







为什么 bulk RNA-seq 差异表达在单细胞世界中不是最有用的?

试图找出哪些基因在不同条件下“不同”,这可能是任何人想要进行 bulk RNA-seq 实验的第一件事。
当我们说“不同”时,实际上是指哪些基因在表达上的差异大于随机统计波动所预期的差异。这种变化的大小通常表示为条件之间标准化表达值的对数倍变化,并且统计波动采用负二项式分布进行参数化。用于处理 bulk RNA-seq(例如 edgeR 或 DESeq2 )的工具非常强大且成熟。
因此,当单细胞 RNA-seq 出现时,能将相同的想法应用于新环境。当然,也有许多尝试使用不同的统计分布和假设来更好地适应单细胞数据的属性。快速浏览一下谷歌就会发现,有足够多的相互竞争的方法可以保证至少有一篇基准论文。
作者认为匆忙为单细胞“更好”做差异表达而忽略的一件事是,被问到的生物学问题有细微的差别。或更确切地说,我们作为科学家最关心的结果并不是那些为批量数据开发的工具所激发的传统方法所强调的结果。
bulk RNA-seq 实验中差异表达的基因代表条件之间大细胞聚集体中总表达水平的变化。因此,条件之间的表达倍增是重要且有意义的,因为它告诉我,在一种条件下表达基因 A 的细胞大约是另一种条件下表达基因 A 的细胞的两倍。对于单细胞“差异表达”,大多数时候我真正想知道的是哪些基因在一组细胞中表达,而在其他任何地方都没有。
假设我正在将肿瘤细胞与周围的正常组织进行比较。一个基因 A 在每个肿瘤细胞中大约有 3 个拷贝,在周围的内皮细胞中大约有 1 个拷贝,这有点含糊而有趣。但是您不能针对一种药物,也不能通过免疫组化或 smFISH 进行很好的验证为“高表达”。真正想要找到的是像 CA9 这样的基因,它们在肾癌细胞中表达,而不在其他细胞中表达。
为了说明这一点,作者下载了 10X PBMC数据 具有包含注释和 tSNE 坐标 SoupX。
library(Matrix)
#Load PBMC data and make barcodes consistent with SoupX annotation
dat = readMM('filtered_gene_bc_matrices/GRCh38/matrix.mtx')
rownames(dat) = read.table('filtered_gene_bc_matrices/GRCh38/genes.tsv',sep='\t',header=FALSE)$V2
colnames(dat) = read.table('filtered_gene_bc_matrices/GRCh38/barcodes.tsv',sep='\t',header=FALSE)$V1
colnames(dat) = gsub('-1','',colnames(dat))
#Load tSNE co-ordinates and clustering recorded in SoupX
library(SoupX)
data(PBMC_DR)
B细胞是簇 4 和 7 。使用 edgeR 查找与其余细胞相比 DE 的基因。这基本上只是快速入门 edgeR 分析,但是我们prior.df=0 之所以设置是因为我们有大量信息来计算过度分散,而无需在基因之间共享信息。
library(edgeR)
dge = DGEList(as.matrix(dat),group=ifelse(PBMC_DR$Cluster %in% c(4,7),'B','Other'))
mm = model.matrix(~group,data=dge$samples)
dge = estimateDisp(dge,mm,prior.df=0)
fit = glmQLFit(dge,mm)
fit = glmQLFTest(fit,coef=2)
tt = topTags(fit,n=20)
print(tt)
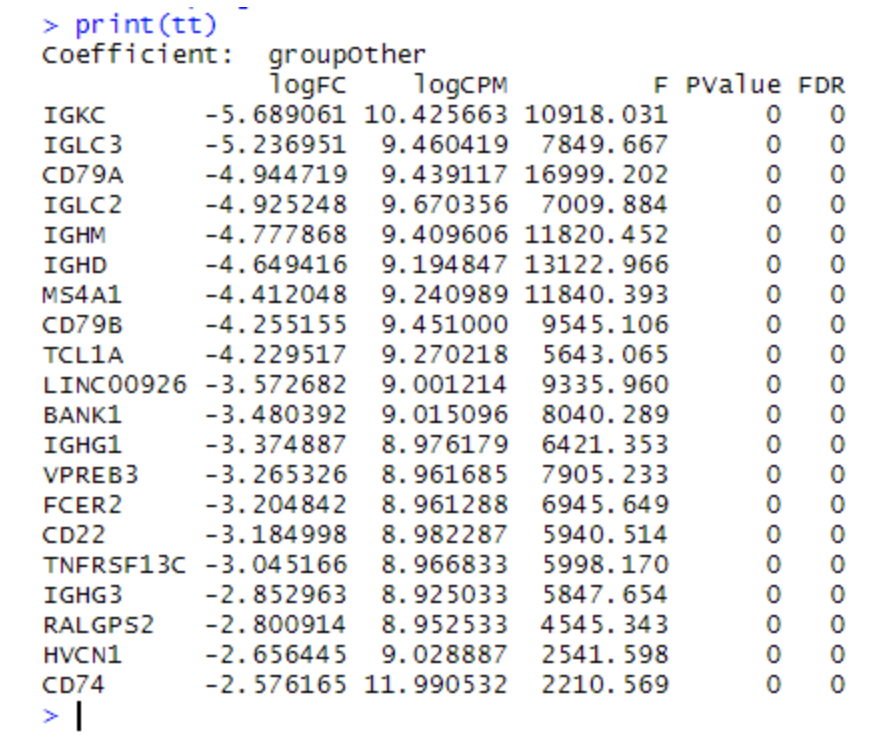
这些基因大多数被认为对B细胞非常特异,可以作为良好的标记物。可能应该选择一种不太明显的细胞类型来说明这一点。一个确实能说明作者观点的基因是 CD74 。如果我们绘制 CD74 的表达,我们会看到 CD74 在B细胞中最高(右下图),但它通常无处不在。这些是真正差异表达的基因,不一定很有趣。
normDat = log(1+1e4*t(t(dat)/colSums(dat)))
dd = PBMC_DR
dd$CD74 = normDat['CD74',]
library(ggplot2)
ggplot(dd,aes(RD1,RD2)) +
geom_point(aes(colour=ifelse(CD74>5,5,CD74))) +
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8375
8375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









