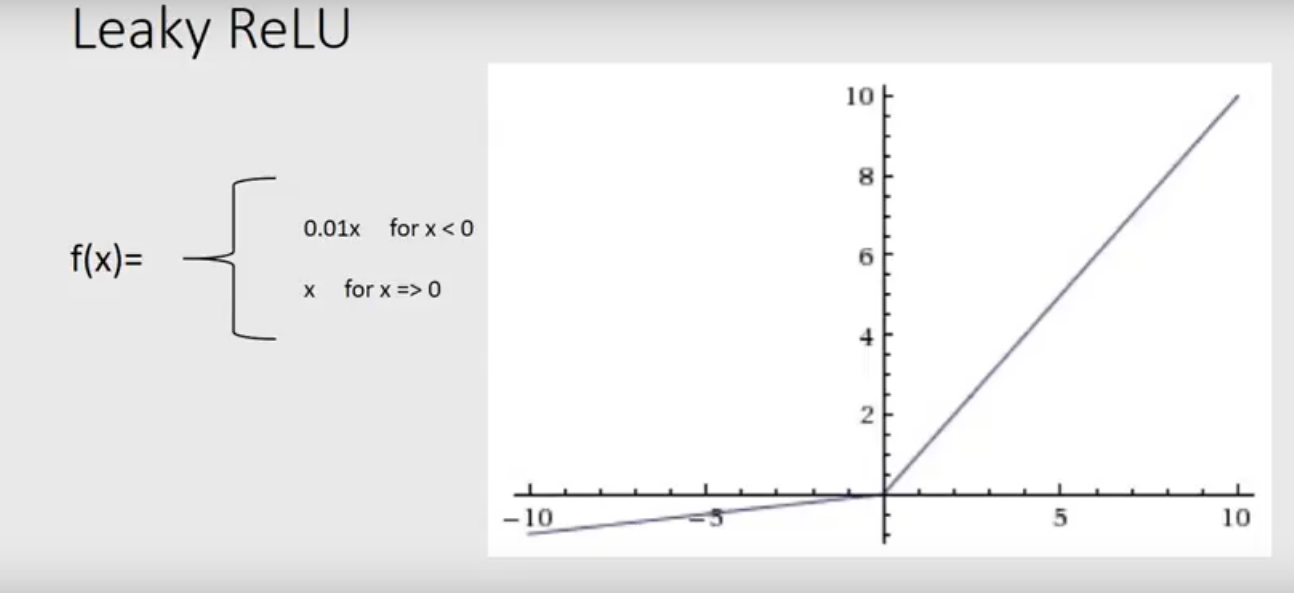
Leaky ReLU is defined to address this problem. Instead of defining the Relu function as 0 for negative values of x, we define it as an extremely small linear component of x. Here is the mathematical expression-
泄漏的ReLU被定义为解决此问题。 对于x的负值,我们没有将Relu函数定义为0,而是将其定义为x的非常小的线性分量。 这是数学表达式-
f(x)={ 0.01x, x<0
x, x>=0}6.Softmax Function
6.Softmax功能
Softmax function is often described as a combination of multiple sigmoids. We know that sigmoid returns values between 0 and 1, which can be treated as probabilities of a data point belonging to a particular class. Thus sigmoid is widely used for binary classification problems.
Softmax函数通常被描述为多个S型曲线的组合。 我们知道sigmoid返回的值介于0和1之间,可以将其视为属于特定类的数据点的概率。 因此,乙状结肠被广泛用于二进制分类问题。

- Softamax function calculates the probablities distribution of the event over k different events. Softamax函数计算k个不同事件上事件的概率分布。
- So,this means this function will calculate the probablities of each target over all possible targets. 因此,这意味着此函数将计算所有可能目标上每个目标的概率。
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_选择正确的激活功能 (Choosing the right Activation Function)
Now that we have seen so many activation functions, we need some logic / heuristics to know which activation function should be used in which situation. Good or bad — there is no rule of thumb.
现在我们已经看到了这么多的激活函数,我们需要一些逻辑/试探法来知道在哪种情况下应该使用哪个激活函数。 好与坏-没有经验法则。
However depending upon the properties of the problem we might be able to make a better choice for easy and quicker convergence of the network.
但是,根据问题的性质,我们可能能够做出更好的选择,以实现网络的轻松,快速融合。
- Sigmoid functions and their combinations generally work better in the case of classifiers 在分类器的情况下,Sigmoid函数及其组合通常效果更好
- Sigmoids and tanh functions are sometimes avoided due to the vanishing gradient problem 由于逐渐消失的梯度问题,有时会避免出现S型和tanh函数
- ReLU function is a general activation function and is used in most cases these days ReLU功能是一种常规的激活功能,目前在大多数情况下都使用
- If we encounter a case of dead neurons in our networks the leaky ReLU function is the best choice 如果我们在网络中遇到死亡的神经元的情况,则漏液的ReLU功能是最佳选择
- Always keep in mind that ReLU function should only be used in the hidden layers 始终牢记ReLU功能只能在隐藏层中使用
- As a rule of thumb, you can begin with using ReLU function and then move over to other activation functions in case ReLU doesn’t provide with optimum results. 根据经验,您可以先使用ReLU功能,然后再转到其他激活功能,以防ReLU无法提供最佳效果。
注意力机制















 4715
4715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









